Asm
参考链接
汇编语言 教程 | 参考手册 (cankaoshouce.com)
GCC-Inline-Assembly-HOWTO — GCC-Inline-Assembly-HOWTO
译:GCC内联汇编入门 - 简书 (jianshu.com)
Arm A-profile A32/T32 Instruction Set Architecture
基础知识
引言
我们知道,CPU 只负责计算,本身不具备智能。你输入一条指令(instruction),它就运行一次,然后停下来,等待下一条指令。
这些指令都是二进制的,称为操作码(opcode),比如加法指令就是00000011。编译器的作用,就是将高级语言写好的程序,翻译成一条条操作码。
对于人类来说,二进制程序是不可读的,根本看不出来机器干了什么。为了解决可读性的问题,以及偶尔的编辑需求,就诞生了汇编语言。
汇编语言是二进制指令的文本形式,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,所以它是最底层的低级语言。
[!important]
以下教程开发环境为NAsm,使用Inte格式。
NASM 更适合跨平台、轻量级的汇编开发,语法简洁,灵活性高。
MASM 则更适合 Windows 平台上的专业开发,功能丰富,语法较复杂,集成度高,适合开发大规模的 Windows 应用程序和驱动。
[!TIP]
汇编语法主要有两大派系:AT&T语法 和 Intel语法。
GAS (GNU Assembler) 编译器默认是基于AT&T语法;MASM、NASM等编译器默认基于Intel语法。
需要说明的是,GAS汇编器除了支持AT&T语法之外,自己也定义了一些额外的
directives,用于辅助完成汇编操作。关于GAS汇编器及其语法可以参考GAS的官方文档:https://sourceware.org/binutils/docs/as/
寄存器
CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。
[!TIP]
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
早期的 x86 CPU 只有8个寄存器,而且每个都有不同的用途。现在的寄存器已经有100多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。
处理器寄存器
IA-32 体系结构中有 10 个32 位和 6个16 位处理器寄存器。
寄存器分为三类:
- 通用寄存器
- 数据寄存器
- 指针寄存器
- 索引寄存器
- 数据寄存器
- 控制寄存器
- 段寄存器
数据寄存器
4 个 32 位数据寄存器用于算术、逻辑和其他操作。这些 32 位寄存器可以用 3 种方式使用:
- 作为完整的 32 位数据寄存器:EAX、EBX、ECX、EDX。
- 32 位寄存器的下半部分可以用作 4 个 16 位数据寄存器:AX、BX、CX 和 DX。
- 上述四个 16 位寄存器的下半部和上半部可以用作八个 8 位数据寄存器:AH、AL、BH、BL、CH、CL、DH和DL。

其中一些数据寄存器在算术运算中有特定用途。
- AX 是主要的累加器; 它用于输入/输出和大多数算术指令。例如,在乘法运算中,根据操作数的大小,将一个操作数存储在 EAX 或 AX 或 AL 寄存器中。
- BX 称为基址寄存器,因为它可以用于索引寻址。
- CX 称为计数寄存器,因为 ECX,CX 寄存器在迭代操作中存储循环计数。
- DX 称为数据寄存器。它也用于输入/输出操作。它还与 AX 寄存器以及 DX 一起使用,用于涉及大数值的乘法和除法运算。
指针寄存器
指针寄存器是 32 位 EIP,ESP 和 EBP 寄存器以及相应的 16 位右部分 IP,SP 和 BP。
指针寄存器分为三类:
- 指令指针(IP) -16 位 IP 寄存器存储要执行的下一条指令的偏移地址。与 CS 寄存器关联的 IP(作为 CS:IP)给出了代码段中当前指令的完整地址。
- 堆栈指针(SP) -16 位 SP 寄存器提供程序堆栈内的偏移值。与 SS 寄存器(SS:SP)关联的 SP 是指程序堆栈中数据或地址的当前位置。
- 基本指针(BP) -16 位 BP 寄存器主要帮助参考传递给子例程的参数变量。SS 寄存器中的地址与 BP 中的偏移量相结合,以获取参数的位置。BP 也可以与 DI 和 SI 组合用作特殊寻址的基址寄存器。

索引寄存器
32 位索引寄存器 ESI 和 EDI 及其最右边的 16 位部分。SI 和 DI 用于索引寻址,有时用于加法和减法。
索引指针分为两种:
- 源索引(SI) -用作字符串操作的源索引。
- 目标索引(DI) -用作字符串操作的目标索引。

控制寄存器
将 32 位指令指针寄存器和 32 位标志寄存器组合起来视为控制寄存器。许多指令涉及比较和数学计算,并更改标志的状态,而其他一些条件指令则测试这些状态标志的值,以将控制流带到其他位置。
通用标志位是:
- 溢出标志(OF):指示有符号算术运算后数据的高阶位(最左位)的溢出。
- 方向标记(DF):它确定向左或向右移动或比较字符串数据的方向。DF 值为 0 时,字符串操作为从左至右的方向;当 DF 值为 1 时,字符串操作为从右至左的方向。
- 中断标志(IF):确定是否忽略或处理外部中断(例如键盘输入等)。当值为 0 时,它禁用外部中断,而当值为 1 时,它使能中断。
- 陷阱标志(TF):允许在单步模式下设置处理器的操作。我们使用的
DEBUG程序设置了陷阱标志,因此我们可以一次逐步执行一条指令。 - 符号标志(SF):显示算术运算结果的符号。根据算术运算后数据项的符号设置此标志。该符号由最左位的高位指示。正结果将 SF 的值清除为 0,负结果将其设置为 1。
- 零标志(ZF):指示算术或比较运算的结果。非零结果将零标志清零,零结果将其清零。
- 辅助进位标志(AF):包含经过算术运算后从位 3 到位 4 的进位;用于专业算术。当1字节算术运算引起从第 3 位到第 4 位的进位时,将设置 AF。
- 奇偶校验标志(PF):指示从算术运算获得的结果中 1 位的总数。偶数个 1 位将奇偶校验标志清为 0,奇数个 1 位将奇偶校验标志清为 1。
- 进位标志(CF):在算术运算后,它包含一个高位(最左边)的 0 或 1 进位。它还存储移位或旋转操作的最后一位的内容。
| 标志 | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 位号 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
段寄存器
段是程序中定义的特定区域,用于包含数据,代码和堆栈。有 3 个主要部分:
- 代码段:它包含所有要执行的指令。16 位代码段寄存器或 CS 寄存器存储代码段的起始地址。
- 数据段:它包含数据,常量和工作区。16 位数据段寄存器或 DS 寄存器存储数据段的起始地址。
- 堆栈段:它包含数据或过程或子例程的返回地址。它被实现为 “堆栈” 数据结构。堆栈段寄存器或 SS 寄存器存储堆栈的起始地址。
除了 DS,CS 和 SS 寄存器外,还有其他段寄存器 - ES(额外段),FS 和 GS,它们提供了用于存储数据的其他段。在汇编语言中,程序需要访问存储器位置。段中的所有存储位置都相对于段的起始地址。段的起始地址可以是 16 或十六进制的整数,因此,所有此类存储地址中最右边的十六进制数字为 0,通常不存储在段寄存器中。
段寄存器存储段的起始地址。为了获得数据或指令在段中的确切位置,需要一个偏移值(或位移)。为了引用段中的任何存储位置,处理器将段寄存器中的段地址与该位置的偏移值进行组合。
栗子:
1 | section .text |
[!tIP]
我们常常看到 32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
堆(Heap)
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
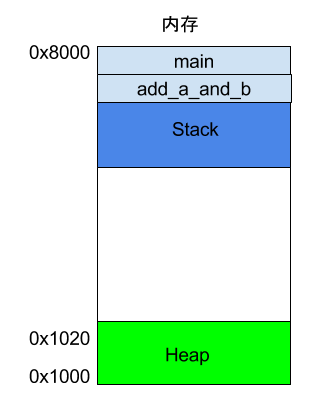
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于==动态的内存占用请求==(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。
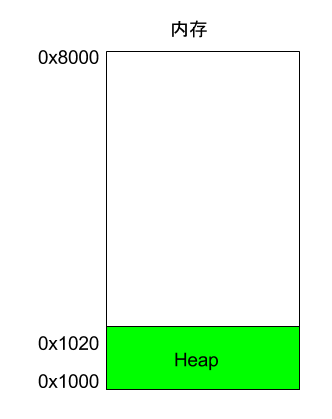
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。==Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收==。
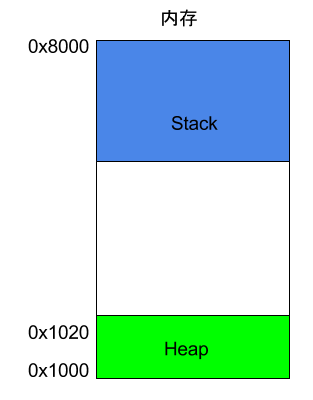
栈(Stack)
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
现假设有以下函数:
1 | int main() { |
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
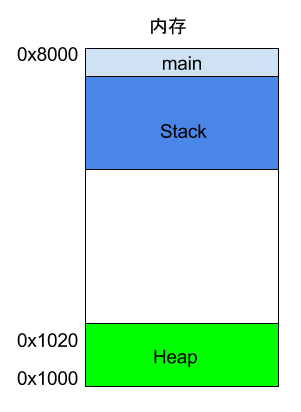
如果函数内部调用了其他函数,会发生什么情况?
1 | int main() { |
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
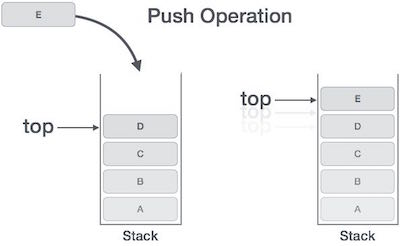
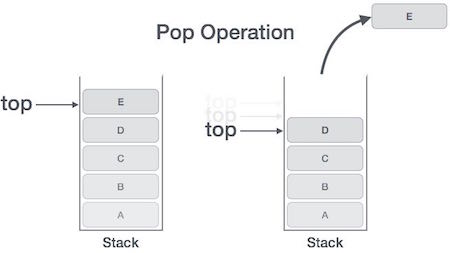
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",英文是 push;栈的回收叫做"出栈",英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
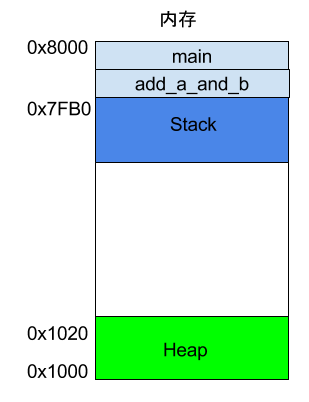
[!IMPORTANT]
栈向下增长,堆向上增长
栗子
现有一个简单的程序:
==exapmle.c==
1 | int add_a_and_b(int a, int b) { |
使用指令将该文件编译为汇编文件:
1 | gcc -S example.c |
上面的命令执行以后,会生成一个文本文件example.s,里面就是汇编语言,包含了几十行指令。这么说吧,一个高级语言的简单操作,底层可能由几个,甚至几十个 CPU 指令构成。CPU 依次执行这些指令,完成这一步操作。
example.s经过简化以后,大概是下面的样子:
1 | _add_a_and_b: |
可以看到,原程序的两个函数add_a_and_b和main,对应两个标签_add_a_and_b和_main。每个标签里面是该函数所转成的 CPU 运行流程。
每一行就是 CPU 执行的一次操作。它又分成两部分,就以其中一行为例:
1 | push %ebx |
这一行里面,push是 CPU 指令,%ebx是该指令要用到的运算子。一个 CPU 指令可以有零个到多个运算子。
Push指令
根据约定,程序从_main标签开始执行,这时会在 Stack 上为main建立一个帧,并将 Stack顶所指向的地址,写入 ESP 寄存器。后面如果有数据要写入main这个帧,就会写在 ESP 寄存器所保存的地址。
然后,开始执行第一行代码。
1 | push 3 |
push指令用于将运算子放入 Stack,这里就是将3写入main这个帧。
虽然看上去很简单,push指令其实有一个前置操作。它会先取出 ESP 寄存器里面的地址,将其减去4个字节,然后将新地址写入 ESP 寄存器。使用减法是因为 Stack 从高位向低位发展,4个字节则是因为3的类型是int,占用4个字节。得到新地址以后, 3 就会写入这个地址开始的四个字节。
1 | push 2 |
第二行也是一样,push指令将2写入main这个帧,位置紧贴着前面写入的3。这时,ESP 寄存器会再减去 4个字节(累计减去8)。

Call指令
第三行的call指令用来调用函数。
1 | call _add_a_and_b |
上面的代码表示调用add_a_and_b函数。这时,程序就会去找_add_a_and_b标签,并为该函数建立一个新的帧。
下面就开始执行_add_a_and_b的代码。
1 | push %ebx |
这一行表示将 EBX 寄存器里面的值,写入_add_a_and_b这个帧。这是因为后面要用到这个寄存器,就先把里面的值取出来,用完后再写回去。
这时,push指令会再将 ESP 寄存器里面的地址减去4个字节(累计减去12)。
Mov指令
mov指令用于将一个值写入某个寄存器。
1 | mov %eax, [%esp+8] |
这一行代码表示,先将 ESP 寄存器里面的地址加上8个字节,得到一个新的地址,然后按照这个地址在 Stack 取出数据。根据前面的步骤,可以推算出这里取出的是2,再将2写入 EAX 寄存器。
下一行代码也是干同样的事情。
1 | mov %ebx, [%esp+12] |
上面的代码将 ESP 寄存器的值加12个字节,再按照这个地址在 Stack 取出数据,这次取出的是3,将其写入 EBX 寄存器。
Add指令
add指令用于将两个运算子相加,并将结果写入第一个运算子。
1 | add %eax, %ebx |
上面的代码将 EAX 寄存器的值(即2)加上 EBX 寄存器的值(即3),得到结果5,再将这个结果写入第一个运算子 EAX 寄存器。
Pop指令
pop指令用于取出 Stack 最近一个写入的值(即最低位地址的值),并将这个值写入运算子指定的位置。
1 | pop %ebx |
上面的代码表示,取出 Stack 最近写入的值(即 EBX 寄存器的原始值),再将这个值写回 EBX 寄存器(因为加法已经做完了,EBX 寄存器用不到了)。
注意,pop指令还会将 ESP 寄存器里面的地址加4,即回收4个字节。
Ret指令
ret指令用于终止当前函数的执行,将运行权交还给上层函数。也就是,当前函数的帧将被回收。
1 | ret |
可以看到,该指令没有运算子。
随着add_a_and_b函数终止执行,系统就回到刚才main函数中断的地方,继续往下执行。
1 | add %esp, 8 |
上面的代码表示,将 ESP 寄存器里面的地址,手动加上8个字节,再写回 ESP 寄存器。这是因为 ESP 寄存器的是 Stack 的写入开始地址,前面的pop操作已经回收了4个字节,这里再回收8个字节,等于全部回收。
1 | ret |
最后,main函数运行结束,ret指令退出程序执行。
语法
段
汇编程序可以分为 3 个段:
-
data 段:data(数据)段被用于声明初始化的数据或常数。此数据在运行时不会更改。您可以在段中声明各种常量值,文件名或缓冲区大小等。
1
section.data
-
bss 段:在 bss 段用于声明变量。
1
section.bss
-
text 段:text 段被用于保持实际的代码。该段必须以全局声明
_start开头,该声明告诉内核程序从何处开始执行。1
2
3section.text
global _start
_start:
注释
汇编语言注释以分号(;)开头。它可以包含任何可打印字符,包括空格。它可以单独出现在一行上,例如
1 | ; 该程序在屏幕上显示一条消息 |
申明
汇编语言程序包含 3 种类型的语句:
- 可执行指令或说明:可执行指令 或简单的 指令 告诉处理器做什么。每个指令由一个 操作码(opcode)组成。每个可执行指令生成一个机器语言指令。
- 汇编程序指令或伪操作:汇编指令 或 伪操作 告诉汇编器关于程序的各个方面。这些是不可执行的,不会生成机器语言指令。
- 宏:宏基本上是一种代码替换机制。
语法结构
汇编语言语句每行输入一个语句。每个语句遵循以下格式:
1 | [label] mnemonic [operands] [;comment] |
方括号中的字段是可选的。基本指令包括两段,第一段是要执行的指令(或助记符)的名称,第二段是命令的操作数或参数。
以下是一些典型汇编语言语句的实例:
1 | INC COUNT ; 增加内存变量 COUNT |
栗子:
1 | section .text |
内存段
如果将 section 关键字替换为 segment,则会得到相同的结果。尝试以下代码:
1 | segment .text |
分段存储器模型将系统存储器分为独立的分段组,这些分段由位于分段寄存器中的指针引用。每个段用于包含特定类型的数据。一个段用于包含指令代码,另一段用于存储数据元素,第三段保留程序堆栈。
根据以上讨论,我们可以将各种内存段指定为:
- 数据段 - 由 .data 段和 .bss 表示。.data 段用于声明存储区,在该存储区中为程序存储了数据元素。声明数据元素后,无法扩展此部分,并且在整个程序中它保持静态。.bss 段也是一个静态内存部分,它包含缓冲区,供稍后在程序中声明的数据使用。这个缓冲区内存是零填充的。
- 代码段 - 它由 .text 表示。这在内存中定义了一个存储指令代码的区域。这也是一个固定区域。
- 堆栈 - 该段包含传递给程序中的函数和过程的数据值。
系统调用
系统调用是用户空间和内核空间之间接口的 API。我们已经使用了系统调用。syswrite 和 sysexit,分别用于写入屏幕和退出程序。
如何在linux中使用系统调用?
- 将系统呼叫号放入 EAX 寄存器中。
- 将参数保存到系统调用中的寄存器 EBX,ECX 等中。
- 调用相关的中断(80h)。
- 结果通常在 EAX 寄存器中返回。
有 6 个寄存器,用于存储所用系统调用的参数。它们是 EBX,ECX,EDX,ESI,EDI 和 EBP。这些寄存器采用从 EBX 寄存器开始的连续参数。如果有 6 个以上的自变量,则第一个自变量的存储位置将存储在 EBX 寄存器中。
以下代码显示了系统调用
sys_exit的使用:
2
int0x80; 调用内核以下代码显示了系统调用
sys_write的使用:
2
3
4
5
movecx,msg; 消息内容
movebx,1; 文件描述 (stdout)
moveax,4; 系统调用号 (sys_write)
int0x80; 调用内核[!IMPORTANT]
常见系统调用:
%eax 名称 %ebx %ecx %edx %esx %edi 1 sys_exit int - - - - 2 sys_fork struct pt_regs - - - - 3 sys_read unsigned int char size_t - - 4 sys_write unsigned int const char size_t - - 5 sys_open const char * int int - - 6 sys_close unsigned int - - - -
栗子:
1 | section .data ;数据段 |
输出结果如下:
1 | Please enter a number: |
寻址模式
大多数汇编语言指令都需要处理操作数。操作数地址提供了要处理的数据存储的位置。有些指令不需要操作数,而另一些指令则需要一个,两个或三个操作数。
当一条指令需要两个操作数时,第一个操作数通常是==目的地==,它在寄存器或存储器位置中包含数据,第二个==操作数是源==。源包含要传递的数据(立即寻址)或数据的地址(在寄存器或存储器中)。通常,操作后源数据保持不变。
寻址的三种基本模式是:
- 寄存器寻址
- 立即寻址
- 内存寻址
寄存器寻址
在这种寻址模式下,寄存器包含操作数。根据指令,寄存器可以是第一个操作数,第二个操作数或两者。
1 | MOV DX, TAX_RATE ; 寄存器是第一个操作数 |
由于寄存器之间的数据处理不涉及内存,因此可以最快地处理数据。
立即寻址
立即数操作数具有常量值或表达式。当具有两个操作数的指令使用立即寻址时,第一个操作数可以是寄存器或存储器位置,而第二个操作数是立即数。第一个操作数定义数据的长度。
1 | BYTE_VALUE DB 150 ; 一个字节值被定义 |
直接内存寻址
在存储器寻址模式下指定操作数时,通常需要直接访问主存储器,通常是数据段。这种寻址方式导致数据处理变慢。为了找到数据在内存中的确切位置,我们需要段起始地址(通常在 DS 寄存器中找到)和偏移值。此偏移值也称为 有效地址。
在直接寻址模式下,偏移量值直接作为指令的一部分指定,通常由变量名指示。汇编器计算偏移值并维护一个符号表,该表存储程序中使用的所有变量的偏移值。在直接存储器寻址中,一个操作数引用一个存储器位置,另一个操作数引用一个寄存器。
1 | ADDBYTE_VALUE, DL; 将寄存器添加到存储位置 |
直接偏移寻址
此寻址模式使用算术运算符修改地址。例如,查看以下定义数据表的定义:
1 | BYTE_TABLE DB 14, 15, 22, 45 ; 字节表 |
以下操作将数据从内存中的表访问到寄存器中:
1 | MOV CL, BYTE_TABLE[2]; 获取 BYTE_TABLE 的第 3 个元素 |
间接内存寻址
此寻址模式利用计算机的 Segment:Offset 寻址功能。通常,在方括号内编码的基址寄存器 EBX,EBP(或 BX,BP)和索引寄存器(DI,SI)用于内存引用。
间接寻址通常用于包含多个元素(如数组)的变量。阵列的起始地址存储在 EBX 寄存器中。
以下代码段显示了如何访问变量的不同元素。
1 | MY_TABLE TIMES 10 DW 0 ; 分配 10 个字(2 个字节),每个字都初始化为 0 |
[!NOTE]
注意:
[]在这里实际上是解引用,用来访问地址中的值这里给EBX加2是给地址增加两字节,增加n就是增加n个字节,并不随着变量的类型而改变
MOV指令
我们已经使用了 MOV 指令,该指令用于将数据从一个存储空间移动到另一个存储空间。MOV 指令采用两个操作数。
1 | MOV destination, source |
MOV指令可以有以下五种形式:
1 | MOV register, register |
[!NOTE]
- Mov操作中的两个操作数应具有相同的大小
- 源操作数的值保持不变
MOV指令有时会引起歧义。例如:
目前尚不清楚是要移动等于 110 的字节等效值还是等效于字的字符。在这种情况下,使用类型说明符 是明智的。
下表是一些常见的类型说明符:
类型说明符 寻址字节 BYTE 1 WORD 2 DWORD 4 QWORD 8 TBYTE 10
栗子:
下面的程序说明了上面讨论的一些概念。它在存储器的数据部分中存储名称 “Alex Mo”,然后以编程方式将其值更改为另一个名称 “Feng Mo” 并显示这两个名称。
1 | section .text |
数据类型
变量
初始化数据分配空间
初始化数据的存储分配语句的语法为:
1 | [variable-name] define-directive initial-value [,initial-value]... |
其中,变量名 是每个存储空间的标识符。汇编器为数据段中定义的每个变量名称关联一个偏移值。
define 指令有五种基本形式:
| 指令 | 作用 | 储存空间 |
|---|---|---|
| DB | 定义字节 | 分配 1 个字节 |
| DW | 定义字 | 分配 2 个字节 |
| DD | 定义双字 | 分配 4 个字节 |
| DQ | 定义四字 | 分配 8 个字节 |
| DT | 定义十个字节 | 分配 10 个字节 |
栗子:
1 | choice DB 'y' |
[!NOTE]
- 字符的每个字节均以十六进制形式存储为其 ASCII 值。
- 每个十进制值都将自动转换为其等效的 16 位二进制数,并以十六进制数形式存储。
- 处理器使用小尾数字节顺序。
- 负数将转换为其 2 的补码表示形式。
- 短浮点数和长浮点数分别使用 32 位或 64 位表示。
1 | section .text |
未初始化数据分配空间
reserve 指令用于为未初始化的数据保留空间。reserve 指令采用单个操作数,该操作数指定要保留的空间单位数。每个 define 指令都有一个相关的 reserve 指令。
reserve 指令有五种基本形式:
| 指令 | 作用 |
|---|---|
| RESB | 保留 1 个字节 |
| RESW | 保留字 |
| RESD | 保留 1 个双字 |
| RESQ | 保留 4 个字 |
| REST | 保留 10 个字节 |
多重初始化
TIMES 指令允许多次初始化为相同的值。例如,可以使用以下语句定义一个大小为 9 的标记的数组并将其初始化为 0:
1 | section .text |
常量
常见常量指令:
EQU%assign%define
EQU指令
EQU 指令用于定义常量。EQU 指令的语法如下:
1 | CONSTANT_NAME EQU expression |
栗子:
1 | TOTAL_STUDENTS equ 50 |
当然,EQU语句的操作数也可以是表达式
1 | LENGTH equ 20 |
更加复杂的栗子:
1 | SYS_EXIT equ 1 |
%assign 指令
%assign 指令像 EQU 指令一样可以用来定义数字常量。该指令支持重新定义。例如,您可以将常量 TOTAL 先定义为:
1 | %assign TOTAL 10 |
在代码的后面,您可以将其重新定义为:
1 | %assign TOTAL 20 |
[!NOTE]
注意 :指令区分大小写。
%define 指令
%define 指令可以定义数值和字符串常量。该指令类似于 C 语言中的 #define。例如,您可以将常量 PTR 定义为:
1 | %define PTR [EBP+4] |
上面的代码用 [EBP + 4] 替换了 PTR。
该指令也支持重新定义,并且区分大小写。
数字
数值数据通常用二进制表示。算术指令对二进制数据进行操作。==当数字显示在屏幕上或从键盘输入时,它们是 ASCII 形式==。到目前为止,我们已经将该输入数据以 ASCII 形式转换为二进制以进行算术计算,并将结果转换回二进制。
1 | section .text |
然而,这种转换有性能损耗,汇编语言编程支持以更有效的方式处理二进制形式的数字。
十进制数字可以用两种形式:
- ASCII 格式
- BCD 或二进制编码十进制形式
ASCII表示
在 ASCII 表示中,十进制数字存储为 ASCII 字符字符串。
例如,十进制值 1234 存储为:
1 | 31323334H |
其中,31H 是 1 的 ASCII 值,32H 是 2 的 ASCII 值,依此类推。
有 4 种指令用于处理 ASCII 表示形式的数字:
AAA- 加法后 的ASCII 调整AAS- 减法后的 ASCII 调整AAM- 乘法后的 ASCII 调整AAD- 除法前的 ASCII 调整
这些指令不使用任何操作数,并假定所需的操作数位于 AL 寄存器中。
比如下面的实例:
1 | section .text |
BCD表示
BCD 表示有两种类型:
- 未打包的 BCD 表示
- 打包的 BCD 表示
在未压缩的 BCD 表示形式中,每个字节都存储一个十进制数字的二进制等效项。例如,数字 1234 存储为:
1 | 01 02 03 04H |
有两种指令来处理这些数字:
AAM- 乘法后 ASCII 调整AAD- 除法前 ASCII 调整
四个 ASCII 调整指令 AAA,AAS,AAM 和 AAD 也可以与未打包的 BCD 表示一起使用。在打包的 BCD 表示中,每个数字使用四位存储。两个十进制数字打包成一个字节。
例如,数字 1234 存储为:
1 | 1234H |
有两种指令来处理这些数字:
DAA- 加法后的十进制调整DAS- 减后的十进制调整
[!TIP]
打包的 BCD 表示形式不支持乘法和除法。
栗子:
以下程序将两个 5 位十进制数字加起来并显示总和。
1 | section .text |
字符串
在前面的实例中,我们已经使用了可变长度字符串。可变长度字符串可以包含所需的任意多个字符。
通常,我们通过以下两种方法之一指定字符串的长度:
- 显式存储字符串长度
- 使用哨兵字符
我们可以使用表示位置计数器当前值的 $location 计数器符号来显式存储字符串长度。
在以下实例中:
1 | msg db 'Hello, world!',0xa ;我们常见的字符 |
[!TIP]
这里可以注意到使用db来定义字符串,在变量一节中,db是用来定义一个字节的。
所以实际上以上的代码我们可以理解为
$指向字符串变量 msg 的最后一个字符之后的字节。因此,$ - msg 给出字符串的长度。我们也可以这样写:
1 | msg db 'Hello, world!',0xa ;字符串 |
另外,您可以存储带有尾部定点字符的字符串来定界字符串,而不是显式存储字符串长度。前哨字符应为不出现在字符串中的特殊字符。
例如,
1 | message DB 'I am loving it!', 0 |
字符串指令
每个字符串指令可能需要一个源操作数,一个目标操作数或两者。对于 32 位段,字符串指令使用 ESI 和 EDI 寄存器分别指向源和目标操作数。但是,对于 16 位段,SI 和 DI 寄存器分别用于指向源和目标。
有 5 种用于处理字符串的基本说明。他们是:
MOVS- 该指令将 1 字节,字或双字数据从存储位置移到另一个位置。LODS- 该指令从存储器加载。如果操作数是一个字节,则将其加载到 AL 寄存器中;如果操作数是一个字,则将其加载到 AX 寄存器中,并将双字加载到 EAX 寄存器中。STOS- 该指令将数据从寄存器(AL,AX 或 EAX)存储到存储器。CMPS- 该指令比较内存中的两个数据项。数据可以是字节大小,字或双字。SCAS- 该指令将寄存器(AL,AX 或 EAX)的内容与内存中项目的内容进行比较。
上面的每个指令都有字节,字和双字版本,并且可以通过使用重复前缀来重复字符串指令。
这些指令使用 ES:DI 和 DS:SI 对寄存器,其中 DI 和 SI 寄存器包含有效的偏移地址,这些地址指向存储在存储器中的字节。SI 通常与 DS(数据段)相关联,DI 通常与 ES(额外段)相关联。
DS:SI(或 ESI)和 ES:DI(或 EDI)寄存器分别指向源和目标操作数。假定源操作数位于内存中的 DS:SI(或 ESI),目标操作数位于 ES:DI(或 EDI)。
对于 16 位地址,使用 SI 和 DI 寄存器,对于 32 位地址,使用 ESI 和 EDI 寄存器。
下表提供了各种版本的字符串指令和假定的操作数空间:
| 基础指令 | 操作的寄存器 | 字节运算 | 字运算 | 双字运算 |
|---|---|---|---|---|
| MOVS | ES:DI, DS:SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS:SI | LODSB | LODSW | LODSD |
| STOS | ES:DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS:SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES:DI, AX | SCASB | SCASW | SCASD |
MOVS
MOVS 指令用于将数据项(字节,字或双字)从源字符串复制到目标字符串。源字符串由 DS:SI 指向,目标字符串由 ES:DI 指向。
1 | section .text |
LODS
LODS 指令从存储器加载。如果操作数是一个字节,则将其加载到 AL 寄存器中;如果操作数是一个字,则将其加载到 AX 寄存器中,并将双字加载到 EAX 寄存器中。
在密码术中,凯撒密码是最简单的已知加密技术之一。在这种方法中,要加密的数据中的每个字母都被替换为字母下方固定数量位置的字母。
在这个实例中,让我们通过简单地将其中的每个字母替换为两个字母来加密数据,因此 a 将被 c,b 替换为 d 等。我们使用 LODS 将原始字符串 ‘password’ 加载到内存中。
1 | section .text |
STOS
STOS 指令将数据项从 AL(用于字节-STOSB)、AX(用于字-STOSW)或 EAX(用于双字-STOSD)复制到内存中 ES:DI 指向的目标字符串。
以下实例演示如何使用 LODS 和 STOS 指令将大写字符串转换为小写值:
1 | section .text |
CMPS
CMPS 指令比较两个字符串。此指令比较 DS:SI 和 ES:DI 寄存器指向的单字节、字或双字的两个数据项,并相应设置标志。您还可以将条件跳转指令与此指令一起使用。
以下实例演示如何使用 CMPS 指令比较两个字符串:
1 | section .text |
SCAS
SCAS 指令用于搜索字符串中的特定字符或一组字符。要搜索的数据项应该在 AL(对于 SCASB),AX(对于 SCASW)或 EAX(对于 SCASD)寄存器中。要搜索的字符串应在内存中,并由 ES:DI(或 EDI)寄存器指向。
参考以下实例来了解概念:
1 | section .text |
重复前缀
REP 前缀在字符串指令(例如 - REP MOVSB)之前设置时,会根据放置在 CX 寄存器中的计数器使该指令重复。REP 执行该指令,将 CX 减 1,然后检查 CX 是否为 0。重复指令处理,直到 CX 为 0 为止。
方向标志(DF)确定操作的方向。
- 使用 CLD(清除方向标志,DF = 0)使操作从左到右。
- 使用 STD(设置方向标志,DF = 1)使操作从右到左。
REP 前缀也有以下变化:
- REP: 这是无条件的重复。重复该操作,直到 CX 为零为止。
- REPE 或 REPZ: 这是有条件的重复。当零标志指示等于/零时,它将重复操作。当 ZF 表示不等于 0 或 CX 为 0 时,它将停止。
- REPNE 或 REPNZ: 这也是有条件的重复。当零标志指示不等于/ 0 时,它将重复操作。当 ZF 指示等于/ 0 或 CX 减为 0 时,它将停止。
数组
我们已经讨论过,汇编器的数据定义指令用于为变量分配存储。还可以使用某些特定值初始化变量。可以十六进制、十进制或二进制形式指定初始化值。
例如,我们可以用以下任一方式定义单词变量 “months”:
1 | MONTHS DW 12 |
数据定义指令也可用于定义一维数组。让我们定义一个一维数字数组。
1 | NUMBERS DW 34, 45, 56, 67, 75, 89 |
上面的定义声明了一个由 6 个单词组成的数组,每个单词用数字 34、45、56、67、75、89 初始化。这将分配 2x6=12 字节的连续内存空间。第一个数字的符号地址为 NUMBERS,第二个数字的字符地址为 NUMBERS+2 ,依此类推。
让我们再举一个例子。您可以定义一个名为 inventory 的数组,大小为 8,并将所有值初始化为 0,比如:
1 | INVENTORY DW 0 |
可以缩写为:
1 | INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0 |
TIMES 指令还可用于对同一值进行多次初始化。使用 TIMES,可以将 INVENTORY 数组定义为:
1 | INVENTORY TIMES 8 DW 0 |
栗子:
以下实例通过定义一个 3 元素数组 x 来演示上述概念,该数组存储三个值:2、3 和 4。它将值添加到数组中并显示总和 9:
1 | section .text |
宏
编写宏是确保用汇编语言进行模块化编程的另一种方法。
- 宏是一系列指令,由名称指定,可以在程序中的任何位置使用。
- 在 NASM 中,宏是用
%macro和%endmacro指令定义的。 - 宏以
%macro指令开始,以%endmacro指令结束。
宏的语法如下:
1 | %macro macro_name number_of_params |
其中,number_of_params 指定数字参数,macro_name 指定宏的名称。
通过使用宏名称和必要的参数来调用宏。当您需要在程序中多次使用某个指令序列时,可以将这些指令放在宏中并使用它,而不是一直编写指令。
例如,程序的一个常见需求是在屏幕上写入字符串。要显示字符串,您需要以下指令序列:
1 | move dx,len ;message length |
在上面显示字符串的实例中,INT 0x80 函数调用使用了寄存器 EAX、EBX、ECX 和 EDX。因此,每次需要在屏幕上显示时,都需要将这些寄存器保存在堆栈上,调用 INT 80H,然后从堆栈中恢复寄存器的原始值。因此,编写两个宏来保存和恢复数据可能很有用。
我们注意到,一些指令,如 IMUL、IDIV、INT 等,需要将一些信息存储在某些特定寄存器中,甚至在某些特定的寄存器中返回值。如果程序已经使用这些寄存器来保存重要数据,那么这些寄存器中的现有数据应该保存在堆栈中,并在指令执行后恢复。
栗子:
1 | ; 具有两个参数的宏 |
运算
算术运算
INC指令
INC 指令用于将操作数加 1。它对可以在寄存器或内存中的单个操作数起作用。
INC 指令的语法如下:
1 | INC destination |
目标操作数 可以是 8 位,16 位或 32 位操作数。
小栗子:
1 | INC EBX ; 32 位寄存器 自增 1 |
DEC指令
DEC 指令用于将操作数减 1。它对可以在寄存器或内存中的单个操作数起作用。
DEC 指令的语法如下:
1 | DEC destination |
目标操作数 可以是 8 位,16 位或 32 位操作数。
小栗子:
1 | segment .data |
ADD和SUB
ADD 和 SUB 指令用于对字节,字和双字大小的二进制数据进行简单的 加/减,即分别用于加或减去 8 位,16 位或 32 位操作数。
ADD 和 SUB 指令的语法如下:
1 | ADD/SUB destination, source |
ADD / SUB 指令可以发生在:
- 寄存器 到 寄存器
- 内存 到 寄存器
- 寄存器 到 内存
- 寄存器 到 常量数据
- 内存 到 常量数据
但是,像其他指令一样,使用 ADD / SUB 指令也无法进行存储器到存储器的操作。ADD 或 SUB 操作设置或清除溢出和进位标志。
栗子:
下面的实例将要求用户输入两位数字,分别将这些数字存储在 EAX 和 EBX 寄存器中,将这些值相加,将结果存储在 “res” 存储位置中,最后显示结果:
1 | SYS_EXIT equ 1 |
运算结果如下:
1 | Enter a digit: |
MUL和IMUL
二进制数据相乘有两条指令。MUL(乘法)指令处理无符号数据,IMUL(整数乘法)处理有符号数据。这两条指令都会影响进位和溢出标志。
MUL/IMUL 指令的语法如下:
1 | MUL/IMUL multiplier |
在这两种情况下,被乘数都将在一个累加器中,具体取决于被乘数和乘数的大小,并且根据操作数的大小,生成的乘积还将存储在两个寄存器中。
| 编号 | 情景 |
|---|---|
| 1 | **当两个字节相乘时:**被乘数在 AL 寄存器中,而乘数在存储器或另一个寄存器中为一个字节。该产品使用 AX。乘积的高 8 位存储在 AH 中,低 8 位存储在 AL 中。 |
| 2 | **当两个单字值相乘时:**被乘数应位于 AX 寄存器中,并且乘数是内存或其他寄存器中的一个字。例如,对于 MUL DX 之类的指令,必须将乘数存储在 DX 中,将被乘数存储在 AX 中。结果乘积是一个双字,将需要两个寄存器。高阶(最左侧)部分存储在 DX 中,而低阶(最右侧)部分存储在 AX 中。 |
| 3 | **当两个双字值相乘时:**当两个双字值相乘时,被乘数应位于 EAX 中,并且该乘数是存储在存储器或另一个寄存器中的双字值。生成的乘积存储在 EDX:EAX 寄存器中,即,高 32 位存储在 EDX 寄存器中,低 32 位存储在 EAX 寄存器中。 |
栗子:
1 | MOV AL, 10 |
以下实例将 3 乘以 2,并显示结果:
1 | section .text |
DIV/IDIV
除法运算生成两个元素 —— 商 和 余数。在乘法的情况下,不会发生溢出,因为使用双长度寄存器来保存乘积。然而,在除法的情况下,可能会发生溢出。如果发生溢出,处理器将生成中断。DIV(Divide)指令用于无符号数据,IDIV(整数除法)用于有符号数据。
DIV(Divide)指令用于无符号数据,IDIV(整数除法)用于有符号数据。
语法
DIV / IDIV 指令的格式:
1 | DIV/IDIV divisor |
被除数在累加器中。两条指令都可以使用 8 位,16 位或 32 位操作数。该操作影响所有 6 个状态标志。
以下部分说明了 3 种操作数大小不同的除法情况:
| 编号 | 情景 |
|---|---|
| 1 | **当除数为 1 个字节时:**假设被除数在 AX 寄存器中(16 位)除法后,商进入 AL 寄存器,余数进入 AH 寄存器 |
| 2 | **当除数为 1 个单字时:**假设被除数为 32 位长,并且在 DX:AX 寄存器中高位 16 位在 DX 中,低位 16 位在 AX 中除法后,16 位商进入 AX 寄存器,16 位余数进入 DX 寄存器。 |
| 3 | **当除数是双字:**假设被除数为 64 位长,并且在 EDX:EAX 寄存器中高位 32 位在 EDX 中,低位 32 位在 EAX 中除法后,32 位商进入 EAX 寄存器,32 位余数进入 EDX 寄存器。 |
以下实例将 8 除以 2。被除数 8 存储在 16 位 AX 寄存器中,除数 2 存储在 8 位 BL 寄存器 中。
1 | section .text |
逻辑运算
处理器指令集提供指令 AND、OR、XOR、TEST 和 NOT 布尔逻辑,这些逻辑根据程序的需要测试、设置和清除位。
这些指令的格式如下:
| 编号 | 指令 | 格式 |
|---|---|---|
| 1 | AND | AND 操作数 1,操作数 2 |
| 2 | OR | OR 操作数 1,操作数 2 |
| 3 | XOR | XOR 操作数 1,操作数 2 |
| 4 | TEST | TEST 操作数 1,操作数 2 |
| 5 | NOT | NOT 操作数 1 |
在所有情况下,第一个操作数都可以在寄存器或内存中。第二个操作数可以是寄存器/内存,也可以是立即数(常数)。但是,内存到内存操作是不可能的。这些指令比较或匹配操作数的位,并设置 CF,OF,PF,SF 和 ZF 标志。
AND指令
AND 指令用于通过执行逐位 AND 运算来支持逻辑表达式。如果两个操作数的匹配位都是 1,则按位 AND 操作返回 1,否则返回 0。例如:
1 | Operand1: 0101 |
AND 操作可用于清除一个或多个位。例如,假设 BL 寄存器包含 0011 1010 。如果需要将高位清除为 0,则使用 0FH 对其进行 与运算。
1 | AND BL, 0FH ; BL 设置为 0000 1010 |
让我们来看另一个例子。如果要检查给定数字是奇数还是偶数,一个简单的测试将是检查数字的最低有效位。如果为 1,则数字为奇数,否则为偶数。
假设数字在 AL 寄存器中,我们可以这样写:
1 | AND AL, 01H ; ANDing with 0000 0001 |
栗子:
1 | section .text |
结果如下:
1 | Even Number! |
用一个奇数位更改 AX 寄存器中的值,例如:
1 | mov ax, 9h ; ax 中获取 9 |
结果如下:
1 | Odd Number! |
同样,要清除整个寄存器,您可以将其与 00H 进行 与运算。
OR指令
OR 指令用于通过执行逐位 OR 运算来支持逻辑表达式。如果其中一个或两个操作数的匹配位为 1,则按位 OR 运算符返回 1。如果两个位都为 0,则返回 0。
比如:
1 | Operand1: 0101 |
或运算 可用于设置一个或多个位。例如,假设AL寄存器包含 0011 1010,则需要设置 4 个低阶位,您可以将其与值 0000 1111(即 FH)进行 或运算。
1 | OR BL, 0FH ; 设置 BL 为 0011 1111 |
栗子:
下面的实例演示 OR 指令。让我们将值 5 和 3 分别存储在 AL 和 BL 寄存器中,然后是指令。
1 | OR AL, BL |
应在 AL 寄存器中存储 7:
1 | section .text |
XOR指令
XOR 指令实现按位异或运算。当且仅当来自操作数的位不同时,XOR 运算将结果位设置为 1。如果来自操作数的位相同(均为 0 或均为 1),则将结果位清除为 0。
例如:
1 | Operand1: 0101 |
将操作数与自身进行 XOR 会将操作数更改为 0。这用于清除寄存器。
1 | XOR EAX, EAX |
TEST指令
TEST 指令与 AND 运算的工作原理相同,但与 AND 指令不同的是,它不会更改第一个操作数。因此,如果我们需要检查寄存器中的数字是偶数还是奇数,我们也可以使用 TEST 指令执行此操作,而无需更改原始数字。
1 | TEST AL, 01H |
NOT指令
NOT 指令实现按位否操作。NOT 运算反转操作数中的位。操作数可以在寄存器中,也可以在内存中。
例如:
1 | Operand1: 0101 0011 |
控制结构
跳转指令
汇编语言中的条件执行是通过几个循环和分支指令来完成的。这些指令可以改变程序中的控制流。
在两种情况下观察到有条件执行:
| 编号 | 条件指令 |
|---|---|
| 1 | 无条件跳转这由 JMP 指令执行条件执行通常涉及将控制权转移到当前执行指令后面的指令的地址控制权的转移可以向前,以执行一组新的指令,也可以向后,以重新执行相同的步骤。 |
| 2 | 条件跳转这由一组跳转指令 j |
CMP指令
CMP 指令比较两个操作数。它通常用于条件执行。此指令基本上是从另一个操作数中减去一个,以比较操作数是否相等。它不会干扰目标或源操作数。它与条件跳转指令一起用于决策。
CMP 比较两个数字数据字段。目标操作数可以在寄存器中,也可以在内存中。源操作数可以是常量数据、寄存器或内存。
1 | CMP DX,00 ; 将 DX 值与 0 进行比较 |
CMP 通常用于比较计数器值是否已达到需要运行循环的次数。
比如下面的典型条件:
1 | INC EDX |
无条件跳转
如前所述,这是通过 JMP 指令执行的。条件执行通常涉及将控制权转移到不遵循当前执行指令的指令的地址。控制权的转移可以是前进的(执行新的指令集),也可以是后退的(重新执行相同的步骤)。
JMP 指令提供了一个标签名称,控制流将立即转移到该标签名称。JMP 指令的语法是:
1 | JMP label |
栗子:
1 | MOV AX, 00 ; 将AX初始化为0 |
条件跳转
如果在条件跳转中满足某些指定条件,则控制流将转移到目标指令。根据条件和数据,有许多条件跳转指令。
-
以下是用于算术运算的有符号数据的条件跳转指令:
指令 描述 标志测试 JE/JZ 跳转等于或跳转零 ZF JNE/JNZ 跳转不等于或跳转不为零 ZF JG/JNLE 跳转大于或跳转不小于/等于 OF, SF, ZF JGE/JNL 跳转大于/等于或不小于跳转 OF, SF JL/JNGE 跳转小于或不大于/等于 OF, SF JLE/JNG 跳少/等于或跳不大于 OF, SF, ZF -
以下是对用于逻辑运算的无符号数据使用的条件跳转指令:
指令 描述 标志测试 JE/JZ 跳转等于或跳转零 ZF JNE/JNZ 跳转不等于或跳转不为零 ZF JA/JNBE 跳转向上或不低于/等于 CF, ZF JAE/JNB 高于/等于或不低于 CF JB/JNAE 跳到以下或跳到不高于/等于 CF JBE/JNA 跳到下面/等于或不跳到上方 AF, CF -
以下条件跳转指令有特殊用途,并检查标志的值:
指令 描述 标志测试 JXCZ 如果 CX 为零则跳转 none JC 如果携带则跳转 CF JNC 如果不携带则跳转 CF JO Jump If Overflow OF JNO 如果没有溢出则跳转 OF JP/JPE 跳校验或偶校验 PF JNP/JPO 跳转无奇偶校验或跳转奇偶校验 PF JS 跳跃符号(负值) SF JNS 跳转无符号(正值) SF J
指令集的语法: 1
2
3
4
5
6
7
8CMP AL, BL
JE EQU AL
CMP AL, BH
JE EQU AL
CMP AL, CL
JE EQU AL
NON_EQUAL: ...
EQUAL: ...栗子:
以下程序显示 3 个变量中最大的一个。变量是两位数的变量。3 个变量
num1,num2和num3分别具有值 47、22 和 31:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33section .text
global _start ;必须声明 gcc
_start: ;告诉链接器入口点
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;文件描述 (stdout)
mov eax,4 ;系统调用号 (sys_write)
int 0x80 ;调用内核
mov ecx,largest
mov edx, 2
mov ebx,1 ;文件描述 (stdout)
mov eax,4 ;系统调用号 (sys_write)
int 0x80 ;调用内核
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2
循环
JMP 指令可用于实现循环。例如,以下代码段可用于执行循环体 10 次。
1 | MOV CL, 10 |
但是,处理器指令集包括一组用于实现迭代的循环指令。
基本的 LOOP 指令语法如下:
1 | LOOP label |
其中,label 是标识目标指令的目标标签,如跳转指令中所述。循环指令假定 ECX 寄存器包含循环计数。当执行循环指令时,ECX 寄存器递减,并且控制跳至目标标签,直到 ECX 寄存器的值(即计数器达到零)为止。那么下面的代码可以写成:
1 | mov ECX,10 |
栗子:
以下程序在屏幕上打印数字 1 到 9:
1 | section .text |
过程
过程或子程序在汇编语言中非常重要,因为汇编语言程序往往很大。程序由名称标识。在此名称之后,描述了执行定义良好的作业的过程主体。返回语句表示过程结束。
语法:
1 | proc_name: |
通过使用 CALL 指令从另一个函数调用该过程。CALL 指令应将被调用过程的名称作为参数,如下所示:
1 | CALL proc_name |
被调用的过程使用 RET 指令将控件返回给调用过程。
让我们编写一个名为 sum 的非常简单的过程,该过程将存储在 ECX 和 EDX 寄存器中的变量相加,并在 EAX 寄存器中返回总和:
1 | section .text |
栈数据结构
栈是内存中类似数组的数据结构,可以在其中存储数据并从称为栈 “顶部” 的位置删除数据。需要存储的数据被 “推” 到栈中,要检索的数据被从栈中 “弹出” 出来。栈是后进先出的数据结构,即先存储的数据最后检索。
汇编语言为栈操作提供了两条指令:PUSH 和 POP。这些指令的语法如下:
1 | PUSH operand |
栈段中保留的内存空间用于实现栈。寄存器 SS 和 ESP(或 SP)用于实现栈。SS:ESP 寄存器指向栈的顶部,该顶部指向插入到栈中的最后一个数据项,其中 SS 寄存器指向栈段的开头,而 SP(或 ESP)将偏移量设置为栈段。
栈实现具有以下特征:
- 只能将字或双字保存到栈中,而不是字节。
- 栈朝反方向增长,即朝着较低的存储器地址增长
- 栈的顶部指向插入栈中的最后一个项目。它指向插入的最后一个字的低字节。
正如我们所讨论的,在将寄存器的值用于某些用途之前将其存储在栈中。它可以通过以下方式完成:
1 | ; 将 AX 和 BX 寄存器内容保存在堆栈中 |
栗子:
以下程序显示整个 ASCII 字符集。主程序调用一个名为 display 的过程,该过程显示 ASCII 字符集:
1 | section .text |
递归
递归过程是调用自身的过程。有两种递归:直接递归和间接递归。在直接递归中,过程调用自身,而在间接递归中,第一个过程调用第二个过程,后者又调用第一个过程。
在许多数学算法中可以观察到递归。例如,考虑一下计算一个数的阶乘的情况。一个数的阶乘由方程式给出:
1 | Fact (n) = n * fact (n-1) for n > 0 |
下面的程序展示了如何在汇编语言中实现阶乘 n。为了保持程序简单,我们将计算阶乘 3。
1 | section .text |
文件管理
系统将任何输入或输出数据视为字节流。有 3 种标准文件流:
- 标准输入(stdin)
- 标准输出(stdout)
- 标准错误(stderr)
==文件描述符:==
文件描述符 是作为 文件id 分配给文件的 16 位整数。创建新文件或打开现有文件时,文件描述符用于访问文件。
标准文件流的文件描述符
stdin、stdout和stderr分别为 0、1 和 2。
==文件指针==
文件指针 以字节为单位指定文件中后续读/写操作的位置。每个文件都被视为一个字节序列。每个打开的文件都与一个文件指针相关联,该指针指定相对于文件开头的偏移量(以字节为单位)。打开文件时,文件指针设置为 0。
==文件处理系统调用==
下表简要介绍了与文件处理相关的系统调用:
%eax 名称 %ebx %ecx %edx 2 sys_fork struct pt_regs - - 3 sys_read unsigned int char size_t 4 sys_write unsigned int const char size_t 5 sys_open const char int int 6 sys_close unsigned int - - 8 sys_creat const char int - 19 sys_lseek unsigned int off_t unsigned int 使用系统调用所需的步骤与前面讨论的相同:
- 将系统呼叫号码放入 EAX 寄存器。
- 将系统调用的参数存储在寄存器 EBX、ECX 等中。
- 调用相关中断(80h)。
- 结果通常返回到 EAX 寄存器中。
==创建和打开文件==
要创建和打开文件,请执行以下任务:
- 将系统调用
sys_creat()放入 EAX 寄存器中。- 将文件名放入 EBX 寄存器。
- 将文件权限放入 ECX 寄存器。
系统调用返回 EAX 寄存器中创建的文件的文件描述符,如果出现错误,错误代码位于 EAX 寄存器。
==打开现有文件==
要打开现有文件,请执行以下任务:
- 将系统调用
sys_open()放入 EAX 寄存器。- 将文件名放入 EBX 寄存器。
- 将文件访问模式放入 ECX 寄存器。
- 将文件权限放入 EDX 寄存器。
系统调用返回 EAX 寄存器中创建的文件的文件描述符,如果出现错误,错误代码位于EAX寄存器。
在文件访问模式中,最常用的是:只读(0)、只写(1) 和 读写(2)。
==从文件中读取==
要读取文件,请执行以下任务:
- 将系统调用
sys_read()放入 EAX 寄存器中。- 将文件描述符放入 EBX 寄存器。
- 将指针指向 ECX 寄存器中的输入缓冲区。
- 将缓冲区大小,即要读取的字节数,放入 EDX 寄存器。
系统调用返回在 EAX 寄存器中读取的字节数,如果出现错误,错误代码位于 EAX 寄存器。
==写入文件==
要写入文件,请执行以下任务:
- 将系统调用
sys_write()放入 EAX 寄存器中。- 将文件描述符放入 EBX 寄存器。
- 将指针指向 ECX 寄存器中的输出缓冲区。
- 将缓冲区大小,即要写入的字节数,放入 EDX 寄存器。
系统调用返回写入 EAX 寄存器的实际字节数,如果出现错误,错误代码位于 EAX 寄存器中。
==关闭文件==
要关闭文件,请执行以下任务:
- 将系统调用
sys_close()放入 EAX 寄存器中。- 将文件描述符放入 EBX 寄存器。
如果出现错误,系统调用将返回 EAX 寄存器中的错误代码。
==更新文件==
要更新文件,请执行以下任务 & minus;
- 将系统调用
sys_lseek()放入 EAX 寄存器中。- 将文件描述符放入 EBX 寄存器。
- 将偏移值放入 ECX 寄存器。
- 将偏移量的参考位置放入 EDX 寄存器。
参考位置可以是:
- 文件开头 - 值 0
- 当前位置 - 值 1
- 文件结尾 - 值 2
如果出现错误,系统调用将返回 EAX 寄存器中的错误代码。
栗子:
以下程序创建并打开名为 myfile.txt 的文件,并在此文件中写入文本 “Welcome to Cankaoshouce.com”。接下来,程序读取文件并将数据存储到名为 info 的缓冲区中。最后,它显示存储在 info 中的文本。
1 | section .text |
内存管理
内核提供 sys_brk() 系统调用,用于分配内存,而无需稍后移动内存。此调用在内存中应用程序映像的正后方分配内存。此系统功能允许您设置数据段中的最高可用地址。
此系统调用采用一个参数,这是需要设置的最高内存地址。该值存储在 EBX 寄存器中。
如果出现任何错误,sys_brk() 返回 -1 或返回负错误代码本身。下面的实例演示了动态内存分配。
栗子:
以下程序使用 sys_brk() 系统调用分配 16kb 内存:
1 | section .text |
内联汇编(c)
基础知识
GCC使用AT&T/UNIX汇编语法。其与Intel语法区别较大,主要区别有:
-
源-目标顺序
- Intel:
Op-code dst src - AT&T:
Op-code src dst
- Intel:
-
寄存器命名
- AT&T以
%为前缀,如:使用eax写作%eax。
- AT&T以
-
立即操作数
- 立即操作数以
$开头,对staic “C”变量也前置$。16进制常量. - AT&T立即数的前缀为
0x - Intel语法后缀
h - 所以对于16进制数,我们会先看到
$,然后是0x,最后是常量(AT&T语法结构)。
- 立即操作数以
-
操作数大小
- AT&T语法中操作数大小取决于操作码最后一个字符。操作码后缀
b,w,l对应 byte(8-bit), word(16-bit), 和 long(32-bit)。 - Intel语法中,通过在操作数(非操作码)前缀
byte ptr,word ptr, 和dword ptr实现该功能。 - 因此, Intel 之
mov al, byte ptr foo即movb foo, %al于 AT&T.
- AT&T语法中操作数大小取决于操作码最后一个字符。操作码后缀
-
内存操作数
-
Intel语法中基址寄存器(The base register)内于
[、]之间 -
而AT&T于
(、)之间。 -
此外,间接内存引用(indirect memory reference)Intel风格为
section:[base + index*scale + disp],改变为section:disp(base, index, scale)于 AT&T. -
需指出,当常量使用disp/scale,
$无需前置。Intel Code AT&T Code mov eax,1movl $1,%eaxmov ebx,0ffhmovl $0xff,%ebxint 80hint $0x80mov ebx, eaxmovl %eax, %ebxmov eax,[ecx]movl (%ecx),%eaxmov eax,[ebx+3]movl 3(%ebx),%eaxmov eax,[ebx+20h]movl 0x20(%ebx),%eaxadd eax,[ebx+ecx*2h]addl (%ebx,%ecx,0x2),%eaxlea eax,[ebx+ecx]leal (%ebx,%ecx),%eaxsub eax,[ebx+ecx*4h-20h]subl -0x20(%ebx,%ecx,0x4),%eax
-
[!important]
- 内联是什么?
我们可以指导编译器将函数的代码直接插入调用的位置,这类函数叫做内联函数。
- 内联函数有什么好处?
内联的方法降低了函数调用的问题。而且如果任何参数是常量的话,在编译器将得到明显优化,而不是所有的内联函数代码都被包含。代码量会更少,取决于具体的情况。为了定义内联函数,我们使用关键字
inline声明。
- 什么是内联汇编?
内联汇编是写在内联函数中的汇编过程(assembly routines)。它非常方便、快速,在系统编程中非常有用。我们主要关注学习GCC内联汇编函数的基础格式和用法。要声明内联汇编函数,我们使用关键字
asm。
基本内联汇编
基本内联汇编语法如下:
1 | asm asm_qualifiers ( AssembleInstructions ) |
- asm:asm不是 ISO C 中的关键字,如果我们开启了
‑std=c99等启用 ISO C 的编译选项,代码将无法成功 编译。然而,内联汇编对于许多 ISO C 程序是必须的,GCC 通过__asm给程序员开了个后门。使用__asm替代 asm 可以让程序作为 ISO C 程序成功编译。volatile 和 inline 也有加__的版本。 - asm_qulifiers包括以下两个修饰符:
- volatile: 指示编译器不要对 asm 代码段进行优化
- inline: 指示编译器尽可能小的假设 asm 指令的大小
- AssembleInstructions是我们手写的汇编指令。
基本内联汇编的例子如下:
1 | __asm__ __valatile__( |
编译器不解析 asm 块中的指令,直接把它们插入到生成的汇编代码中,剩下的任务有汇编器完成。 这个过程有些类似于宏。为了避免我们手写的汇编代码挤在一起,导致指令解析错误,通常在每一条 指令后面都加上\n\t获得合适的格式。
编译器不解析 asm 块中的指令的一个推论是:GCC 对我们插入的指令毫不知情。这相当于我们人为 地干涉了 GCC 自动的代码生成,如果我们处理不当,很可能导致最终生成的代码是错误的。考虑以下代码段:
1 |
|
运行结果为
1 | sum = 55 |
反汇编代码如下:
1 | .file "basic-asm.c" |
可以看到在 for body 中,变量i被分配到-16(%rbp)中,我们在sum += i前插入这段代码来验证 基本内联汇编的处理过程。
1 | __asm__ __volatile__( |
此时,反汇编代码如下:
1 | .file "basic-asm.c" |
运行结果为
1 | sum = 100 |
拓展内联汇编
基本原理和思路
在编译器生成代码的过程是一个动态的过程:
- 变量可能被分配到寄存器(如 rax)中,也可能被分配 到内存中;
- 一个整型字面值可能是 32 位立即数,也可能是 64 位大立即数;
- 可能使用 rax 寄存器,也可 能使用 rbx 寄存器。
程序员任何擅自的篡改都会导致生成错误的代码。
拓展内联汇编从程序员处获取信息,并根据获取的信息调整自己生成代码的行为。比如,程序员要求 将某个变量分配到 rax 寄存器中,编译器就会将该变量分配在 rax 中,并调整其他部分的代码,使程 序员的要求不影响正确代码的生成。
因此,使用拓展内联汇编的基本思路就是:提供尽可能多的信息给编译器。程序员提供的信息越多, 出错的概率就越小。除了提供信息,程序员还应该清楚地明白 GCC 对内联汇编做的假设和限制。
语法结构
基本汇编中我们只有指令。在扩展汇编中,我们可以指定操作对象(operand)。它允许我们指定输入寄存器,输出寄存器及一列受影响(clobbered)寄存器。它不是mandatory to指定寄存器使用,我们可以将麻烦留给GCC而GCC有可能更好的适配GCC的优化机制。
1 | asm asm-qualifiers ( |
- asm、asm-qualifiers和基本内联汇编基本相同。基本内联汇编提供了在汇编中跳转到 C Label 的能力,因此asm_qualifiers中增加了 goto。goto 修饰符只能用于第二种形式中。
- Assembler Template Code是程序员手写的汇编指令,但是增加了几种更方便的表示方法。 可以将拓展内联汇编 asm 块看成一个黑盒,我们给一些变量、表达式作为输入,指定一些变量作为 输出,指明我们指令的副作用,运行后这个黑盒会按照我们的要求将结果输出到输出变量中。
- 使用冒号分割汇编模板、输出操作数组、输入操作数组、clobbered寄存器组,使用逗号分割每个组内的操作数,如果没有输出操作数,但是有两个输入操作数,那么就需要放置两个连续的冒号
- Output Operands表示输出变量,
- Input Operands表示输入变量,
- Clobbers表示副作用(asm 块中可能修改的寄存器、内存)等。
栗子:
1 | int a=10, b; |
Assembler Template
汇编模板包含一组嵌入到C程序中的指令。格式类似:或者每个指令包围在双引号中,或整组指令包含在双引号中。每个指令也应该以一个分隔符结束。合法的分隔符可以是\n和;。\n可以跟随一个\t。C表达式的操作数呈现为 %0, %1 …等。
Operands
每个操作数首先写作一个双引号内的操作数限制符(operand constraint,可选择性填写)。然后跟随操作数对应的 C 表达式 。 即,"constraint" (C expression) 。对输出操作数会有一个额外的修饰符。限制符(constraint)主要用于决定操作数的地址模式。他们也被用于指定要使用的寄存器。
如果我们使用超过一个操作数,以逗号,分隔。
[!important]
在汇编模板中,每个操作数按数字被引用。数字按如下规则排列。如果有n个操作数(包括输入、输出),那么第一个输出操作数是数字
0,连续增加,最后一个输入操作数是数字n-1。最大操作数数量如上一段所述。
输出操作数表达式必须是lvalues(32-bit)。输入操作数无此限制。他们必须是表达式。扩展汇编功能是最常用于编译器自身不知晓的机器指令)。如果输出表达式无法被直接寻址(addressed)(比如,它是一个bit-field),我们限制符必须“允许”(allow)一个寄存器。在那种情况下,GCC将使用该寄存器为asm的输出,然后将寄存器内容存储到输出。
如上所述,原始输出操作数必须是只写的;GCC将假设那个操作对象中的值在指令前已失效且无需生成。扩展汇编也支持“输入-输出”或“读-写”操作数。
我们现在看一些例子。我们希望将一个数乘以5。对此我们使用lea指令。
1 | asm ("leal (%1,%1,4), %0" |
此处我们的输入是x。我们没有指定使用哪个寄存器。GCC会为输入选择一些寄存器用来输入,一个用来输出,执行我们的要求。如果我们希望输入和输出放在(reside)同一个寄存器中,我们可以让GCC来实现。这里我们使用那种"读-写"操作数,通过指定合适的限制符,这里我们来实现它:
1 | asm ("leal (%0,%0,4), %0" |
现在输入和输出操作数在同一个寄存器内了。但我们不知道是哪个寄存器。现在如果我们也想要指定,有一个办法:
1 | asm ("leal (%%ecx,%%ecx,4), %%ecx" |
以上三个例子中,我们没有把任何一个寄存器放在受影响列表中。为什么?前两个例子中,GCC决定使用哪个寄存器,因此知道发生了什么改变。在最后一个中,我们不需要将ecx放在受影响列表中,gcc知道它会放入x中。因为它可以知道ecx的值,它不会被视为受影响的。
Clobber List
一些指令会影响一些硬件寄存器。我们必须在受影响列表中列出那些寄存器,即asm函数第三个:后的区域。这用于指示gcc我们将使用并修改它们。所以gcc将不会假设它加载到这些寄存器中的值是合法的。我们不应该列出输入和输出寄存器。因为gcc知道asm使用它们(因为它们被明确指定为限制符(constraints))。如果指令使用了任何其他寄存器,显式或隐式的(并且这些寄存器没有出现在输入和输出列表上),那么那些寄存器必须在受影响列表中指定。
如果我们的指令可以修改条件码寄存器(the condition code register),我们必须增加cc到受影响寄存器列表。
如果我们的指令用一个不可预期的方法(fashion)修改了内存,添加memory到受影响寄存器。这会使GCC在汇编指令期间不在寄存器内保持内存值的缓存。我们也必须添加**volatile**关键字,如果内存影响(memory affected)未列在asm的输入和输出中。
我们可以读写受影响寄存器任意多次。注意模板中乘法指令的例子;它假设子过程(subroutine) _foo 接受eax 、ecx寄存器中的参数。
1 | asm ("movl %0,%%eax; movl %1,%%ecx; call _foo" |
[!note]
volatile(不稳定的)
如果你熟悉内核源码或者一些类似的优美代码,你必然已见过很多函数声明为
volatile或__volatile__,跟随在__asm__之后。我之前提到过关于关键字asm和__asm__。所以什么是volatile?如果我们的汇编语句必须在我们放置它的地方执行,(即,必须不被作为一个优化而移出循环),则将
volatile放在asm之后。所以防止它被移动、删除和任何改变,我们如此声明asm volatile(... : ... : ... : ...);当我们必须非常小心时,使用__volatile__。如果我们的汇编只是做一些计算而没有任何副作用,最好不要使用
volatile关键字。忽略它将帮助GCC优化代码使其更优美。
constraints
限制符修饰符
当使用限制符时,若要精确控制其效果,GCC提供了修饰符。常用当有:
=: 意味着操作数对该指令是只写的;前一个值将被忽略并替换为输出数据。&: 意味着操作数是一个早期受影响的操作数,也就是在指令结束前已被修改。因此,该操作数不可停留在输入寄存器中或任何内存中。在被写入前仅用于输入的输入操作数可设为一个早期受影响操作数 (An input operand can be tied to an earlyclobber operand if its only use as an input occurs before the early result is written)。
寄存器操作数限制符
当操作数指定使用此限制符时,它们会存储在常规寄存器中(General Purpose Registers(GPR))。如:
1 | asm ("movl %%eax, %0\n" |
此处myval变量保存在一个寄存器中,eax的值会复制到那个寄存器,而myval的值会从这个寄存器中更新到内存。当"r"限制符被指定后,gcc可以在任何可用的GPR中保存这个变量。要指定该寄存器,你必须使用特定寄存器限制符指定寄存器名称。它们是:
| 限制符 | 作用寄存器 |
|---|---|
| r | Register (s) |
| a | %eax, %ax, %al |
| b | %ebx, %bx, %bl |
| C | %ecx, %cx, %cl |
| d | %edx, %dx, %dl |
| S | %esi, %si |
| D | %edi, %di |
内存操作数限制符
当操作数是在内存中时,那么任何在它上的操作将直接在内存位置进行。而寄存器限制符,则优先存于寄存器而后修改再写回内存。但寄存器限制符通常只在指令必需或者明显提升性能时使用。当C变量需在asm中修改且无需寄存器保持其值时,内存限制符可最大化性能。如,将idtr的值存储于loc的内存位置中:
1 | asm("sidt %0\n" : :"m"(loc)); |
匹配(数字)限制符
有时,一个单独变量既是输入也是输出操作符,这时可使用匹配限制符。
1 | asm ("incl %0" :"=a"(var):"0"(var)); |
我们在操作数一节看到了类似的例子,在这个例子中寄存器%eax既是输入也是输出变量。var输入读入%eax并更新到%eax最后在自增后存入var。这里的"0"指定了和输出变量一样的第0个限制符。也就是说,它指定了var的输出过程应该只存于%eax中。这类限制符可用于:
- 输入输出是统一变量,或变量被修改并被写会同一变量时。
- 将输入和输出操作符分开是不必要的时候。
其他限制符
m: 接受内存操作数,任意的机器支持的地址。o: 接受内存操作数,只接受偏移地址(offsettable)。即对某个合法地址添加一个微小的偏移量。V: 非偏移内存操作数。换句话说,任何符合"m"但不符合"o"限制符的地址。i: 立即整型操作数,允许在编译期(assembly-time)可知常量符号。n: 立即整型操作数,允许已知数字值。许多系统不支持小于16-bit的(word wide)编译期(assembly-time)常量作为操作数。这些操作数应该使用n而不是i。g: 任何寄存器,内存或立即整型操作数都可用,要求寄存器不是常规寄存器(general registers)。
x86限定:
r: Register operand constraint, look table given above.q: Registers a, b, c or d.I: Constant in range 0 to 31 (for 32-bit shifts).J: Constant in range 0 to 63 (for 64-bit shifts).K: 0xff.L: 0xffff.M: 0, 1, 2, or 3 (shifts for lea instruction).N: Constant in range 0 to 255 (for out instruction).f: Floating point registert: First (top of stack) floating point registeru: Second floating point registerA: Specifies thea’ ord’ registers. This is primarily useful for 64-bit integer values intended to be returned with thed’ register holding the most significant bits and thea’ register holding the least significant bits.
栗子
1 | /* Assembly function to jump execution to a location */ |
在C语言中,关键字naked使得拓展汇编写法更加简洁,使用 naked 属性表示这个函数不需要标准的函数序列,如保存返回地址或帧指针,也不需要进行常规的参数传递。因此,函数的实现完全依赖于汇编,省略了通常的输入/输出约束,直接操作寄存器中的值。
- 第一个参数 (
SP) 被传递到r0寄存器。 - 第二个参数 (
RH) 被传递到r1寄存器。
[!tip]
*使用Naked之后:
禁用栈帧: 使用
naked后,编译器不会为函数生成栈帧,因此栈指针(SP)不会被修改,寄存器r0和r1的值可以直接传递到汇编指令中使用,而无需在函数内部处理栈。适用于嵌入式和裸机编程: 例如在启动代码中,
naked常常用于设定堆栈指针并进行跳转,或者在中断服务程序中,编译器生成的栈操作和局部变量等会占用不必要的空间,所以通常会使用naked来省略这些操作。裸函数的注意事项:
- 由于没有自动保存寄存器和栈帧,你需要显式地管理这些。否则,寄存器的值会丢失,函数调用栈可能会被破坏。
- 如果函数需要返回值或调用其他函数,开发者需要手动控制堆栈和返回地址。