AUTOASR
参考链接
CAN BusOff相关知识点_busoff基础知识-CSDN博客
CAN Busoff原理/快慢恢复介绍以及利用Vector VH6501 CAN干扰仪经典CAN2.0/CANFD帧触发Busoff_网络_汽车电子助手-GitCode 开源社区
CANalyzer及CANOE使用六:VH6501干扰仪的使用(busoff多种干扰/短路/采样点)_基于vh6501的can干扰测试-CSDN博客
AUTOSAR Layered Software Architecture
以下内容多基于标准文件及墨客博客 (xcnm.net)的博客加上我自己的理解写的,感兴趣可以去看原博客及标准文件。
常见缩写
详细请参见AUTOSAR_TR_BSWModuleList.xls
基础电子与控制单元
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| ECU | Electronic Control Unit | 电子控制单元(如发动机ECU、车身ECU等) |
| MCU | Microcontroller Unit | 微控制器(ECU的核心芯片) |
| VCU | Vehicle Control Unit | 整车控制器(新能源汽车核心) |
| BCM | Body Control Module | 车身控制模块(灯光、门窗等) |
| ECM/PCM | Engine Control Module / Powertrain Control Module | 发动机控制模块 / 动力总成控制模块 |
| TCM | Transmission Control Module | 变速箱控制模块 |
| ABS | Anti-lock Braking System | 防抱死制动系统 |
| ESP/ESC | Electronic Stability Program / Electronic Stability Control | 电子稳定程序/控制系统 |
| EPS | Electric Power Steering | 电动助力转向系统 |
自动驾驶与辅助驾驶
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| ADAS | Advanced Driver Assistance Systems | 高级驾驶辅助系统 |
| AD | Autonomous Driving | 自动驾驶 |
| L0-L5 | Level 0-5 (Automation Levels) | 自动驾驶等级(0级无自动化到5级完全自动驾驶) |
| ACC | Adaptive Cruise Control | 自适应巡航控制 |
| AEB | Automatic Emergency Braking | 自动紧急制动 |
| LKA | Lane Keeping Assist | 车道保持辅助 |
| APA | Automatic Parking Assist | 自动泊车辅助 |
| FSD | Full Self-Driving (Tesla) | 完全自动驾驶(特斯拉术语) |
| LiDAR | Light Detection and Ranging | 激光雷达(环境感知传感器) |
| RADAR | Radio Detection and Ranging | 雷达(毫米波雷达等) |
| CV | Camera Vision System | 视觉摄像头系统 |
通信与网络
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| CAN | Controller Area Network | 控制器局域网(车内低速/中速通信总线) |
| CAN FD | Controller Area Network with Flexible Data-Rate | 灵活数据速率CAN(高速高带宽) |
| LIN | Local Interconnect Network | 本地互联网络(低成本低速总线) |
| FlexRay | FlexRay Communication System | FlexRay通信系统(高可靠性实时总线) |
| Ethernet | Automotive Ethernet | 汽车以太网(高速通信,如100BASE-T1/1000BASE-T1) |
| V2X | Vehicle-to-Everything | 车对外界信息交换(V2V、V2I、V2P等) |
| DoIP | Diagnostics over Internet Protocol | 基于IP的诊断协议 |
| SOME/IP | Scalable service-Oriented Middleware over IP | 基于IP的面向服务中间件 |
软件与架构
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| RTE | Runtime Environment | 运行时环境(AUTOSAR架构核心) |
| BSW | Basic Software | 基础软件(AUTOSAR架构中的底层软件) |
| MCAL | Microcontroller Abstraction Layer | 微控制器抽象层(BSW的底层模块) |
| ECUAL | ECU Abstraction Layer | ECU抽象层(BSW的中间层) |
| OS | Operating System | 操作系统(如QNX、Linux、VxWorks) |
| OTA | Over-the-Air | 远程在线升级(软件更新) |
| HMI | Human-Machine Interface | 人机交互界面(如中控屏、仪表盘) |
| FOTA/SOTA | Firmware/Software Over-the-Air | 固件/软件远程升级 |
| API | Application Programming Interface | 应用程序编程接口 |
新能源汽车相关
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| BMS | Battery Management System | 电池管理系统(监控电池状态) |
| MCU | Motor Control Unit | 电机控制器(控制驱动电机) |
| OBC | On-Board Charger | 车载充电机(交流充电) |
| DCDC | DC-DC Converter | 直流转换器(高压转低压) |
| HV | High Voltage | 高压(如高压电池、电机系统) |
| LV | Low Voltage | 低压(如12V/24V车载系统) |
| EV | Electric Vehicle | 电动汽车 |
| HEV | Hybrid Electric Vehicle | 混合动力汽车 |
| PHEV | Plug-in Hybrid Electric Vehicle | 插电式混合动力汽车 |
| FCEV | Fuel Cell Electric Vehicle | 燃料电池电动汽车 |
诊断与标准
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| DTC | Diagnostic Trouble Code | 诊断故障码 |
| UDS | Unified Diagnostic Services | 统一诊断服务(ISO 14229标准) |
| ISO | International Organization for Standardization | 国际标准化组织(如ISO 15031诊断标准) |
| AUTOSAR | Automotive Open System Architecture | 汽车开放系统架构(软件标准化协议) |
| ASPICE | Automotive Software Process Improvement and Capability Determination | 汽车软件过程改进与能力测定(软件质量标准) |
| DCM | Diagnostic Communication Manager | 诊断通信管理器 |
其他重要缩写
| 缩写 | 英文全称 | 中文含义 |
|---|---|---|
| EEPROM | Electrically Erasable Programmable Read-Only Memory | 电可擦除可编程只读存储器 |
| FLASH | Flash Memory | 闪存(存储程序和数据) |
| PWM | Pulse Width Modulation | 脉冲宽度调制(电机/灯光控制等) |
| ADC | Analog-to-Digital Converter | 模数转换器(模拟信号转数字) |
| DAC | Digital-to-Analog Converter | 数模转换器(数字信号转模拟) |
| LIN | Local Interconnect Network | 本地互联网络(低成本低速总线) |
概览
架构分层
[!tip]
AutoSAR要求整个软件有着严格得分层。AutoSAR分层软件架构如下:
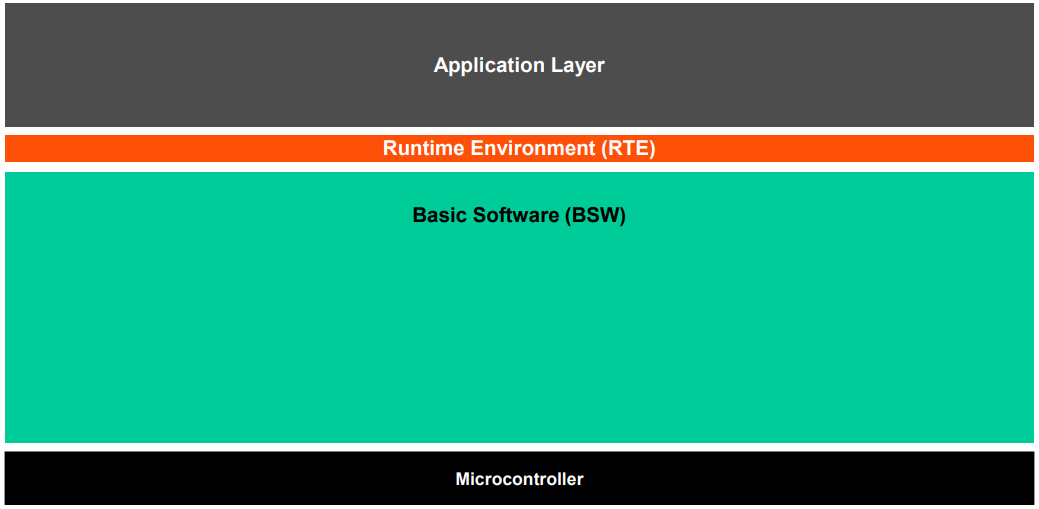
显而易见,AutoSAR软件架构自上而下分成了APP, RTE, BSW三层,至于那个Microcontroller指的是芯片MCU硬件,不属于软件。
- Application Layer(APP):这一个层就是大家常说的APP了,属于控制策略层,实现算法。
- Runtime Environment(RTE):这一层就是起到承上启下的作用,作为一个接口无缝连接APP和RTE,并且还要为APP层SWC之间提供通信。RTE层的代码都是通过工具链配置生成的。
- Basic Software(BSW):这一层叫做基础软件层,它最大的功能就是隔绝APP和控制器的关系,并且为APP提供一系列服务。是整个软件架构中占比最大的一部分,大部分代码都是通过工具链配置生成的,只有一些特殊的一小部分需要自行实现,这一部分被称为Complex Driver。
BSW层和MCU息息相关,并且还包含了大量的一些知名协议栈,比方说什么UDS,XCP,TCP/IP等等。下图显示BSW的组成部分:
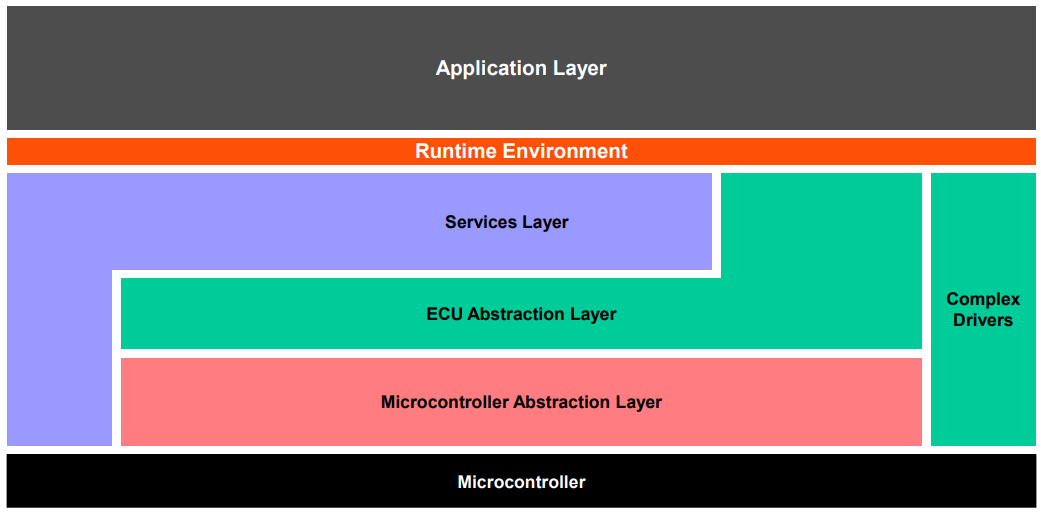
可以看到BSW分成了服务层,ECU 抽象层, 微控制器抽象层和复杂驱动四个部分。
-
微控制器层
MCU抽象层,它位于BSW的最底层,这一层其实就是我们经常说的MCAL层,这一层的作用就是将MCU资源抽象化,让上层程序的开发与MCU无关。举个例子,上层程序想通过CAN发个消息,只需要调用MCAL的消息发送接口Can_Write即可将消息成功发送出去,而不需要考虑它是通过中断还是轮询的方式发送。其实说白了MCAL就是MCU原厂针对AOTUSAR软件架构要求定制的一套底层MCU驱动,可以理解成为是AOTUSAR里面的MCU SDK驱动包。MCAL都是由MCU原厂提供源码,EB提供配置工具。
早些年,MCAL都是要收费的,因为当时MCU原厂对一款MCU不仅要提供免费版的常规SDK包,还要提供收费版的AOTUSAR MCAL包,但是随着AOTUSAR的普遍应用,现在的MCAL基本上都是免费了。在这里不得不提一下NXP的做法,NXP为了省事,它将MCAL和常规SDK包融合了一起,而融合的方法就是在SDK包的基础上根据AOTUSAR的接口要求又封装了一层,强行AOTUSAR化,NXP将这种特殊的MCAL包称为RTD。
-
ECU抽象层
ECU抽象层,它位于MCAL的上层,这一层的作用是让ECU的硬件设计抽象化,让上层程序的开发与ECU硬件设计无关。举个例子,上层程序需要通过ADC获取电源输入电压,它根本不需要考虑什么电阻分压转换什么,因为将ADC的寄存器值转化成真实的电源输入电压,这一部分的工作已经由ECU抽象层完成。经过ECU抽象层,让上层程序基本上脱离了硬件。
-
服务层
服务层,它位于ECU抽象层的上面,上面提到了经过了ECU抽象层,已经大致让上层软件大致脱离了硬件,所以服务层更多的则是纯纯的软件,为APP提供相关服务和OS调度,比方说常见的UDS诊断,XCP,网络管理,通信服务等等都属于服务层。
-
复杂驱动
复杂驱动,也就是经常所说的CDD,这一部分比较特殊,它自成一派,毕竟AOTUSAR不是万能的,它定义的那些标准模块不可能满足所有的应用需求,所以就有了复杂驱动,它是为了实现一些特殊的传感器和执行器功能,还有一些对控制时序有特殊要求功能需求场合,比方说喷油控制,胎压监测等。
在一个ECU中,通常会有几大常见功能,比如存储功能,信息安全,通信功能等待,而AUTOSAR不同的层又根据功能划分了很多功能模块,如下图所示。看名字其实就大概猜到了每一个功能模块负责什么。
当然,还可以通过服务类型划分,如下图所示:
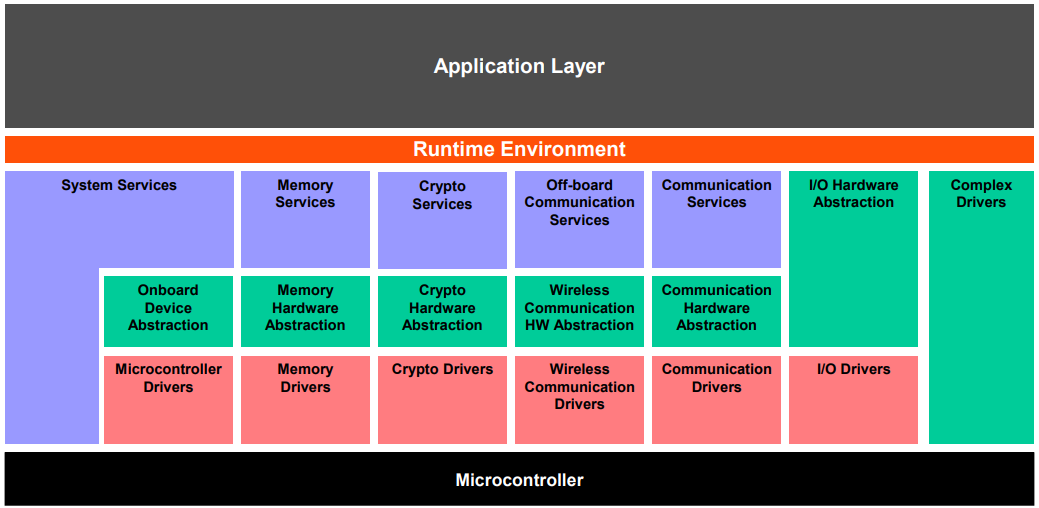
由图可以分为以下几类:
- 输入输出类:标准化访问传感器、执行器和 ECU 车载外设
- 内存:标准化访问内外部存储器(非易失性存储器)
- 加密:标准化访问密码学原语,包括内部/外部硬件加速器 ICA
- 通信:标准化访问:车辆网络系统、ECU 车载通信系统及 ECU 内部软件
- 车外通信:标准化访问:车辆至 X 通信、车内无线网络系统、ECU 车外通信系统
- 系统:提供可标准化的(作系统、定时器、错误内存)及 ECU 专属服务和库功能
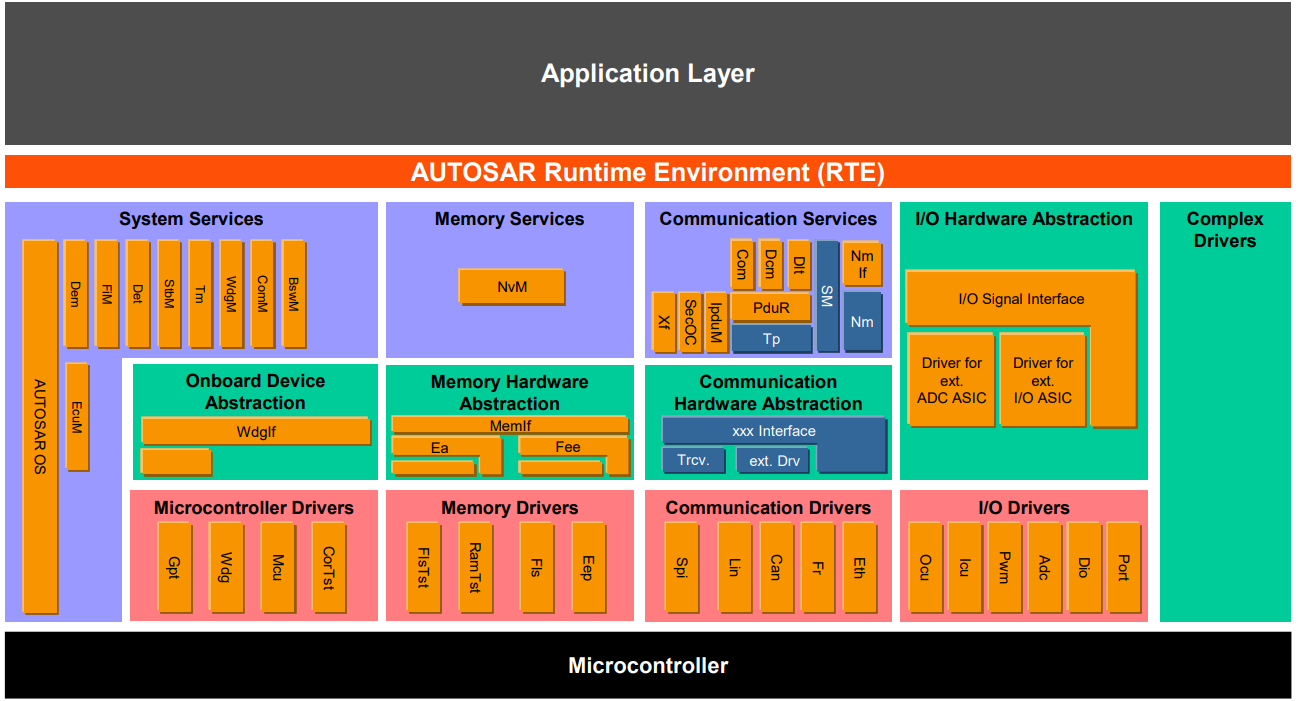
将所有的功能展开,最终得到以下框图:
OSI模型
| Applicability | OSI 7 layers | Vehicle- manufacturer- enhanced diagnostics | Legislated OBD (on-board diagnostics) | == | Legislated WWH-OBD (on-board diagnostics) | == |
|---|---|---|---|---|---|---|
| Seven layers according to ISO/IEC 7498-1) and ISO/IEC 10731 | 应用层 (第7层) |
ISO 14229-1, ISO 14229-3 |
ISO 15031-5 | == | ISO 27145-3 ISO 14229-1 |
== |
| : | 表示层 (第6层) |
Vehicle manufacturer specific | ISO 15031-2 ISO 15031-5 ISO 15031-6 SAEJ1930-DA SAEJ1979-DA SAE J2012-DA |
== | ISO 27145-2 SAE 1930-DA SAE J1979-DA SAE J2012-DA SAEJ1939:2011, Appendix C (SPN) SAE J1939-73:2010 Appendix A (FMI) |
== |
| : | 会话层 (第5层) |
ISO 14229-2 | == | == | == | == |
| : | 传输协议层 (第4层) |
ISO 15765-2 | ISO 15765-2 | ISO 15765-4 | ISO 15765-4 ISO 15765-2 |
ISO 27145-4 |
| : | 网络层 (第3层) |
: | : | : | : | : |
| : | 数据链路层 (第2层) |
ISO 11898-1 ISO 11898-2 ISO 11898-3 ISO 11898-5 or user defined |
ISO 11898-1 ISO 11898-2 |
: | ISO 15765-4 ISO 11898-1 ISO 11898-2 |
: |
| : | 物理层 (第1层) |
: | : | : | : | : |
功能安全
Autosar也为了功能安全在里面设计了很多机制和库函数,当然了,肯定都是软件层面上面的安全策略。大致可从下面几个方面来看:
- Memory Partitioning: 这个非常好理解,站在APP层说,就是让不同的SWC有不同运行权限,比方说可以配置SWC1只能进行运算,而SWC2可以访问寄存器资源。站在底层来说其实就是对MCU的Memory进行分区管理,即为MPU的应用。
- **E2E Protection:**End-to-End保护,这个也非常好理解,不管是外部不同ECU之间的通信,还是内部不同SWC之间的通信,都需要为保证信息在传输过程中的正确性,而AOTUSAR软件则提供了三种的E2E保护措施:
- CRC校验
- Sequence Counter:信息编号,防止漏和多
- Timeout:设置超时,给信息一个时限,这世界哪有一万年的爱啊。
- Timing Monitoring和Logic Supervison:这个方面主要是为了解决在系统运行过程中出现任务阻塞,任务死锁,活锁,任务执行时间超限等情况。主要安全策略差不多有两种,一个其实就是看门狗,AOTUSAR有个模块叫做Wdog Manger,可以监控某个任务有没有被卡死啊,卡死就报告,还有就是OS提供函数可以计算某段代码执行的时间有没有超限。
Communication stack
简介
模块
Communication stack包括以下三个大模块:
- Communication Service
- Communication Hardware Abstraction
- Communication Drivers
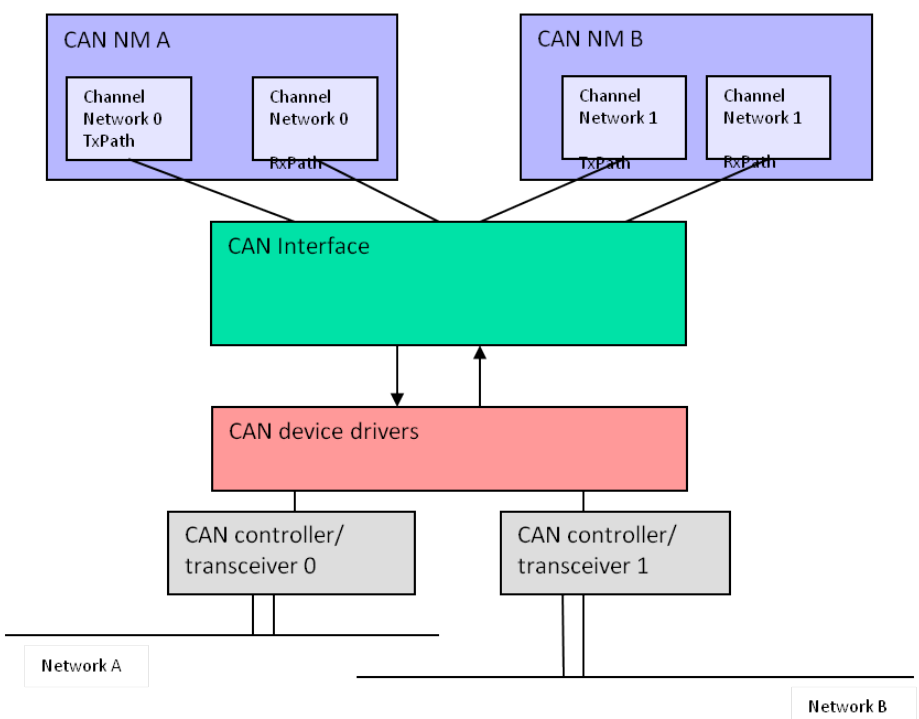
Communication Stack主要承载了ECU的通信功能,例举一下汽车电子通信网络中的几大总线,CAN, LIN, FlexRay,以太网。所以不难想象Communication Stack必须要针对这四大总线实现它们的驱动以及相关常见协议栈,比如说CAN的UDS,以太网的TCP/IP等。整个Communication Stack的结构如下图所示:
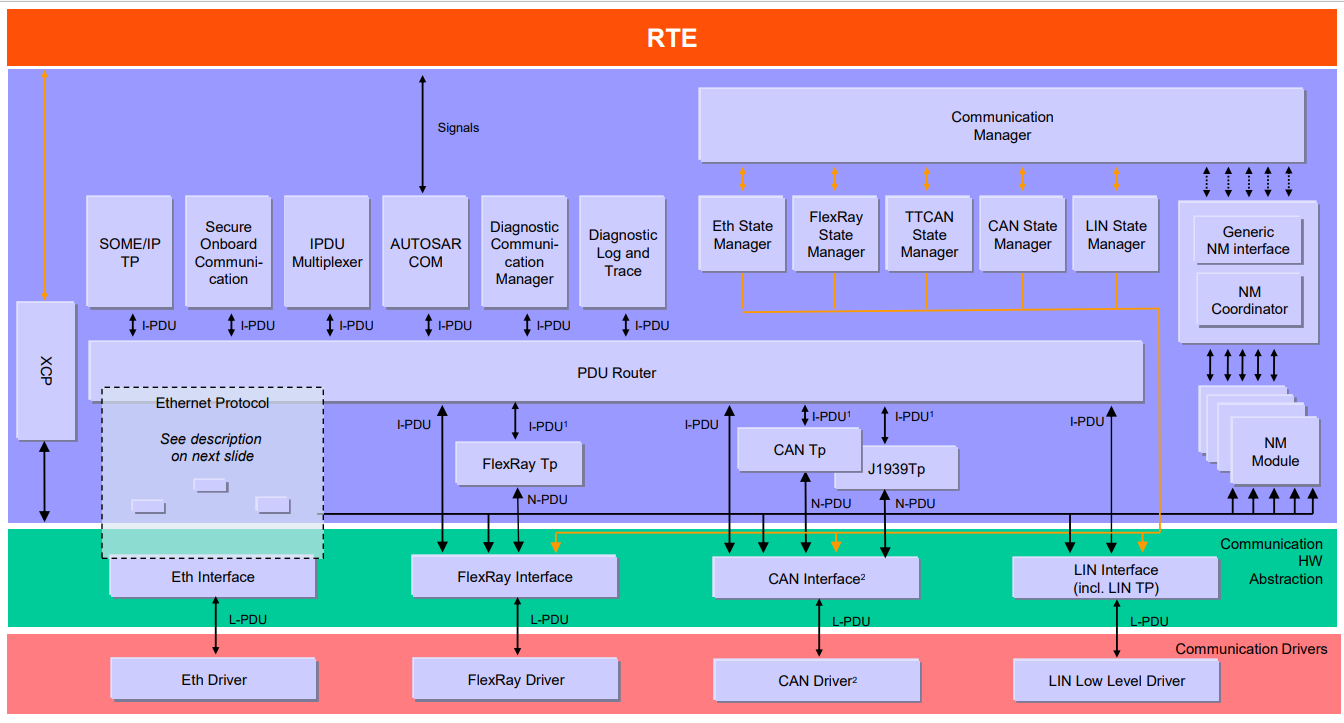
仔细观察四大总线的消息传递路径,可以发现在AUTOSAR架构中基本上都大同小异,对于接收消息而言,四大总线上的消息大多都是先由MCAL层中的Driver,然后传输到位于ECU抽象层的Interface,Interface层会根据消息类型进行分配最后再传输到该消息对应的服务层,对于发送则是一个相反的过程。
通信过程
Communication Stack所提供的服务,主要有两类:
-
一类主要负责通信数据的传输,主要有Com服务和Dcm服务,这两者主要负责ECU大量系统数据的传输。
-
Com服务主要负责传递来自APP层的消息,说简单点它就是把系统中的一些系统变量参数根据一定数据组合规则打包(或者解包),然后根据一定的时间/事件规则发送出去(或者接收进来)。Com服务中Can消息传递路径为:
graph TD subgraph 顶层模块 A[ ]:::orange B[ ]:::orange end C[Com]:::blue D[I-PDU]:::gray E[PduR]:::blue F[I-PDU]:::gray G[CanIf]:::green H[L-PDU]:::gray I[CanDrv]:::pink A --> C B --> C C --> D D --> E E --> F F --> G G --> H H --> I classDef orange fill:#FF7F50,stroke:#000,stroke-width:2px,width:40px,height:30px classDef blue fill:#87CEFA,stroke:#000,stroke-width:2px classDef gray fill:#D3D3D3,stroke:#000,stroke-width:2px classDef green fill:#98FB98,stroke:#000,stroke-width:2px classDef pink fill:#FFB6C1,stroke:#000,stroke-width:2px对于接收而言,MCAL层中的CanDrv接收到最原始的CAN报文后传输到CanIf模块,CanIf模块相当于是一个报文分类模块,它会根据CAN ID将CAN报文分类,然后传递到服务层的不同模块,比如图中的PduR模块。经过了CanIf模块后,这个时候原始CAN报文变换为服务层PDU。PduR功能为PDU路由,它会对PDU再次进行分类,随后将其传递到更上层的软件模块,比如Com模块。
-
Dcm服务主要实现了UDS诊断协议,接收来自外部的请求,并作出响应。Dcm服务中Can消息传递路径为:
graph TD A[Dcm]:::blue B[I-PDU]:::gray C[PduR]:::blue D[I-PDU]:::gray E[CanTp]:::blue F[N-PDUs]:::gray G[CanIf]:::green H[L-PDU]:::gray I[CanDrv]:::pink A --> B B --> C C --> D D --> E E --> F F --> G G --> H H --> I classDef blue fill:#87CEFA,stroke:#000,stroke-width:2px classDef gray fill:#D3D3D3,stroke:#000,stroke-width:2px classDef green fill:#98FB98,stroke:#000,stroke-width:2px classDef pink fill:#FFB6C1,stroke:#000,stroke-width:2px在Dcm服务中,对比Com服务,发现其有两个不同,第一个不同为Dcm服务与APP没有交集,因为Dcm就是UDS。第二个不同为在CanIf模块和PduR模块中多了一层CanTP模块,这个模块其实就是实现了ISO15765-2中描述的UDS on CAN的网络层。
-
-
另外一类则负责通信模式的管理,包括有SM模块和NM,这两者主要负责状态管理和网络管理。
- SM模块则是负责总线的状态管理,主要负责总线通信开启和关闭,另外还负责总线错误的检测和恢复。
- 而NM模块则负责总线的网络管理,基于总线报文协议控制ECU的睡眠和唤醒。
更为详细的通信过程如下:
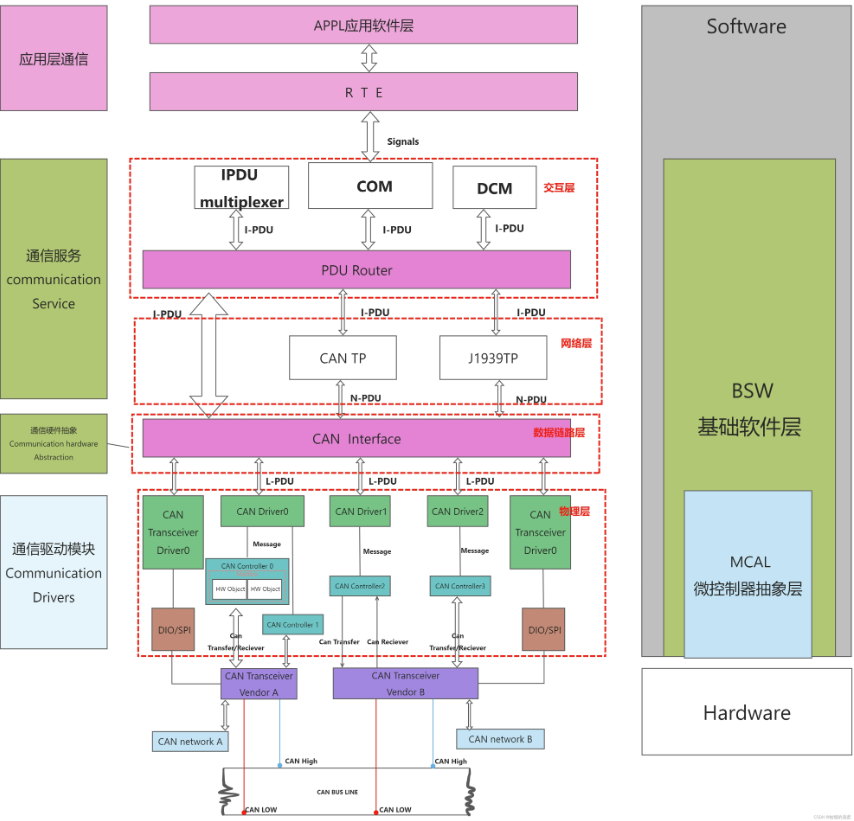
其中不同层的名词解释如下:
-
交互层
- IPDU multiplexer:协议数据单元复用模块
- COM:COMMUNICATION 通信模块
- DCM: 诊断通信管理模块(Diagnostic Comminication Manager)
- PDUR:Protocol Data Unit Router -PDU路由器
-
网络层:
- CAN TP: CAN Transport Layer
- CAN TP提供的服务包括: 传输方向的数据分割、接收方向的数据重组、 数据流控制、检测分割会话中的错误、传输取消接收取消
- J1939 TP:基于J1939协议的CAN TP,J1939Tp模块实现了SAEJ1939标准中的两种数据传输方式BAM和CMDT;
-
数据链路层:
- CAN Interface:CAN 接口层(CanIf)是访问CAN总线的标准接口;
-
物理层:
- CAN Driver: CAN 驱动;,可以实现对CAN控制器的初始化、发送/接收CAN报文、对接收报文的指示与对发送报文的确认、唤醒检测、溢出和错误处理等功能。
- CAN Controller: CAN控制器;
- CAN Transceiver Driver: CAN收发器驱动程序抽象了CAN收发器硬件。它为较高层提供了一个独立于硬件的接口。它利用MCAL层的api从ECU布局中抽象出来,访问CAN收发硬件。
-
硬件部分:
- CANTransceiver:CAN收发器,是一种硬件设备,可将CAN总线上使用的信号电平调整为微控制器识别的逻辑(数字)信号电平。此外,收发器还能够检测电气故障,例如布线问题,接地偏移或长主导信号的传输。根据与微控制器的接口,它们会标记由单个端口引脚汇总的检测到的错误或由SPI非常详细地标记出来
- CAN High: CAN总线高电平;
- CAN Low: CAN总线低电平;
- CAN network:AUTOSAR CAN网络管理是一个独立于硬件的协议,只能在CAN上使用。其主要目的是协调网络从正常运行到总线休眠模式的过渡。
-
传输数据类型:
-
signals:信号;
-
PDU:Protocol Data Unit 协议数据单元,PDU 由 SDU 和 PCI 组成
- PCI(Protocol Control Information,协议控制信息):控制信息(如CAN帧的标识符、DLC等)。
- SDU(Service Data Unit,服务数据单元):实际数据(如CAN帧的数据字段)。
字段 类型 说明 标识符 PCI 帧的ID和优先级 控制字段 PCI 数据长度(DLC) 数据字段 SDU 实际传输的数据(1-8字节) CRC、ACK等 PCI 错误检查和应答 -
I-PDU:Interaction Layer PDU,由 data、length、I-PDU ID 组成。
-
N-PDU:Network Layer PDU,或 I-PDU Segment,由传输协议模块使用,对 I-PDU 进行分段
-
L-PDU:Data Link Layer PDU,或 Large PDU,一个或多个 I-PDU 被打包成 L-PDU,L-PDU是基于总线的,例如 CAN 总线的 L-PDU 就是 CAN 帧;
-
Message:报文;
-
那么数据流的走向为:应用层–>RTE–>COM–>PDUR–>CANTP–>CAN Interface–>CAN Driver–>CAN controller–>CAN transceiver–>CAN BUS Line
- Com模块获取应用层的信号(Signal),经一定处理封装为IPDU(Interaction Layer Protocol Data Unit)发送到PduR模块;
- PduR根据路由协议中所指定的I-PDU目标接收模块,将接收到的I-PDU经一定处理后发送给CanIf;PduR也可以将部分I-PDU发送给CAN TP模块,处理之后再发送给CANIf;
- CanIf将信号以L-PDU(Data Link Layer Protocol Data Unit)的形式发送给CAN驱动模块;
- CAN 驱动模块将Message 报文发送给CAN controller;
- CAN controller 与外部硬件的CAN transceiver(CAN收发器)进行CAN 报文的收发;
- 外部硬件CAN收发器–CAN Transceiver Hardware主要工作内容为,接收CAN bus上的网络信息(通常叫做CAN Frame)相关的信号电平并将其转化为逻辑信息电平转发给CAN Controller,接收从CAN Controller传输过来的逻辑电平信息并将其转化为信号电平传从到CAN bus上。CAN Transceiver有两条线,一条连CAN总线的高电平,一条低电平;
CanIf
[!tip]
下图展示了Can模块所处的位置:
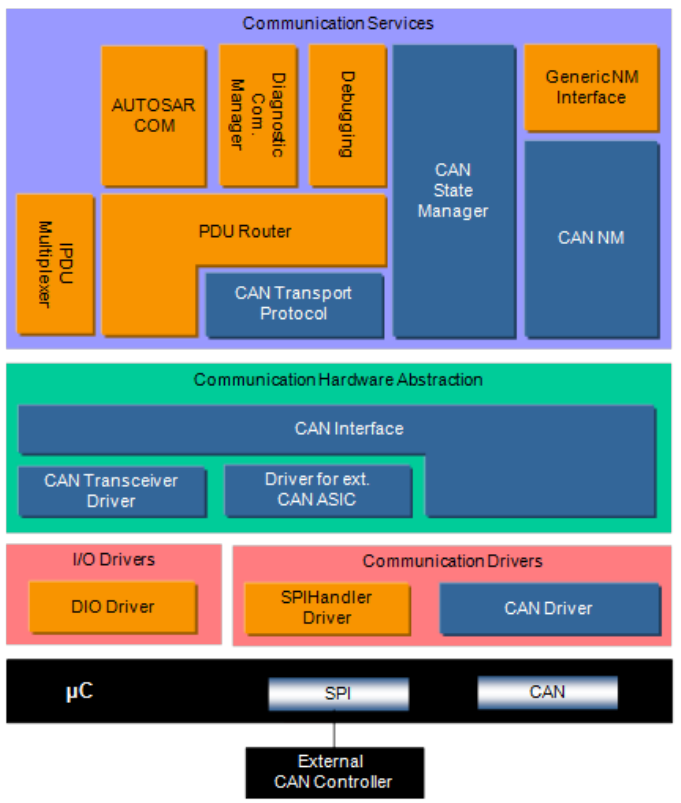
在MCAL层,看到了不仅仅有CanDriver, 还有SPI和I/O Driver,其中SPI针对的是那些需要外挂CAN controller的应用,除了外部CAN controller芯片需要IO来进行输入输出,有些特殊的CAN Tranceiver也需要IO来进行输入输出,比如经典的TJA1043,就有一个EN引脚和STB引脚,所以就需要IO Driver来控制。
CanIf模块位于MCAL层(CAN Driver)和上层通信服务层(如 CAN Network Management, CAN Transport Protocol 等)的中间,其充当 CAN Driver 和上层通信服务层的接口层。所以它位于BSW层中的ECU抽象层,为了让上层软件与ECU硬件设计无关。
CAN Interface 模块主要功能如下:
- 初始化
- 发送请求服务
- 发送确认服务
- 接收指示服务
- Controller 模式控制服务
- PDU channel mode 控制服务
CANIF可能应用在以下情景:
- 中断模式 CanDrv 处理由 CAN 控制器触发的中断。CanIf 是基于事件的,当事件发生时会被通知。在这种情况下,相关的 CanIf 服务在 CanDrv 对应的 ISR 中被调用。
- 轮询模式 CanDrv 由 SchM 触发并执行后续过程(轮换模式)。在这种情况下,必须在规定的时间区间内定期调用 Can_MainFunction_<写/读/总线关闭/唤醒/收发器>()。CanDrv 会通知 CanDrv 在某个 CAN 控制器中发生的事件(接收、传输、总线关闭、超时),与中断驱动作同样有效。CanDrv 负责更新属于 CAN 控制器中事件的对应信息,例如接收 L-PDU。
- 混合模式:中断驱动和轮询驱动的 CanDrv 功能可根据所用 CAN 控制器分为中断驱动和轮询驱动作模式。
与别的模块的关联性如下:
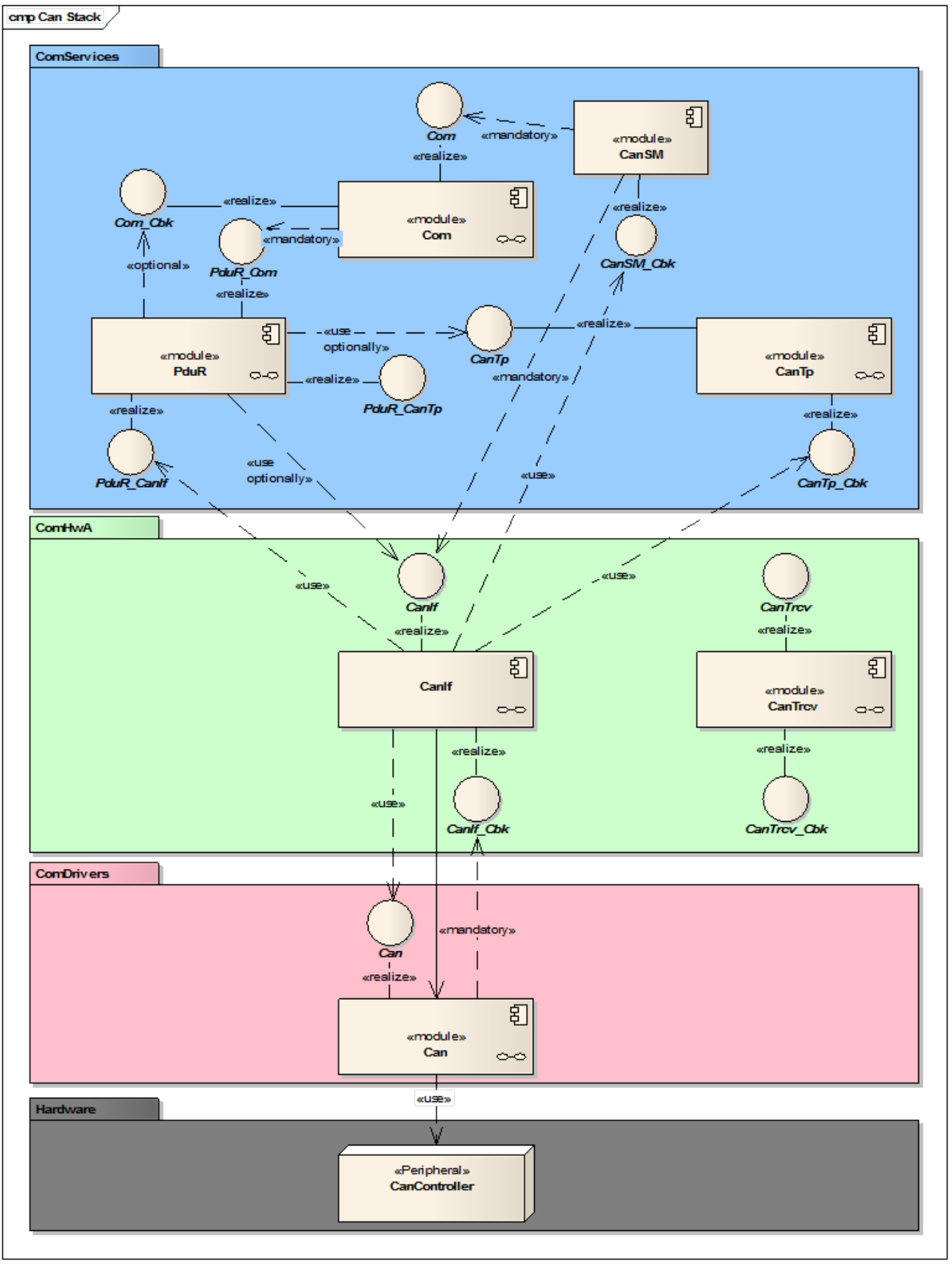
物理信道
一个物理信道通过一个 CAN 控制器和一个 CAN 收发器连接,而一个或多个物理信道可以连接到单一网络。CanIf 提供控制所有 CAN 设备(如 CAN 控制器和所有支持 ECU 通道的 CAN 收发器)的服务。这些 API 被 CanSm 用于向 ComM提供网络视图,用于对所有连接到单一网络的物理通道执行唤醒和睡眠请求。CanIf 分别将 CanDrv 和 CanTrcv 提供的状态信息传递给每个物理通道,作为 CanSm 的状态信息。
CanIf 将提供一个控制器Id,该 Id 从不同 CanDrv 实例的不同控制器中抽象出来。CanIf 内 ControllerId 的范围应以“0”开头。它应可通过 CanIfCtrlId.c()进行配置。
| Canlf | CanDrv A | CanDrv B |
|---|---|---|
| Controllerld 0 | Controller 0 | |
| Controllerld 1 | Controller 1 | |
| Controllerld 2 | Controller 0 |
CanIf 将提供一个收发器 Id,从不同 CanTrcv 实例的不同收发器中抽象出来。CanIF 内收发器的范围应以“0”开头。它应可通过 CanIfTrcvId.c() 进行配置。
| Canlf | CanDrv A | CanDrv B |
|---|---|---|
| TransceiverId 0 | Transceiver 0 | |
| TransceiverId 1 | Transceiver 1 | |
| TransceiverId 2 | Transceiver 0 |
在通知过程中,CanIf 会将原始 CAN 控制器或 CAN 收发器参数从驱动模块映射到 CanSm。这种映射是在引用的 CAN 控制器或 CAN 收发器参数被用抽象的 CanIf 参数 ControllerId 或 TransceiverId 配置时完成的。
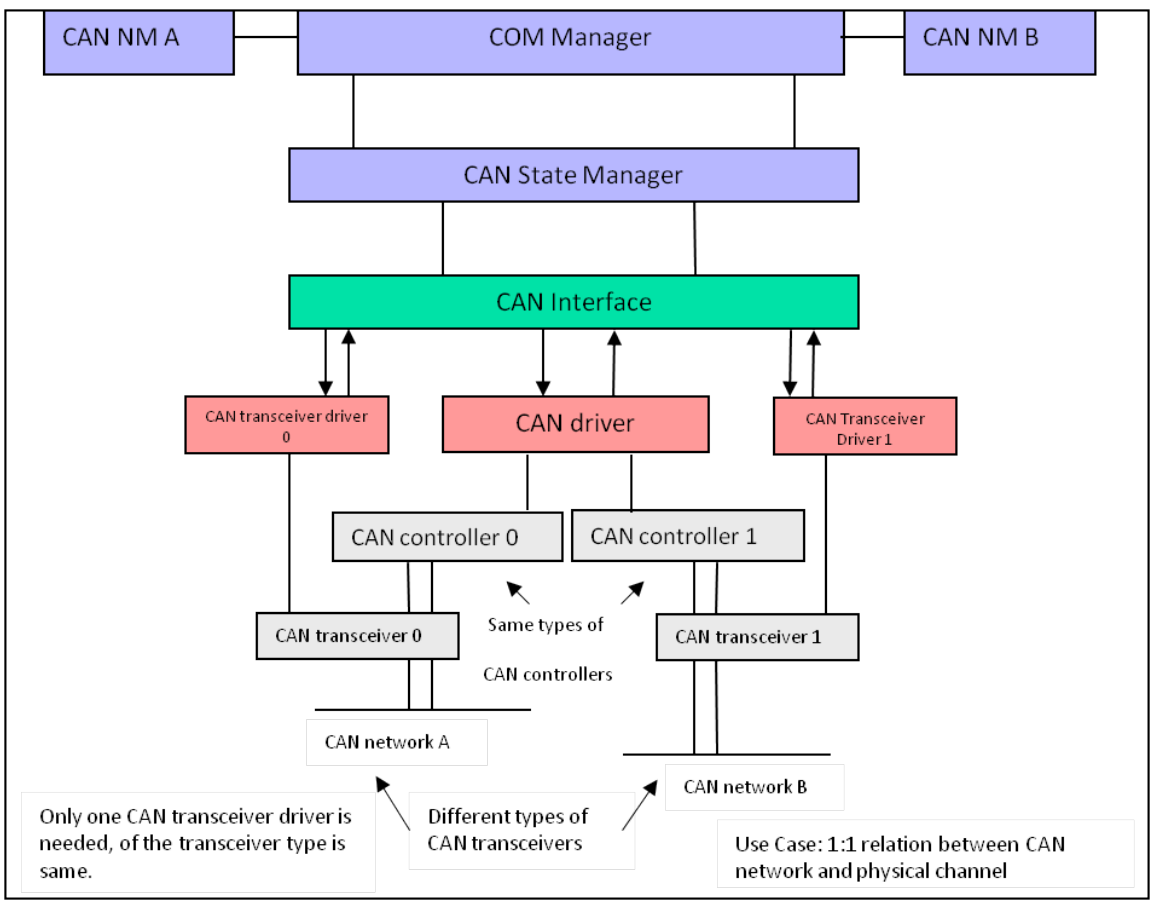
CanIf 支持多个物理 CAN 通道。这些必须通过网络控制的 CanSm 进行区分。CanIf API 为多个底层物理 CAN 通道提供请求和读取控制。
此外,CanIf 不区分专用类型的 CAN 物理层(即低速 CAN 或高速 CAN),不区分连接一个或多个 CAN 控制器的类型。
工作流
初始化
EcuM 调用 CanIf 的函数 CanIf_Init(),用于初始化整个 CanIf。在初始化过程中,所有全局变量和数据结构(包括标志和缓冲区)都会被初始化。EcuM 通过调用对应的初始化服务分别执行 CanDrvs 和 CanTrcvs 的初始化。
CanIf 期望 CAN 控制器在初始化过程完成后,保持在开机重置后停止状态。在此模式下,CanIf 和 CanDrv 既无法发送也无法接收 CAN L-PDU。
如果运行时需要重新初始化整个 CAN 模块,EcuM 应调用 CanSm,通过调用 CAN 接口模块的 API 服务 CanIf_SetControllerMode()启动 CAN 控制器所需的状态转换。CanIf 将 CanSm 的调用映射到相应 CanDrv 的调用。
发送请求
CanIf 的传输请求函数 CanIf_Transmit()是 CAN 网络上上层传输 L-PDU 的常用接口。上层通信层模块仅通过 CanIf 的服务发起传输,无法直接访问 CanDrv。如果 CanDrv 能够将 L-PDU 数据写入 CAN 硬件传输对象,则发送请求成功完成。上层模块使用 API 服务 CanIf_Transmit() 来发起传输请求。
CanIf_Transmit函数将会进行以下操作:
- 检查CanIf的初始化状态
- 识别CanDrv(仅在使用多个CanDrv时)
- 确定访问CAN硬件传输对象的HTH
- 调用CanDry的 Can_Write()函数
如果传输请求服务CanIf_Transmit()返回E_OK,则传输成功完成。
如果请求通过 PDU 信道模式传输 L-PDU,请求返回 CANIF_OFFLINE,CanIf 应向 DET 的 Det_ReportRuntimeError()服务报告运行时错误代码 CANIF_E_STOPPED,CanIf_Transmit()返回 E_NOT_OK
传输数据流
发射请求服务Canlf Transmit()基于L-PDU。访问L-SDU特定数据的参数如下:
- 发送L-PDU=>L-SDU ID
- 引用包含L-SDU相关数据的数据结构:指向L-SDU,指向元数据的指针和L-SDU长度。
对L-SDU数据结构的引用被用作多个Canlf API服务中的参数,例如Canlf Transmit()或回调服务<User_RxIndication>()。如果L-PDU配置为触发传输,则L-SDU指针为空指针。
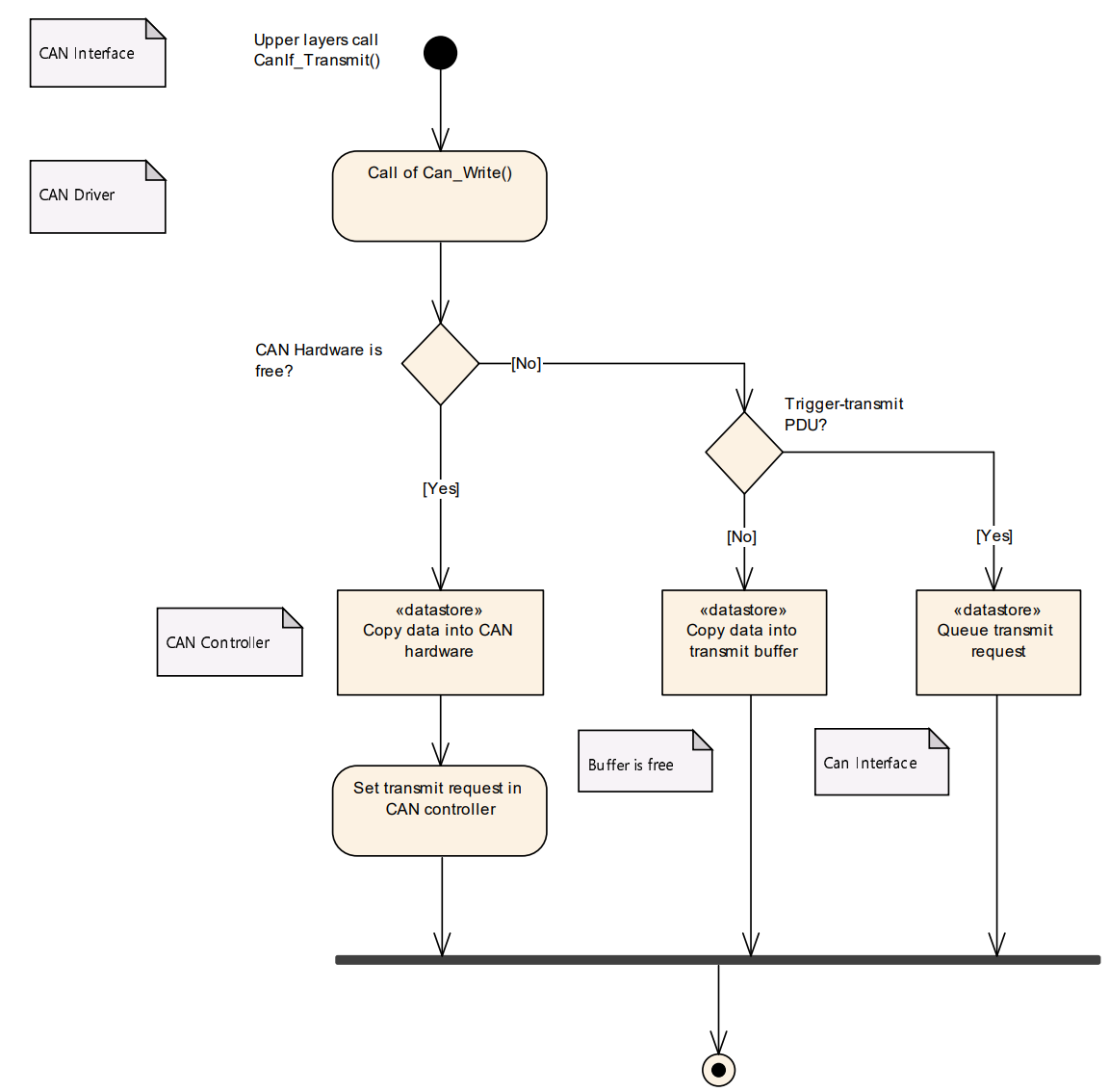
CanIf 存储了为传输目的配置的可用硬件对象的信息。函数 CanIf_Transmit() 将 CanTxPduId 映射到对应的 HTH,并调用函数 Can_Write()。
如果总线镜像已全局启用(参见 CanIfBusMirroringSupport),并且通过调用 CanIf_EnableBusMirroring 激活 CAN 控制器,CanIf 应在传输前存储每个帧的内容
注意:帧内容应仅在实际发送时提供给总线镜像模块。因此,内容必须存储,以便能够从 CanIf_TxConfirmation()内部提供给总线镜像模块。
传输缓冲
发送缓冲区
首先介绍一个叫做(HOH)Hardware Object handles的这个概念,这个其实在MCAL层出现的较多,对MCAL的上层软件来说,HOH其实就是一个CAN报文的消息缓冲区,该结构包含与 CAN 相关的参数,如 CanId、DLC 和数据。基于 CAN 硬件缓冲区抽象,每个硬件对象在 CanIf 中被引用,独立于 CAN 硬件缓冲区布局。上层软件想发送报文的时候,就把报文往里面塞就好了,MCAL会负责发送出去,同理,接收报文就是从缓冲区里读取。但是在MCAL层,这个HOH的实现就五花八门了,这里就不多解释了。后文出现的HTH意思就是用来发送的HOH,而HRH意思就是用来接收的HOH。HOH 作为 CanDrv 接口服务调用中的参数,由 CanDrv 配置提供,CanDrv 用作 CAN 邮箱通信缓冲区的标识符。
CanIf 仅作为硬件对象句柄的用户,但不会基于硬件特定信息来解释。因此,CanIf 始终独立于硬件。
- CanIf 应避免直接访问硬件特定的通信缓冲区,仅通过 CanDrv 接口服务访问。CanIf 与硬件保持独立,因为 CanDrv 接口调用时带有 HOH 参数,这些参数抽象了具体的 CAN 硬件缓冲区属性。
- 每个 CAN 控制器可以在 CAN 邮箱中提供多个 CAN 传输硬件对象。这些可以逻辑上通过HTH寻址动态的连接到一个完整的硬件对象池(复用硬件对象)
- 多个物理硬件对象(如CAN控制器提供的多个发送邮箱)可以被逻辑映射到一个统一的资源池中。
- 通过这种复用机制,一个HTH可以动态关联到池中的任意空闲硬件对象,而非固定绑定到某个物理邮箱。
- CanIf 将使用两种类型的 HOH 以实现对 CanDrv 的访问
HRH应该可以收到:
- BasicCAN:一组CanId和在一个区域或一个范围内的CANID
- FullCan:单个CanId
- 所有的Canid
这里不妨衍生一下,这两个的定义其实起源颇深,大家可参考文章:《Full-CAN vs. Basic-CAN》。
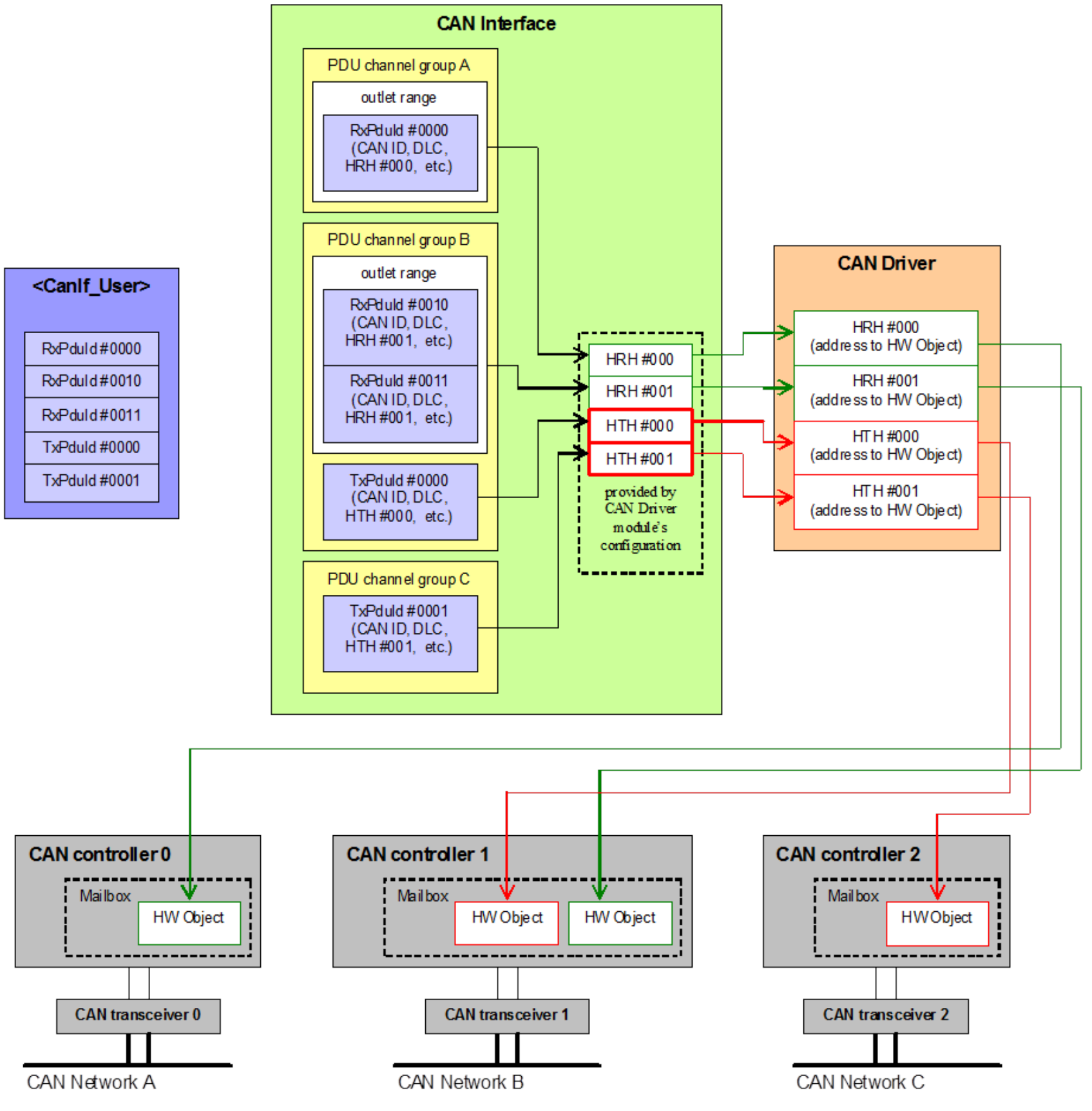
当 CANIF_PUBLIC_TX_BUFFERING 配置为 ON 的时候, CanIf 会为 Basic 类型(多个 PDU 共享一个 HTH)的 PDU 分配发送缓冲区。
当 CanIf 调用 Can_Write 返回 CAN_BUSY 的时候,说明当前的 HTH 正在发送上一帧数据,不能写入新的数据。此时, CanIf 将会把新的数据储存在 CanIf 的缓冲区。在 Can 的发送确认中,针对刚刚发送成功的 HTH(此时已经处于空闲状态,可以写入新的数据), CanIf 将查询分配给该 HTH 的 PDU,是否有数据在缓冲区中,如果有的话, CanIf 将自动把缓冲区中的数据写入 HTH,并发送出去。CanIf 发送缓冲区具有如下特性:
- Full 类型的 PDU 不会分配缓冲区;
- 每个 Basic 类型的 PDU 有且只有一级缓存,因此,新的数据覆盖旧的数据;
- 当 CANIF_PUBLIC_TX_BUFFERING 配置为 OFF 时,所有的 PDU 都没有发送缓冲区;
- 如果同一 HTH 的缓冲区中有多个 PDU,将按照 PDU 的优先级(CANID 从小到大的顺序)进行发送。
一般行为
在 CanIf 的范围内,传输过程从调用 CanIf_Transmit()开始,最终以调用上层模块的回调服务()结束。在传输过程中,CanIf、CanDrv 和 CAN 邮箱应将 L-PDU 存储一次,只在一个位置发送一次。根据发射方式的不同,这些包括:
- CAN 硬件传输对象
- CanIf 内的发射 L-PDU 缓冲区(如果启用了传输缓冲,CanIf 会将 Tx L-PDU 存储在 CanIf 传输 L-PDU 缓冲区(CanIfBufferCfg)中,前提是 CanDrv 在发送请求时拒绝该缓冲。)
[!note]
对于触发传输,CanIf 只需存储给定 L-PDU 的发送请求,而无需存储其数据。当 HTH 再次空闲时,通过触发传输功能及时获取数据。单个 Tx L-PDU 若被请求传输,绝不能存储两次。这种行为对应于 CAN 网络上通常的周期性通信方式。
基本上,CanIf 中用于缓冲 Tx L-PDU 的整体缓冲区由一个或多个 CanIfBufferCfg 组成。而每个 CanIfBufferCfg 分配给一个或多个专用 CanIfBufferHthRef,并可配置为缓冲一个或多个 Tx L-PDU。但如上所述,每个 Tx L-PDU 只能缓冲一个实例,包含 CanIfBufferCfg 的总量。
在 L-PDU 传输过程中,CanIf 的行为会根据对应发送L-PDU 的配置设置是否启用传输缓冲而有所不同:
- 如果传输缓冲被禁用且发送请求失败(CAN 控制器邮箱正在使用 BasicCAN),L-PDU 不会被复制到 CAN 控制器邮箱,CanIf_Transmit()返回值 E_NOT_OK。
- 如果启用了传输缓冲且发送请求失败,根据 CanIfTxBuffer 配置,L-PDU 可以存储在 CanIfTxBuffer 中。在这种情况下,CanIf_Transmit()返回了值 E_OK,尽管无法执行传输。在这种情况下,CanIf 通过 CanIf_TxConfirmation()回调处理 L-PDU 的未完成传输,上层无需重试发送请求。
在配置 CanIf 模块时,你为发送 L-PDU(即应用层想要通过 CAN 发送的数据包)分配的实际 RAM 缓冲区数量,可以完全独立于你在 CAN 网络描述文件(如 .dbc 文件)中为该 ECU 定义的要发送的 L-PDU 数量。假设你的 ECU 可能在网络描述文件中定义了 10 个不同的 Tx L-PDU,但你可能只需要配置 5 个 CanIf Tx L-PDU 缓冲区,因为这些 L-PDU 可以共用硬件发送对象 (HTH),或者有些 L-PDU 不需要 CanIf 内部缓冲。
根据 AUTOSAR 规范,每个 Tx L-PDU(通过配置容器 CanIfTxPduCfg 定义)都需要通过一个 CanIfBufferCfg 配置容器来关联一个或多个 HTH (Hardware Transmit Handle),HTH 是由 CAN Driver 提供的,代表 CAN 硬件上的发送邮箱或缓冲区。
当某个 Tx L-PDU 不需要 CanIf 模块内部提供 RAM 缓冲时(例如,这个 L-PDU 直接使用 CAN 硬件的发送邮箱,不需要在软件层排队或存储),CanIfBufferCfg 仍然是必需的。此时,需要将 CanIfBufferCfg 中的配置参数 CanIfBufferSize 设置为 0。当 CanIfBufferSize 设置为 0 时,CanIfBufferCfg 配置容器的作用就只剩下引用或关联该 L-PDU 将要使用的 HTH,它不再具备实际的软件缓冲功能。
L-PDU的存储
配置的不同的传输方式也会进行不同的缓存处理:
-
当 L-PDU 被配置为 直接传输 (Direct Transmission) 模式时:
- 如果缓冲功能已启用,并且
Can_Write()返回CAN_BUSY,CanIf 必须检查是否有可能将整个被请求传输的 CanIf Tx L-PDU 数据 缓冲到CanIfTxBuffer中。 - 对于 动态 (Dynamic) Tx L-PDUs,CanID (CAN 标识符) 也必须与 L-PDU 数据一起存储在缓冲区中。
- 数据长度不匹配的处理:
- 如果被拒绝的 L-PDU 数据长度超过了配置的缓冲区大小 (
CanIfBufferSize),CanIf 必须:- 只缓冲配置允许的数据量,并丢弃其余部分。
- 向 DET (Development Error Tracer) 报告运行时错误码
CANIF_E_DATA_LENGTH_MISMATCH。
- 如果被拒绝的 L-PDU 数据长度超过了配置的缓冲区大小 (
- 如果缓冲功能已启用,并且
-
当 L-PDU 被配置为 触发传输 (Triggered Transmission) 模式时:
-
如果缓冲功能已启用,并且
Can_Write()返回CAN_BUSY,CanIf 必须检查是否有可能将发送请求 (Transmit Request) 缓冲到CanIfTxBuffer中。[!note]
注:对于触发传输,通常缓冲的不是实际的数据,而是发送请求本身(即一个标志),实际数据会在后续由 PDU Router 或上层模块提供(例如在
PduR_CanIfTriggerTransmit()被调用时)。
-
CanIf 只有在配置参数 CanIfPublicTxBuffering 启用时,才支持对 BasicCAN 传输进行 L-PDU 缓冲。
[!note]
BasicCAN 通常指一个 L-PDU 可能使用多个不同的 HTH,且通常需要软件缓冲来处理排队。FullCAN L-PDU 通常不使用 CanIf 缓冲。
尝试发送过程如下:
- 上层 (如 PduR) 调用
CanIf_Transmit()。 - CanIf 尝试立即调用
Can_Write()写入 CAN Driver。- 结果 A (
CAN_OK): 发送成功,流程结束。 - 结果 B (
CAN_BUSY): 硬件繁忙(无 HTH 可用)。- CanIf 检查:
- 如果
CanIfPublicTxBuffering禁用:发送失败,向上传输结果。 - 如果
CanIfPublicTxBuffering启用:将 L-PDU 数据(直接传输)或 L-PDU 请求(触发传输)存储到 CanIf 内部的 Tx L-PDU 缓冲区中。
- 如果
- 当 CAN Driver 报告发送完成(通过
CanIf_TxConfirmation())且有 HTH 释放时,CanIf 会将缓冲区中的 L-PDU 写入 CAN Driver。
- CanIf 检查:
- 结果 A (
发送确认
如果之前的传输请求成功完成,CanDrv 会通过调用 CanIf_TxConfirmation()通知 CanIf。
如果总线镜像在全局启用,并且通过调用 CanIf_EnableBusMirroring()激活 CAN 控制器,CanIf 应对该控制器上的每个帧传输通过 CanIf_TxConfirmation()确认发送帧,调用 Mirror_ReportCanFrame()服务,调用时,需要提供存储的内容和实际的 CAN ID)
[!tip]
总线镜像允许外部工具或模块监听 ECU 实际发送的 CAN 帧,常用于诊断和调试。
当 CanIf_TxConfirmation() 回调服务被调用时,CanIf 必须执行以下操作:
- 识别与成功传输的 L-PDU 链接的上层通信层(例如 PduR 或某个应用模块)。
- 通过调用该上层模块的发送确认服务(返回值为
E_OK)来通知其传输已完成。
上层回调: 这个回调服务是由被通知的上层模块实现的。
配置静态分配: 一个 Transmit L-PDU 只能静态地分配给一个单一的发送确认回调服务。上层模块可以配置为对不同的 L-PDU 使用单个或多个回调服务。
如果配置启用了 发送确认轮询支持 (CanIfPublicTxConfirmPollingSupport)。并且,对应的 CAN 控制器模式处于 CAN_CS_STARTED 状态。那么,CanIf 必须为每个 CAN 控制器缓冲接收到的 TxConfirmation 信息。这允许 CanIf 在后续的 CanIf_MainFunction() 中,通过轮询的方式处理这些确认信息,而不是立即在中断上下文(如果 TxConfirmation 是在中断中触发的话)中处理。
接收数据流
根据 AUTOSAR 基础软件架构,接收到的数据将在上层通信栈(如 AUTOSAR COM、CanNm、CanTp、DCM)中进行评估和处理,这意味着,上层模块既不能使用 CanDrv (Rx) 的缓冲区,也不能访问 CanIf (Tx) 的缓冲区。
如果有新的 L-PDU 接收,CanDrv 会调用 CanIf 的 CanIf_RxIndication()。对 L-PDU 指定数据的访问由以下参数决定:
- 硬件接收句柄(HRH)
- 接收 CAN 标识符(CanId)
- 接收数据长度
- 接收 L-PDU 的Reference
接收的 L-PDU 依赖硬件(字节和字节排序、访问类型),并分配给通信系统中最低层——CanDrv,其中HRH (Hardware Receive Handle) 充当了 CanDrv 和使用该 L-PDU 的上层模块之间的链接。
当 CanDrv 接收到一个 L-PDU 后,它会调用 CanIf_RxIndication() 来通知 CanIf 模块。
- CanIf 无法识别 CanDrv 是使用了临时缓冲还是直接硬件访问来获取数据。
- CanIf 期望在
CanIf_RxIndication()的调用中接收到的 L-PDU 数据是规范化 (normalized) 的(即,CanDrv 必须处理硬件的字节序等依赖性,向 CanIf 提供统一格式的数据)。
硬件接收对象的锁定与释放:
- 锁定: 在将数据复制到临时缓冲区或上层模块缓冲区的过程中,CAN 硬件接收对象是处于锁定状态的。
- 这个锁定确保了数据在被复制完成之前不会被新的接收帧覆盖。
- 释放: 为了避免数据丢失,在 CanIf 的
CanIf_RxIndication()函数返回给 CanDrv 后,该硬件接收对象必须立即被释放。- 这保证了 CAN 硬件能够迅速准备好接收下一个传入的 CAN 帧。
缓冲区访问:
- 共享缓冲区: CanDrv、CanIf 以及属于该接收 L-PDU 的上层模块,都可能访问同一个临时中间缓冲区。
- 缓冲区位置: 这个临时缓冲区可以位于:
- CAN 控制器的 CAN 硬件接收对象中。
- CanDrv 的临时缓冲区中。
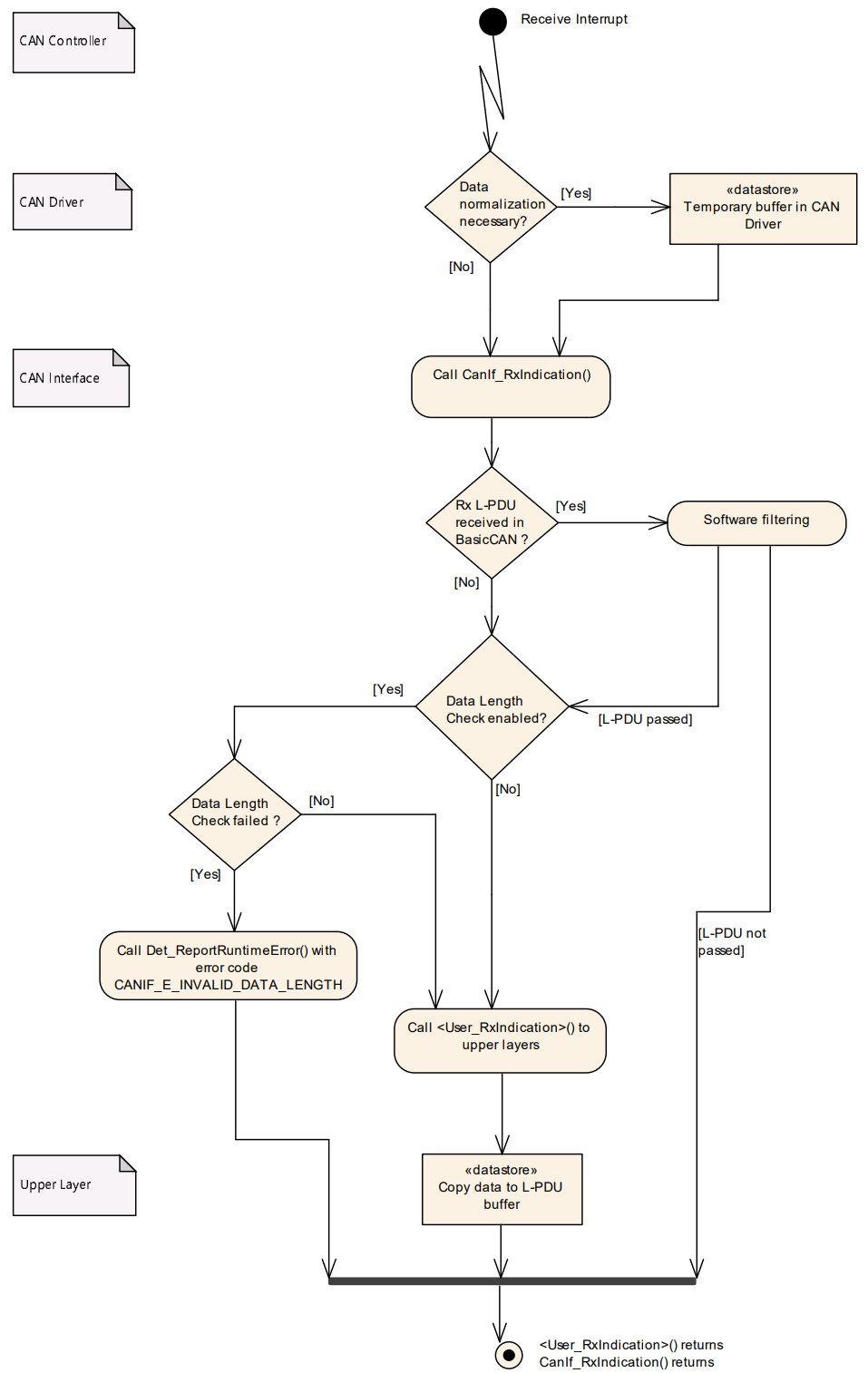
接收指示
CanIf_RxIndication() 是 CAN Driver 用来通知 CanIf 模块接收到新 CAN 帧的回调函数。CanIf 接收到调用后,其主要任务是评估 L-PDU 的接受性并准备 L-SDU (上层数据)。
- 总线镜像报告
- 如果全局启用了总线镜像 (
CanIfBusMirroringSupport) 且已为该控制器激活。 - CanIf 必须为该控制器上每个通过
CanIf_RxIndication()指示的接收帧,调用Mirror_ReportCanFrame()进行报告。
- 如果全局启用了总线镜像 (
- 软件过滤 (Software Filtering)
- 一旦调用
CanIf_RxIndication(),CanIf 必须对接收到的 L-PDU 执行软件过滤(如果配置了,例如通过CanIfHrhRangeCfg)。 - 如果软件过滤拒绝了该 L-PDU,CanIf 必须立即终止该
CanIf_RxIndication()的后续处理。 - 注:软件过滤主要用于 FullCAN 未能覆盖到的 BasicCAN 接收,或用于更复杂的过滤逻辑。
- 一旦调用
- 数据长度检查 (Data Length Check)
- 如果 L-PDU 通过了软件过滤。
- CanIf 随后必须执行数据长度检查(如果配置了,通过
CanIfPrivateDataLengthCheck和CanIfRxPduDataLengthCheck)。 - 注:这确保接收到的数据长度不超过配置所允许的长度。
- 缓冲和数据复制
- 如果 L-PDU 通过了数据长度检查。
- 并且该 L-PDU 配置了使用 静态接收缓冲区。
- CanIf 必须将接收到的 L-PDU 数据(L-SDU)复制到该静态接收缓冲区中,复制的字节数应等于配置的数据长度。
- 如果 L-SDU 配置了 元数据 (MetaData)。
- CanIf 必须将 L-PDU 的有效载荷 (payload) 复制到静态接收缓冲区,并将 CAN ID 复制到类型为
CAN_ID_32的 MetaDataItem 中。
- 通知上层模块 (Upper Layer Indication)
- 如果 L-PDU 通过了数据长度检查。
- CanIf 必须检查是否配置了目标上层模块,以便调用其接收指示服务来处理接收到的 L-SDU(通过
CanIfRxPduUserRxIndicationUL等参数配置)。 - 如果配置了要调用目标上层模块,CanIf 必须调用这个配置好的接收指示回调服务 (
CanIfRxPduUserRxIndicationName)。 - CanIf 将基于
CanIf_RxIndication()的参数,提供上层通知回调函数所需的参数。 - 注:一个接收 L-PDU 只能分配给一个单一的接收指示回调服务。
读取接收数据
通过同步 API CanIf_ReadRxPduData() 读取数据。这提供了一种与异步接收指示 (Rx_Indication) 不同的数据获取方式。
-
API 的作用和接口
- 作用:
CanIf_ReadRxPduData()是 CanIf 模块提供给上层模块(如 PduR 或应用层)用来读取最近从 CAN 网络接收到的 CAN L-SDU 的通用接口。 - 访问方式: 上层模块通过 CanIf 的服务(即这个 API)发起接收请求,不直接访问 CanDrv。
- 完成标志: 当 CanIf 将接收到的 L-SDU 写入上层模块提供的 I-PDU 缓冲区时,接收请求成功完成。
- 作用:
-
独立于接收事件
- 配置启用: 如果配置参数
CanIfPublicReadRxPduDataApi启用,则可以使用此 API 读取数据。 - 异步解耦: 这种读取方式使得数据读取不依赖于接收事件的发生(即
RxIndication)。 - 灵活配置: 当此 API 启用时,不必同时为同一个 L-SDU 配置接收指示服务 (
CanIfRxPduUserRxIndicationUL)。当然,如果需要,两者也可以同时启用。
- 配置启用: 如果配置参数
-
缓冲机制的要求
- 如果配置参数
CanIfPublicReadRxPduDataApi设置为TRUE。 - 并且某个特定的 L-SDU 配置参数
CanIfRxPduReadData设置为TRUE。 - 那么,CanIf 必须为该接收 L-SDU 分配并使用一个接收 L-SDU 缓冲区来存储接收到的数据。
- 在
CanIf_RxIndication()调用过程中,如果 L-PDU 通过了软件过滤和数据长度检查,CanIf 必须将接收到的 L-SDU 存储到这个接收 L-SDU 缓冲区中。 - 互斥访问: 在调用
CanIf_ReadRxPduData()期间(即上层正在读取数据时),CanIf 必须避免可能抢占访问该接收 L-SDU 缓冲区的事件(例如,新的CanIf_RxIndication或其他并行访问),以确保数据的一致性。
- 如果配置参数
-
接收机制的选择
-
通过配置参数
CanIfRxPduUserRxIndicationUL(用于异步通知)和CanIfRxPduReadData(用于同步读取),上层模块可以根据自己的需求,在配置时选择适合的接收 L-SDU 机制:机制 异步通知 (Rx Indication Callback) 同步读取 (ReadRxPduData API) 触发方式 数据到达时,CanIf 主动调用上层回调。 上层模块需要数据时,主动调用 CanIf API。 配置参数 CanIfRxPduUserRxIndicationULCanIfRxPduReadData数据缓冲 可选,通常不强制要求 CanIf 内部静态缓冲。 强制要求 CanIf 内部静态缓冲
-
通知状态轮询
AUTOSAR CanIf 模块提供的另一种状态获取机制:通知状态轮询 (Notification Status Polling)。除了通过回调函数(Callback)被动接收通知外,上层模块还可以主动调用 API 来查询某个 PDU 是否已经成功发送或接收。
-
CanIf 提供了两个专门用于查询状态的 API,实现了“读并清除 (Read-and-Consume)”的机制:
CanIf_ReadTxNotifStatus(): 用于查询某个 发送 (Tx) L-PDU 的发送确认状态。CanIf_ReadRxNotifStatus(): 用于查询某个 接收 (Rx) L-PDU 的接收指示状态。
-
配置与启用
-
这两个 API 的功能可以通过配置参数在全局或单个 PDU 级别进行开启或关闭:
级别 发送 (Tx) 配置参数 接收 (Rx) 配置参数 全局开关 CanIfPublicReadTxPduNotifyStatusApiCanIfPublicReadRxPduNotifyStatusApi单 PDU 开关 CanIfTxPduReadNotifyStatusCanIfRxPduReadNotifyStatus -
只有当全局开关设为
TRUE时,CanIf 才会为每个 L-PDU 维护(存储)这个内部状态位。
-
-
“读并清除”机制 (Read-and-Consume)
- 逻辑含义:当上层模块调用这些 API 读取状态后,CanIf 会自动将该状态重置(通常重置为
CANIF_NO_NOTIFICATION)。 - 设计目的:确保上层模块获取到的“成功”状态,代表的是自上次调用该服务以来,至少发生过一次新的成功发送或接收事件。
- 状态返回值:
CANIF_TX_RX_NOTIFICATION: 自上次清除以来已发生事件。CANIF_NO_NOTIFICATION: 自上次清除以来未发生新事件。
- 逻辑含义:当上层模块调用这些 API 读取状态后,CanIf 会自动将该状态重置(通常重置为
[!note]
在 AUTOSAR 架构中,并不是所有上层模块都适合用“回调/中断”模式工作。以下场景通常会用到这些 API:
- 非事件驱动型任务:某些应用层任务(SWC)运行在固定的周期循环中,它们更倾向于在每个周期开始时“轮询”一下数据是否更新,而不是被中断随机打断。
- 降低中断负载:如果通信频率极高,频繁的回调会占用大量 CPU 资源。通过轮询状态,可以将处理逻辑集中在低优先级的周期性任务中。
- 双重确认:在某些安全关键应用中,除了等待回调,还可以通过该 API 进行状态的二次校验。
当相关配置参数使能后, CanIf 提供了接口,可通过这些接口查询 CanIf PDU 的的状态和数据,这包括:
- CanIf_ReadRxNotifStatus 查询某个 PDU 是否接收到;
- CanIf_ReadTxNotifStatus 查询某个 PDU 是否发送成功;
- CanIf_ReadRxPduData,读取某个 PDU 的接收数据;
- CanIf_GetTxConfirmationState,获取是否有报文发送成功,主要用于 Busoff 恢复。
DLC检查
当 CanIf 从 Can Drviver接收到一帧报文,可以对报文的 DLC 进行检查,如果 DLC 不合法,可以报错,并进行相应的处理。DLC 检查的方法有两种:
- AUTOSAR 标准算法:当实际接收到的 DLC 小于配置的 DLC 时,认为 DLC 不合法;
- 用户自定义算法:用户需要完成 CanIf_DlcCheckCallout 函数,自行进行检查。
若 DLC 检查失败,等同于该报文没有接收到,不会调用上层的接收指示回调函数。
控制器模式
通用功能
CanIf 在控制 CAN 控制器模式(Controller Mode) 时的角色的核心思想是:CanIf 是“执行者”,而 CanSm(CAN State Manager)是“决策者”。
- CanIf 的角色:执行与透传
- 核心职责:CanIf 提供了一组 API(如
CanIf_SetControllerMode()),允许上层模块请求改变 CAN 控制器的状态(如:START, STOP, SLEEP)。 - 不做校验:CanIf 不负责判断模式切换是否合法。它只是简单地把请求通过
CanDrv的接口转发给硬件。 - 状态存储:CanIf 会存储控制器的当前状态,并执行转换。为了优化性能,它会记录由
CanIf_ControllerModeIndication()上报的最新状态,以避免频繁调用底层驱动获取信息。
- 核心职责:CanIf 提供了一组 API(如
- CanSm 的角色:网络级决策
- 全局管理:CanSm 负责管理整个 CAN 网络(Network)的一致性。例如,当一个网络需要进入睡眠时,CanSm 会依次命令该网络下的所有控制器进入睡眠。
- 状态机实现:复杂的网络状态机逻辑(如 Bus-Off 恢复流程、网络激活/去激活)是在 CanSm 中实现的,而不是在 CanIf 中。
- 模式切换流程
- 全局管理:CanSm 负责管理整个 CAN 网络(Network)的一致性。例如,当一个网络需要进入睡眠时,CanSm 会依次命令该网络下的所有控制器进入睡眠。
- 状态机实现:复杂的网络状态机逻辑(如 Bus-Off 恢复流程、网络激活/去激活)是在 CanSm 中实现的,而不是在 CanIf 中。
[!tip]
- Bus-Off 处理:虽然
CanIf_SetControllerMode()是主动请求,但CanIf_ControllerBusOff()是由硬件检测到故障后被动触发的。- 多方请求:规范提到“不仅只有 CanSm 能请求改变模式”。这意味着在某些特定配置下,其他模块(如 BswM)也可能直接介入控制。
- 性能优化:CanIf 内部缓存控制器状态是推荐的做法,这样在响应
CanIf_GetControllerMode()时速度更快。
操作模式
当控制器进入 CAN_CS_STOPPED 状态时,当控制器被停止(例如为了节能或准备进入睡眠状态)时,CanIf 必须清理所有相关的中间状态:
- 拒绝新的发送请求:
- 如果控制器处于
STOPPED状态,任何调用CanIf_Transmit()的请求都会被拦截。 - CanIf 不会调用底层的
Can_Write(),而是直接返回E_NOT_OK。
- 如果控制器处于
- 清理缓冲区:
- 控制器一旦停止,CanIf 必须**清空(Clear)**分配给该控制器的所有 Tx 缓冲区(Tx Buffers)。这防止了陈旧的数据在控制器重启后被意外发送。
- 通知上层失败:
- 对于所有已经在缓冲区中或正在等待确认(Outstanding)的发送 PDU,CanIf 必须通过调用上层的
TxConfirmation(id, E_NOT_OK)告知发送失败。 - 原则:这保证了对于每一个
CanIf_Transmit请求,上层最终都会收到一个确定的反馈(要么成功,要么失败),不会出现“悬挂”状态。 - 如果开启了轮询模式(Polling),相关的确认信息也要被清除。
- 对于所有已经在缓冲区中或正在等待确认(Outstanding)的发送 PDU,CanIf 必须通过调用上层的
状态通知与回调转发
CanIf 作为一个中间层,负责将底层的硬件状态回调转发给正确的决策模块(通常是 CanSm):
- Bus-Off 处理:
- 当硬件检测到 Bus-Off 并调用
CanIf_ControllerBusOff()时,CanIf 必须立即通知 CanSm。CanSm 随后会启动恢复状态机。
- 当硬件检测到 Bus-Off 并调用
- **模式切换确认 **:
- 当底层驱动真正完成了模式切换(例如从 START 到 STOP)并调用
CanIf_ControllerModeIndication()时,CanIf 将此信息转发给 CanSm。
- 当底层驱动真正完成了模式切换(例如从 START 到 STOP)并调用
- 收发器状态:
- 同理,CAN 收发器(Transceiver)的模式切换也会通过 CanIf 转发给 CanSm。
CAN controller 在硬件实现上的状态抽象为以下四种基本状态:
- UNINIT
- STOPPED
- STARTED
- SLEEP
对每个 CAN Controller,在 Can Interface 模块上有一个对应的“软件”状态机,其有以下几种状态:
- CANIF_CS_UNINIT
- CANIF_CS_STOPPED
- CANIF_CS_STARTED
- CANIF_CS_SLEEP
上层可以通过调用 CanIf_SetControllerMode()服务来改变 CAN Controller 的状态。下表展示了用户使用CanIf_SetControllerMode()时的状态转换:
| CanIf 当前模式 | 用户请求模式 | 传递给 Can 的模式 |
|---|---|---|
| X | CANIF_CS_STARTED | CAN_T_START |
| CANIF_CS_SLEEP | CANIF_CS_STOPPED | CAN_T_WAKEUP |
| CANIF_CS_STOPPED | CANIF_CS_STOPPED | CAN_T_STOP |
| CANIF_CS_STARTED | CANIF_CS_STOPPED | CAN_T_STOP |
| X | CANIF_CS_SLEEP | CAN_T_SLEEP |
不合法的状态转换请求,例如 SLEEP 到 START, START 到 SLEEP,将在 Can 模块被检测到,并返回 E_NOT_OK。在转换阶段, Can Interface 模块中软件状态机的状态可能会与 CAN controller 中的硬件状态不一致。
调用 CanIf_SetControllerMode 进行模式切换,如果硬件的模式能够在较短的时间内完成,那么模式转换可以是同步的,也就是说,在 CanIf_SetControllerMode 返回之前,模式转换已经完成,并且通过 User_ControllerModeIndication 通知了上层。否则,模式转换是异步完成的,用户需周期调用 Can_MainFunction_Mode 来完成模式转换并通知上层。
在AUTOSAR架构中,CAN控制器(CAN Controller)的模式由通信接口层(CAN Interface, CANIf)管理。通过分层控制(控制器模式 + PDU模式),AUTOSAR实现了灵活且低功耗的CAN通信管理。CAN控制器模式如下:
- 启动模式(
CANIF_CS_STARTED)- 功能:
- 控制器完全激活,可正常收发CAN帧(包括数据帧、远程帧、错误帧等)。
- 参与总线仲裁、错误检测与恢复(如自动重传)。
- 触发条件:
- 网络管理(NM)请求通信,或上层模块(如ComM)授权通信。
- 功能:
- 停止模式(
CANIF_CS_STOPPED)- 功能:
- 控制器停止所有通信活动,关闭内部时钟以降低功耗。
- 仍可响应硬件唤醒事件(如总线显性电平)。
- 触发条件:
- 网络管理(NM)进入总线睡眠模式(Bus-Sleep),或ComM拒绝通信请求。
- 功能:
- 睡眠模式 (
CANIF_CS_SLEEP)- 功能:
- 控制器进入深度低功耗状态,仅保留基础唤醒功能。
- 需软件唤醒(调用
CanIf_ControllerWakeup())才能恢复通信。
- 触发条件:
- 明确请求低功耗(如整车电源管理指令)。
- 功能:
PDU模式与控制器模式协同工作,独立控制发送/接收行为:
| 模式 | 发送(TX) | 接收(RX) | 说明 |
|---|---|---|---|
CANIF_ONLINE |
✅ | ✅ | 完全通信(默认模式) |
CANIF_TX_OFFLINE |
❌ | ✅ | 静默模式(仅接收) |
CANIF_OFFLINE |
❌ | ❌ | 无通信(控制器停止或睡眠) |
控制器模式与其他模块的关系为:
- 与收发器的联动:
- 控制器进入
CANIF_CS_STOPPED时,收发器通常切换至TRCVMODE_STANDBY(待机)。 - 控制器唤醒后,收发器需先恢复
TRCVMODE_NORMAL,再启动控制器。
- 控制器进入
- 与网络管理(NM)的协同:
- NM通过
CanIf_ControllerMode控制总线参与权(如休眠时强制CANIF_CS_STOPPED)。
- NM通过
- 与ComM的交互:
- ComM决定通信权限,通过
CanIf_SetControllerMode配置控制器状态。
- ComM决定通信权限,通过
状态切换示例:
-
唤醒流程:
graph LR A[总线显性电平] --> B[收发器唤醒] B --> C[CanIf_ControllerWakeup] C --> D[控制器: CANIF_CS_STARTED] D --> E[PDU模式: CANIF_ONLINE] -
休眠流程:
graph LR A[NM请求休眠] --> B[ComM释放通信] B --> C[CanIf_SetControllerMode: CANIF_CS_STOPPED] C --> D[收发器待机]
关键差异总结:
| 模式 | 通信能力 | 功耗 | 唤醒方式 | 适用场景 |
|---|---|---|---|---|
CANIF_CS_STARTED |
全双工 | 高 | 始终活跃 | 正常运行 |
CANIF_CS_STOPPED |
无 | 中 | 硬件/总线唤醒 | 短时休眠 |
CANIF_CS_SLEEP |
无 | 极低 | 软件指令唤醒 | 深度休眠 |
模式转换
在 AUTOSAR 中,改变 CAN 控制器的状态并不是“即时”完成的,而是一个请求与响应的过程。
- 异步流程:
- 请求阶段:上层模块调用
CanIf_SetControllerMode(CAN_CS_SLEEP)。此时 CanIf 只是将指令下发给 CanDrv,API 随即返回。 - 执行阶段:CAN 控制器硬件在完成当前的通信任务后,才开始物理切换。
- 通知阶段:一旦硬件完成切换,CanDrv 调用回调函数
CanIf_ControllerModeIndication()。随后,CanIf 会将此通知转发给CanSm。
- 请求阶段:上层模块调用
- 特殊情况(快速切换):
- 如果硬件响应极快,
CanIf_ControllerModeIndication()可能会在CanIf_SetControllerMode()还没执行完时就被触发(嵌套调用)。这是实现相关的。
- 如果硬件响应极快,
- 失败处理:
- CanIf 本身不监控“模式转换是否超时”。如果转换失败或没有响应,必须由上层模块(如 CanSm)通过超时机制来跟踪处理。
[!tip]
🛌 睡眠与唤醒机制 (Wake-up):CAN 控制器的硬件差异(是否支持 Sleep/Wake-up)被
CanDrv屏蔽了,CanIf 只需要处理标准化的模式。
内部唤醒 vs 外部唤醒
CanIf 严格区分了两类唤醒请求:
| 特性 | 内部唤醒 (Internal Request) | 外部/网络唤醒 (External Request) |
|---|---|---|
| 触发源 | 软件逻辑(ECU 主动想通信) | 外部总线活动(其他节点发出的帧) |
| 触发方式 | 调用 CanIf_SetControllerMode(..., CAN_CS_STARTED) |
硬件检测到信号,由 CanDrv/CanTrcv 通知 |
| 处理性质 | 异步软件请求 | 硬件中断事件 |
注意: 在从
STOPPED切换到SLEEP的敏感过程中,硬件可能会意外产生一个唤醒中断给集成代码(ECU Integration Code),这在开发底层驱动时需要特别注意。
状态查询:如果上层模块不想等待异步通知,可以随时调用 CanIf_GetControllerMode() 主动轮询。
硬件解耦:无论底层硬件如何实现,CanIf 看到的都是统一的 START、STOP、SLEEP。
责任分担:CanIf 负责“传话”和“记录”,CanSm 负责“决策”和“监控”。
唤醒
为了支持通过 CAN 网络唤醒 ECU(无论是通过 CAN 控制器还是收发器),硬件必须处于一种**“监听唤醒”**的状态。唤醒模式的硬件前提:
- 必须进入休眠(Sleep Mode):
- 唤醒监听通常是在 Sleep Mode 下实现的。
- 在这个模式下,正常的通信功能是关闭的。这种“禁用通信”是确保 CAN 控制器能够完全停止(Stopped)的必要条件。
- 唤醒中断的使能:
- 只有当控制器停止了正常的帧处理逻辑,硬件才能将资源切换到检测特定的总线活动(如 WUP - Wake-up Pattern)。
- 此时,唤醒中断(Wake-up Interrupt) 才能被安全地使能。如果控制器还在正常发送/接收数据,硬件是无法区分普通信号和唤醒信号的。
- 硬件独立性:
- 规范提到,无论唤醒信号是通过 CAN 控制器 直接检测,还是通过 CAN 收发器 (Transceiver) 检测,这种逻辑都适用。
🔄 唤醒流程图解
当 ECU 处于低功耗状态时,数据的流动和状态切换如下:
- 进入休眠:CanSm 发起请求 $\rightarrow$ CanIf 转发 $\rightarrow$ CanDrv 将硬件设为休眠并开启中断。
- 监听状态:此时总线上没有该节点的流量,耗电极低,但硬件电路仍在监控差分电压的变化。
- 外部触发:总线上出现特定波形(如远程节点发送的网络管理帧)。
- 中断触发:硬件产生唤醒中断 $\rightarrow$ 触发 ECU 的启动序列 $\rightarrow$ CanIf 收到通知并将模式切回
CAN_CS_STARTED。
这段话的核心技术意义在于:通信的“停止”是唤醒“开启”的前提。在设计 AUTOSAR 系统的休眠逻辑时,必须先通过 CanIf_SetControllerMode 确保控制器进入 CAN_CS_SLEEP,否则硬件层面的唤醒中断可能无法正确初始化。
CanIf 模块在 AUTOSAR 唤醒流程中扮演的“协调者”角色,特别是它如何响应 ECU Manager (EcuM) 的请求来验证物理硬件是否真的发生了唤醒。
唤醒检查
🛡️ CanIf 唤醒检查机制 (CanIf_CheckWakeup):当 ECU 处于睡眠状态并检测到潜在的唤醒信号时,系统的处理逻辑遵循从上到下再到下的链式调用。
- 触发源:集成代码与 EcuM
- 调用背景:当硬件检测到总线活动,EcuM(通过集成代码)会启动唤醒验证流程。它会调用
CanIf_CheckWakeup(WakeupSource)。 - 参数意义:
WakeupSource是一个位掩码,代表 EcuM 定义的唤醒源。CanIf 需要知道这个“源”对应的是哪些具体的 CAN 控制器或收发器。
- 调用背景:当硬件检测到总线活动,EcuM(通过集成代码)会启动唤醒验证流程。它会调用
- 映射逻辑:寻找目标硬件
- 配置引用:CanIf 通过配置(
CanIfCtrlCanCtrlRef)建立起 EcuM 唤醒源 与 CAN 控制器/收发器 之间的映射关系。 - 精准定位:当 EcuM 问“这个唤醒源有没有唤醒?”时,CanIf 查表得知该源涉及哪些驱动(CanDrv 或 CanTrcv)。
- 配置引用:CanIf 通过配置(
- 执行验证:向下查询
- 这是核心动作。CanIf 不自己判断,而是去问底层:
- 问收发器驱动:
CanTrcv_CheckWakeup() - 问控制器驱动:
Can_CheckWakeup()
- 问收发器驱动:
- 目的:底层驱动会读取硬件状态寄存器,确认是否真的发生了有效的总线唤醒波形(例如符合 ISO 11898-2 的唤醒序列)。
- 判定规则 (返回值的逻辑)
- CanIf 汇总底层驱动的检查结果并反馈给 EcuM:
- 只要有一个行,就行:
- 只要底层驱动中有一个返回
E_OK(确认有唤醒事件),CanIf_CheckWakeup()就向 EcuM 返回E_OK。
- 只要底层驱动中有一个返回
- 必须全不行,才算不行:
- 只有当所有相关的底层驱动都返回
E_NOT_OK时,CanIf_CheckWakeup()才向 EcuM 返回E_NOT_OK。
- 只有当所有相关的底层驱动都返回
- 只要有一个行,就行:
- CanIf 汇总底层驱动的检查结果并反馈给 EcuM:
📝 总结:CanIf 在这里的职责
- 分发者:将 EcuM 抽象的
WakeupSource翻译成具体的硬件对象。 - 调用者:统一调用不同厂商(Vendor)提供的 CAN 驱动 API。
- 聚合者:将多个驱动的状态合并成一个简单的成功或失败,供 EcuM 决策是否需要全面启动 ECU(即从低功耗状态切回正常运行状态)。
💡 为什么需要这个过程?
这个机制是为了防止误唤醒(False Wakeups)。
- 有时候总线上的电磁干扰(EMC)可能会触发一个虚假的唤醒中断。
- EcuM 通过
CanIf_CheckWakeup强制要求驱动层去检查硬件内部的唤醒标志位。如果标志位没置位,ECU 会认为这是一个噪声,从而继续保持睡眠,节省功耗。
唤醒校验
**唤醒校验 (Wake-up Validation)**的存在是为了防止 ECU 被总线上的电磁干扰(噪声)误唤醒,从而浪费电量。
当 CAN 控制器检测到总线活动并触发唤醒中断后,ECU 此时仅处于“疑似唤醒”状态。为了确认这确实是一个有效的通信请求,而不是由于电线接触不良产生的火花,EcuM (ECU Manager) 需要看到一个真实的 CAN 报文。
-
校验的前提:控制器必须“转起来”
- 控制器不能直接从
SLEEP跳到STARTED。 - 流程:当硬件产生唤醒事件通知 EcuM 后,EcuM 会通过
CanIf_SetControllerMode()将控制器设为STARTED状态。只有控制器开始工作,才能接收报文来进行校验。
- 控制器不能直接从
-
谁能通过校验? (
CanIf_RxIndication)-
CanIf 会盯住控制器启动后的第一条报文:
-
如果配置了
CanIfPublicWakeupCheckValidByNM = TRUE:只有网络管理 (NM) 报文才能算作有效的唤醒。 -
如果为
FALSE:任何在配置表里的 Rx PDU(普通应用报文)都能通过校验。 -
一旦收到这第一条符合要求的报文,CanIf 内部就会存下一个“已验证”的标记。
-
-
[!important]
规范中特别提到:在校验期间,PDU 通道模式(PduRoute)不能设为
ONLINE。
- 原因:如果校验还没通过就把通道设为
ONLINE,那么上层应用模块(如 PduR, Com)就会立刻收到数据。- 逻辑矛盾:如果最后校验发现这个唤醒是“误报”,但此时应用层已经开始处理数据了,会导致系统逻辑混乱。
- 正确做法:只有在 EcuM 确认校验成功后,才会将 PDU 通道切换到
ONLINE,允许数据流向应用层。
🔄 校验的生命周期管理
| 动作 | CanIf 的处理逻辑 |
|---|---|
| 检测到报文 | 检查是否为合法的 NM 或应用报文,并记录状态。 |
| 触发校验请求 | EcuM 调用 CanIf_CheckValidation(),CanIf 回复:收到有效帧了。 |
| 重置标记 | 当控制器重新进入 CAN_CS_SLEEP 时,清空“已验证”标记,为下次唤醒做准备。 |
唤醒校验是一个“二次确认”的过程:
- 硬件说:“有人拍我,我醒了(产生中断)。”
- EcuM 说:“别急,把控制器打开,我看看他说了什么(请求校验)。”
- CanIf 说:“我看到他发了一个合法的报文,确实是自己人(收到 RxIndication)。”
- EcuM 说:“好,现在全员正常开工(切换 ONLINE)。”
PDU模式
PDU信道组
📂 什么是 L-PDU 通道组?
在 AUTOSAR 中,ECU 可能会连接多个 CAN 网络。为了方便管理,CanIf 将 L-PDU 进行了逻辑分组:
- 物理对应关系:
- 每个 L-PDU 都固定分配给一个物理 CAN 通道(即一个 CAN 控制器 + 一个 CAN 网络)。
- 属于同一个物理通道的所有 L-PDU 被归为一个逻辑组。
- 单一性原则:
- 一个 L-PDU 只能属于一个通道组。这确保了模式切换(如:一键关闭该网络的所有通信)时逻辑的唯一性。
- 逻辑抽象:
- 通过这种分组,上层模块不需要逐个操作成百上千个 PDU,而是可以针对整个“通道组”下达指令。
🎮 谁在控制这些通道组?
虽然 CanIf 负责执行,但控制权属于更高层的模块:
- PduR (PDU Router):负责路由 PDU。它可以决定某个路径的通信是否开启。
- NM (Network Management):负责网络管理。当网络需要休眠或激活时,NM 会通知 CanIf 切换通道组的状态。
🚦 通道模式(PDU Operation Modes)
当 PduR 或 NM 控制这些组时,主要是在切换以下几种模式(即 PduChannelMode):
| 模式 | 发送 (TX) | 接收 (RX) | 描述 |
|---|---|---|---|
| CANIF_OFFLINE | ❌ 禁用 | ❌ 禁用 | 通信完全切断。 |
| CANIF_ONLINE | ✅ 启用 | ✅ 启用 | 正常通信状态。 |
| CANIF_TX_OFFLINE | ❌ 禁用 | ✅ 启用 | 仅接收,不发送。常用于诊断或网络启动初期。 |
| CANIF_TX_OFFLINE_ACTIVE | ⚠️ 模拟 | ✅ 启用 | 模拟发送成功(触发 TxConfirmation),但实际不往总线上发。用于测试或静默模式。 |
📝 这种设计的意义在于:
- 简化操作:上层只需要通过一个
CanIf_SetPduMode(ChannelGroup, Mode)调用,就能瞬间改变整个控制器的通信行为。 - 解耦:上层模块(如 NM)只需要关注“网络(Network)”的状态,而不必关心这个网络里具体有哪些 PDU。
- 一致性:确保属于同一网络的所有报文在状态转换时步调一致。
PDU信道模式
如果说控制器模式(Controller Mode)是整个控制器的“电源总闸”,那么 PDU 通道模式(PDU Channel Mode) 就是每个逻辑通道的“分路开关”。
CanIf 允许上层模块(如 PduR 或 CanSm)通过 CanIf_SetPduMode() 来控制一个逻辑通道内所有 PDU 的行为。
-
四种核心模式对比
模式 发送 (Tx) 接收 (Rx) 行为描述 CANIF_OFFLINE ❌ 禁用 ❌ 禁用 默认状态。该通道的所有 PDU 既不发送也不接收。 CANIF_ONLINE ✅ 启用 ✅ 启用 全功能状态。报文在总线和上层之间自由流动。 CANIF_TX_OFFLINE ❌ 禁用 ✅ 启用 被动监听模式。节点可以听到总线上的声音,但自己保持沉默。常用于网络初始化或诊断期间。 CANIF_TX_OFFLINE_ACTIVE ⚠️ 模拟 ✅ 启用 模拟发送模式。CanIf 不将数据传给驱动,但会向上层回复“发送确认”。这用于欺骗上层协议栈,使其认为发送已成功。 -
关键约束:必须先“通电”
- 只有当对应的 CAN 控制器处于
CAN_CS_STARTED状态时,才允许更改 PDU 通道模式。 - 逻辑关系:如果控制器本身都处于
STOPPED或SLEEP状态(总闸关了),那么调节 PDU 的分路开关是没有意义且不被允许的。
- 只有当对应的 CAN 控制器处于
-
静默模式(TX_OFFLINE):
当 ECU 处于某些特殊诊断状态或刚上电需要观察总线流量(防止干扰其他节点)时,会将模式设为 CANIF_TX_OFFLINE。
-
模拟通信(TX_OFFLINE_ACTIVE):
在某些测试场景或特定的网络管理(NM)流程中,可能需要维持上层协议栈的状态机运行,但又不希望实际报文干扰总线。此时开启“模拟发送”,上层模块会收到正常的 TxConfirmation,从而维持业务逻辑不报错。
-
防止“悬挂”请求:
当模式从 ONLINE 切换到 OFFLINE 时,CanIf 会负责清理该通道关联的所有缓冲区,确保不会有旧数据残留在里面。
- 默认状态始终是
OFFLINE,必须显式切换才能通信。 - 精细控制:你可以单独关闭发送路径(TX_OFFLINE),而保持接收能力。
- 状态查询:上层可以随时通过
CanIf_GetPduMode()确认当前的通信状态。
CANIF_OFFLINE
-
模式的触发条件
- 根据规范,PDU 通道模式往往会随着控制器的状态变化而自动同步:
- **初始化 **:系统启动时,所有通道默认处于
CANIF_OFFLINE状态。 - 进入睡眠:当调用
CanIf_SetControllerMode(..., CAN_CS_SLEEP)时,通道会自动切换到CANIF_OFFLINE。 - 停止或 BusOff:当控制器进入
CAN_CS_STOPPED或发生BusOff时,通道会自动切换到CANIF_TX_OFFLINE。
- **初始化 **:系统启动时,所有通道默认处于
- 根据规范,PDU 通道模式往往会随着控制器的状态变化而自动同步:
-
核心模式行为对比表
| 行为特性 | CANIF_OFFLINE (全离线) | CANIF_TX_OFFLINE (发送离线) |
|---|---|---|
新发送请求 (CanIf_Transmit) |
❌ 拒绝 (返回 E_NOT_OK) |
❌ 拒绝 (返回 E_NOT_OK) |
| 发送缓冲区 (Tx Buffer) | 🧹 立即清空 | 🧹 立即清空 |
| 发送确认回调 (TxConfirmation) | ❌ 屏蔽/拦截 | ❌ 屏蔽/拦截 |
| 接收指示回调 (RxIndication) | ❌ 屏蔽/拦截 | ✅ 正常触发 (允许监听) |
| 触发场景 | 初始化、睡眠 (Sleep) | 停止 (Stopped)、总线关闭 (BusOff) |
- 缓冲区的“暴力”清理 :一旦通道切换到
OFFLINE或TX_OFFLINE,CanIf 内部的 Tx 软件缓冲区会立刻清空。这防止了当网络恢复正常(回到ONLINE)时,缓冲区中积压的陈旧数据突然“喷涌”而出,干扰总线时序。- BusOff 通知的“残留处理”
- 场景:如果有些报文在模式切换之前已经进入了硬件寄存器(Hardware Object),但还没发出去。
- 现象:切换到
OFFLINE后,硬件可能仍会尝试发送这些残留报文。如果发送导致了BusOff。- 处理:CanIf 不会禁止 这个
BusOff的通知。这意味着上层模块(如 CanSm)依然能收到这个最后的故障信号,从而启动恢复流程。- 唤醒通知的独立性:唤醒通知 (Wake-up Notification) 不受 PDU 通道模式的影响。即便通道是
OFFLINE,只要硬件配置了唤醒监听,唤醒事件依然会正常上报。
CANIF_OFFLINE是“全闭口”:不听也不说,通常用于断电或深度睡眠。CANIF_TX_OFFLINE是“只听不说”:用于节点生病(BusOff)或被要求闭嘴(Stopped)时,维持基本的网络监听能力。- 自动化管理:CanIf 通过同步控制器状态和 PDU 状态,确保了即使上层模块没有精细操作每个 PDU,整个通信系统的状态也是安全的。
CANIF_ONLINE
当一个逻辑通道(Channel Group)切换到此模式时,通信的所有“闸门”都会打开,允许数据在控制器和上层应用之间自由流动。当物理通道切换到 CANIF_ONLINE 时,CanIf 必须执行以下操作:
- 开启发送转发 (Enable Transmit Forwarding)
- 逻辑: 允许
CanIf_Transmit()请求通过。 - 行为: 当上层模块(如 PduR)请求发送数据时,CanIf 不再直接返回错误或拦截,而是将其转发给底层的 CanDrv(调用
Can_Write())。
- 逻辑: 允许
- 开启接收通知 (Enable Receive Indication)
- 逻辑: 允许底层接收到的数据上传给应用层。
- 行为: 当总线上收到报文并触发
CanIf_RxIndication()时,CanIf 会执行过滤和检查,并最终调用上层配置的 Rx 回调函数(如PduR_CanIfRxIndication)。
- 开启发送确认通知 (Enable Transmit Confirmation)
- 逻辑: 允许反馈发送成功的状态。
- 行为: 当硬件完成报文发送并触发
CanIf_TxConfirmation()时,CanIf 会将此成功信号转发给上层。这对于需要确认机制的协议(如诊断 TP 或网络管理 NM)至关重要。
为了方便理解,我们可以将 CANIF_ONLINE 与之前提到的 OFFLINE 模式进行对比:
| 功能路径 | CANIF_OFFLINE | CANIF_ONLINE |
|---|---|---|
发送请求 (CanIf_Transmit) |
❌ 拒绝并返回 E_NOT_OK |
✅ 转发至 CanDrv |
发送确认 (TxConfirmation) |
❌ 拦截/屏蔽 | ✅ 转发至上层 |
接收指示 (RxIndication) |
❌ 拦截/屏蔽 | ✅ 转发至上层 |
| 缓冲区状态 | 🧹 清空并锁定 | ✅ 启用(如果已配置) |
[!tip]
⚠️ 关键提示:从 Offline 恢复到 Online
虽然进入
CANIF_ONLINE会开启所有功能,但有两点需要注意:
- 不自动补发:切换到
ONLINE不会自动补发之前在OFFLINE期间被拒绝的报文(因为那些报文在进入OFFLINE时已经被清空了)。- 前提条件:正如之前规范提到的,切换到
ONLINE模式的前提是 CAN 控制器必须已经处于CAN_CS_STARTED状态。
CANIF_OFFLINE_ACTIVE
👻 CANIF_TX_OFFLINE_ACTIVE (发送离线激活模式):简单来说,这是一种**“虚拟发送”或“欺骗”**模式。它让上层模块以为报文发成功了,但实际上物理总线上静悄悄。
- 什么是“模拟成功传输”?
- 在正常的
CANIF_ONLINE模式下,TxConfirmation必须等到硬件发出报文并收到 ACK 之后,由中断触发。但在CANIF_TX_OFFLINE_ACTIVE模式下:- 当上层调用
CanIf_Transmit()时,CanIf 不会把报文发给CanDrv(硬件),也不会存入缓冲区。 - 立即回调:CanIf 会在
CanIf_Transmit()函数内部,立即调用上层的TxConfirmation回调函数。
- 当上层调用
- 在正常的
- “立即”意味着什么?
- 这改变了 AUTOSAR 典型的异步逻辑。在正常的发送流程中,
CanIf_Transmit返回E_OK后很久才会触发回调;而在本模式下,回调几乎是同步发生的。上层模块必须能够处理这种“刚请求发送就收到确认”的情况。
- 这改变了 AUTOSAR 典型的异步逻辑。在正常的发送流程中,
🛠️ 为什么要设计这个模式?(应用场景)
规范中提到了一个核心词:诊断被动模式 (Diagnosis Passive Mode)。
- 避免总线干扰:在某些诊断场景下(例如刷新其他 ECU 或执行某些系统测试),当前 ECU 不允许向总线上发送任何报文,以免产生干扰。
- 维持状态机运行:虽然不发报文,但上层协议栈(如
Com、PduR、NM)的状态机可能依赖于TxConfirmation才能进入下一个状态。- 无感切换:如果直接使用
OFFLINE模式,上层会因为收不到确认而报错或超时。使用TX_OFFLINE_ACTIVE,上层模块逻辑保持不变(依然能收到确认),实现了“逻辑在线、物理离线”。
| 模式 | 是否传给硬件 (CanDrv) | 是否触发 TxConfirmation | 物理总线表现 |
|---|---|---|---|
| ONLINE | ✅ 是 | ✅ 是(异步,等待硬件反馈) | 有报文 |
| OFFLINE | ❌ 否 | ❌ 否 | 无报文 |
| TX_OFFLINE | ❌ 否 | ❌ 否 | 无报文 |
| TX_OFFLINE_ACTIVE | ❌ 否 | ✅ 是(立即模拟触发) | 无报文 |
[!note]
💡 提示
这个功能是可选的。在配置工具中,必须先将全局参数
CanIfTxOfflineActiveSupport设置为TRUE,才能使用CanIf_SetPduMode()切换进入此状态。在执行 UDS 28服务 (Communication Control) 时,利用这个模式来关闭应用报文但保持网络管理或诊断响应的
CanIf中,可调用 CanIf_SetPduMode 控制某个 CAN 通道上 PDU 的接收和发送,各 CAN通道可分别控制。CanIf支持的Pdu Mode 模式和特征描述如下所示:
| PDU Mode | 描述 |
|---|---|
| CANIF_OFFLINE | 1. 阻止发送请求,调用 CanIf_Transmit() 时,返回 E_NOT_OK。 2. 清除相关通道的发送缓冲区。 3. 阻止调用上层的接收指示回调函数。 4. 阻止调用上层的发送确认回调函数。 |
| CANIF_TX_OFFLINE_ACTIVE | 1. 调用的 CanIf_Transmit() 时,返回 E_OK,但是不调用 Can 的发送接口发送报文。 2. 调用的 CanIf_Transmit() 时,直接调用上层的发送确认函数。 3. 阻止调用上层的接收指示回调函数。 |
| CANIF_TX_OFFLINE | 1. 阻止发送请求,调用 CanIf_Transmit() 时,返回 E_NOT_OK。 2. 清除相关通道的发送缓冲区。 3. 允许调用上层的接收指示回调函数。 4. 阻止调用上层的发送确认回调函数。 |
| CANIF_ONLINE | 1. 调用 CanIf_Transmit() 时,正常发送报文,返回 E_OK。 2. 报文发送成功时,调用上层的发送确认函数。 3. 接收到报文时,调用上层的接收指示回调函数。 |
收发器模式
在AUTOSAR架构中,CAN收发器(CAN Transceiver)的模式由收发器驱动(CAN Transceiver Driver, CanTrcv)管理,收发器有以下模式:
- 正常模式(
TRCVMODE_NORMAL)- 功能:
- 收发器完全激活,支持差分信号(CAN_H/CAN_L)的发送和接收。
- 符合ISO 11898-2电气标准(显性/隐性电平)。
- 功耗:
- 典型值:5~15mA(取决于型号,如TJA1042)。
- 触发条件:
- 控制器需主动通信(
CANIF_CS_STARTED)。
- 控制器需主动通信(
- 功能:
- 待机模式(
TRCVMODE_STANDBY)- 功能:
- 收发器停止发送,但仍可监听总线活动(接收功能部分激活)。
- 支持硬件唤醒(如总线显性电平触发)。
- 功耗:
- 典型值:100~500μA(如TJA1145)。
- 触发条件:
- 控制器进入
CANIF_CS_STOPPED,但需保留唤醒能力。
- 控制器进入
- 功能:
- 睡眠模式(
TRCVMODE_SLEEP)- 功能:
- 收发器完全关闭,断开与总线的电气连接。
- 仅支持特定唤醒方式(如LIN唤醒、硬件引脚触发)。
- 功耗:
- 典型值:1~10μA(如SIT1145AQ)。
- 触发条件:
- 明确请求深度休眠(如整车电源管理指令)。
- 功能:
收发器模式与其他模块的关系
- 与控制器的联动:
- 控制器模式(
CANIF_CS_STARTED)要求收发器必须处于TRCVMODE_NORMAL。 - 控制器休眠(
CANIF_CS_STOPPED)时,收发器可切换至TRCVMODE_STANDBY或TRCVMODE_SLEEP。
- 控制器模式(
- 与网络管理(NM)的协同:
- NM通过
CanTrcv_SetMode控制收发器状态(如Bus-Sleep时强制TRCVMODE_SLEEP)。
- NM通过
- 与电源管理的交互:
- 部分收发器通过
INH引脚控制外部电源(睡眠时关闭MCU供电)。
- 部分收发器通过
状态切换示例:
唤醒流程(睡眠→正常):
graph TB
A[总线显性电平或硬件唤醒] --> B[CanTrcv_SetMode: TRCVMODE_NORMAL]
B --> C[收发器激活差分驱动]
C --> D[控制器启动: CANIF_CS_STARTED]休眠流程(正常→睡眠):
graph TB
A[NM请求Bus-Sleep] --> B[CanTrcv_SetMode: TRCVMODE_SLEEP]
B --> C[收发器断开总线]
C --> D[控制器停止: CANIF_CS_STOPPED]关键差异总结:
| 模式 | 发送能力 | 接收能力 | 功耗 | 唤醒方式 | 适用场景 |
|---|---|---|---|---|---|
TRCVMODE_NORMAL |
✅ | ✅ | 高(5mA+) | 始终活跃 | 正常通信 |
TRCVMODE_STANDBY |
❌ | ⚠️(部分) | 中(100μA) | 总线显性电平/硬件唤醒 | 低功耗监听 |
TRCVMODE_SLEEP |
❌ | ❌ | 极低(μA) | 特定引脚/LIN/软件指令 | 深度休眠 |
CanNm
[!tip]
标准文件可参见Specification of CAN Network Management (autosar.org)
CanNm模块还有一大堆的细节,大家如果想更深入了解CanNm模块,可参加文章《AUTOSAR CAN NM(CAN网络管理)》。再推荐一篇干货满满的文章:《AUTOSAR架构下关于CanNm的几点思考》。
首先来简单说说NM(网络管理)的概念,现在汽车上ECU非常之多令人乍舌,设备越多,这电就要越扣扣嗖嗖的用,那该怎么省电呢?有一种方法就是在某些用车场景用不到的ECU,那么就让你进入休眠不工作,当需要这个ECU时,再去把你唤醒,而NM就是为了去实现这个省电小技巧基于总线报文而创造出来的一个玩意。
在介绍CanNm模块之前,首先需要搞清楚CanNm模块和NM模块的关系。如下图所示,Nm 模块位于 AUTOSAR 的通信服务层,对上与ComM 交互,对下控制各总线网络管理模块,为 ComM 提供统一的网络管理功能,同时当开启网络协同功能时,协调各总线网络管理模块之间的状态关系。
graph TD
%% 定义节点
subgraph Apps [ ]
direction LR
App1[App]
App2[App]
App3[App]
end
ComM[AUTOSAR ComM]
SM1["<Bus Specific><br/>State Manager"]
SM2["<Bus Specific><br/>State Manager"]
Nm["Generic NM Interface<br/>(Nm)"]
NM_Bus1["<Bus Specific><br/>NM"]
NM_Bus2["<Bus Specific><br/>NM"]
BusIF["<Bus Specific><br/>Interface"]
%% 定义连接关系
App1 & App2 & App3 --- ComM
ComM --- SM1
ComM --- SM2
ComM --- Nm
Nm --- NM_Bus1
Nm --- NM_Bus2
SM1 --- BusIF
SM2 --- BusIF
NM_Bus1 --- BusIF
NM_Bus2 --- BusIF
%% 样式设置
style Apps fill:none,stroke:none
style App1 fill:#A9A9A9,stroke:#333,color:#000,font-weight:bold
style App2 fill:#A9A9A9,stroke:#333,color:#000,font-weight:bold
style App3 fill:#A9A9A9,stroke:#333,color:#000,font-weight:bold
style ComM fill:#4FC3F7,stroke:#333,color:#000,font-weight:bold
style SM1 fill:#81C784,stroke:#333,color:#000,font-weight:bold
style SM2 fill:#81C784,stroke:#333,color:#000,font-weight:bold
style Nm fill:#E1BEE7,stroke:#333,color:#000,font-weight:bold
style NM_Bus1 fill:#E1BEE7,stroke:#333,color:#000,font-weight:bold
style NM_Bus2 fill:#E1BEE7,stroke:#333,color:#000,font-weight:bold
style BusIF fill:#FFD54F,stroke:#333,color:#000,font-weight:boldCanNm模块其实只是CAN总线上的NM,而LIN, FlexRay也有其对应的NM,大家都大同小异,都实现着一模一样的目的,所以对于CanNm模块和NM模块的关系,说得再简单点,NM模块是一个经理,CanNm模块是真正打工人,那么站在NM之上的ComM模块则是老板了,ComM模块后面会介绍到,这里不多说。这里推荐一篇文章,里面详细的讲述了NM模块的一些基本理论知识:《一文搞懂AUTOSAR CanNm模块》。
CanNm 模块主要功能如下:
- 初始化
- 网络管理报文发送
- 网络管理报文接收处理
- 同步睡眠和唤醒功能
- 向应用层提供网络上节点信息
- 降低总线负载机制
CanNM和其他层的依赖关系为:
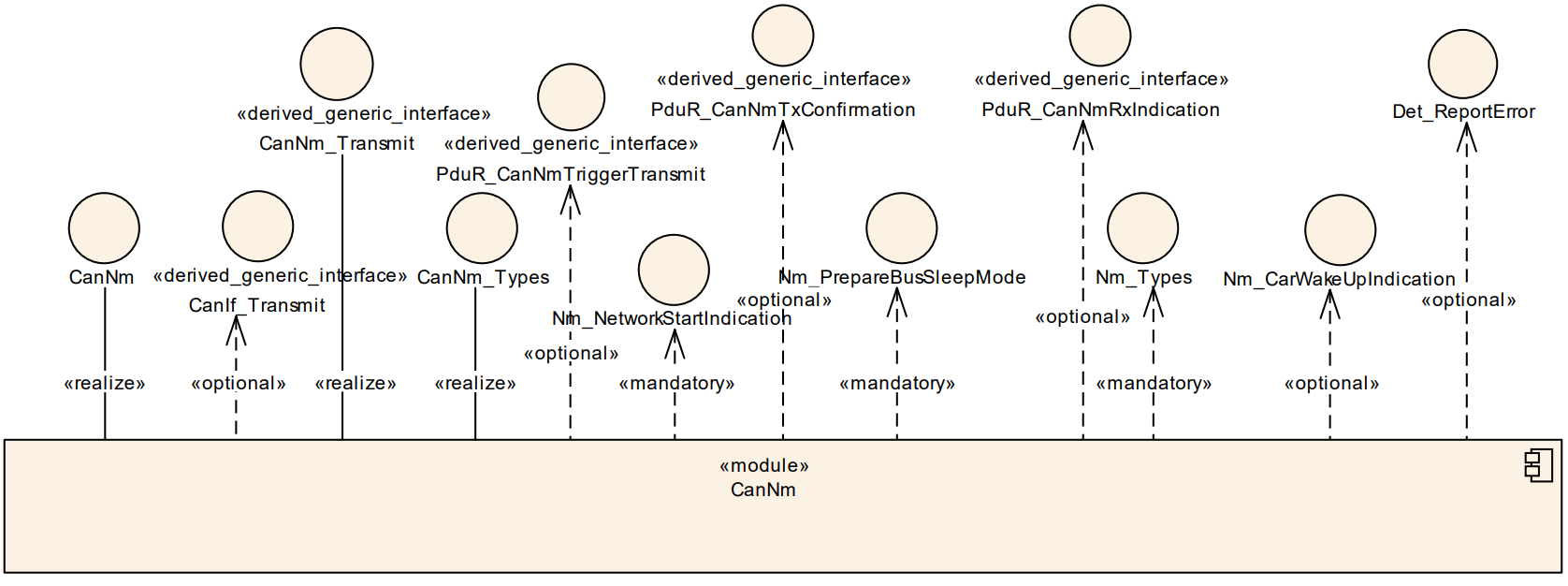
CanNm (CAN Network Management) 的核心原理是基于一种**去中心化(Decentralized)**的直接网络管理策略,即每个节点只根据总线上接收或发送的 NM PDU(网络管理报文)来独立决定自己的状态。
- 核心机制:周期性 NM PDU 与“保持唤醒”,CanNm 的运行逻辑可以类比为一种“心跳”机制:
-
广播通信:每个节点周期性地向网络发送 NM PDU。
-
保持唤醒信号:只要一个节点接收到来自其他任何节点的 NM PDU,就意味着集群中仍有节点需要通信。
-
节点的独立性:节点不需要知道集群中有多少个节点,也不需要主从节点(Master/Slave)的概念。它只关心“总线上是否还有人在说话”。
-
- 进入 Bus-Sleep Mode 的逻辑:从正常运行到进入休眠,必须经过严格的计时逻辑,以确保整个网络同步关闭:
- 主动释放:当节点本身不再需要通信时,它会停止发送自己的 NM PDU。
- 被动等待:即使停止了发送,节点仍必须监听总线。只要收到别人的 NM PDU,就必须维持唤醒状态。
- 计时触发:只有当总线上没有任何 NM PDU 出现,且经过了以下两个时间段的累加后,节点才会进入 Bus-Sleep Mode:
- CanNmTimeoutTime:检测不到 NM PDU 的超时时间。
- CanNmWaitBusSleepTime:进入休眠前的准备/等待时间(用于确保所有节点都已准备就绪)。
- 核心需求:
- 发送准则:只要节点需要总线通信,就必须发送周期性的 NM PDU;不需要时,必须停止发送。
- 休眠准则:如果没有外部报文且自身已释放,经过 Timeout + WaitBusSleep 时间后,必须切换至 Bus-Sleep。
- CanNm 状态机概览
-
CanNm 的状态机是理解其行为的关键。一个节点通常在以下主要状态间切换:
- Bus-Sleep Mode:网络完全静默,控制器可能处于低功耗模式。
- Network Mode:包含以下子状态:
- Repeat Message State:节点刚启动或检测到唤醒时进入,确保所有节点都能看到彼此。
- Normal Operation State:节点正常发送和接收 NM PDU。
- Ready Sleep State:节点自身已准备好休眠,但仍在监听总线上其他节点的报文。
- Prepare Bus-Sleep Mode:总线活动已停止,节点正在等待进入物理休眠。
-
CanNm 的精髓在于其自发性:
- 唤醒:任何节点发送 NM PDU 都能拉起整个集群。
- 维持:只要有人发,大家都不能睡。
- 关闭:只有当所有人都不发且计时结束,大家才整齐划一地睡去。
这种设计具有极高的鲁棒性,因为任何一个节点的故障(只要不乱发报文)都不会阻止其他节点进入休眠或保持唤醒。
操作模式
操作模式转换图如下:
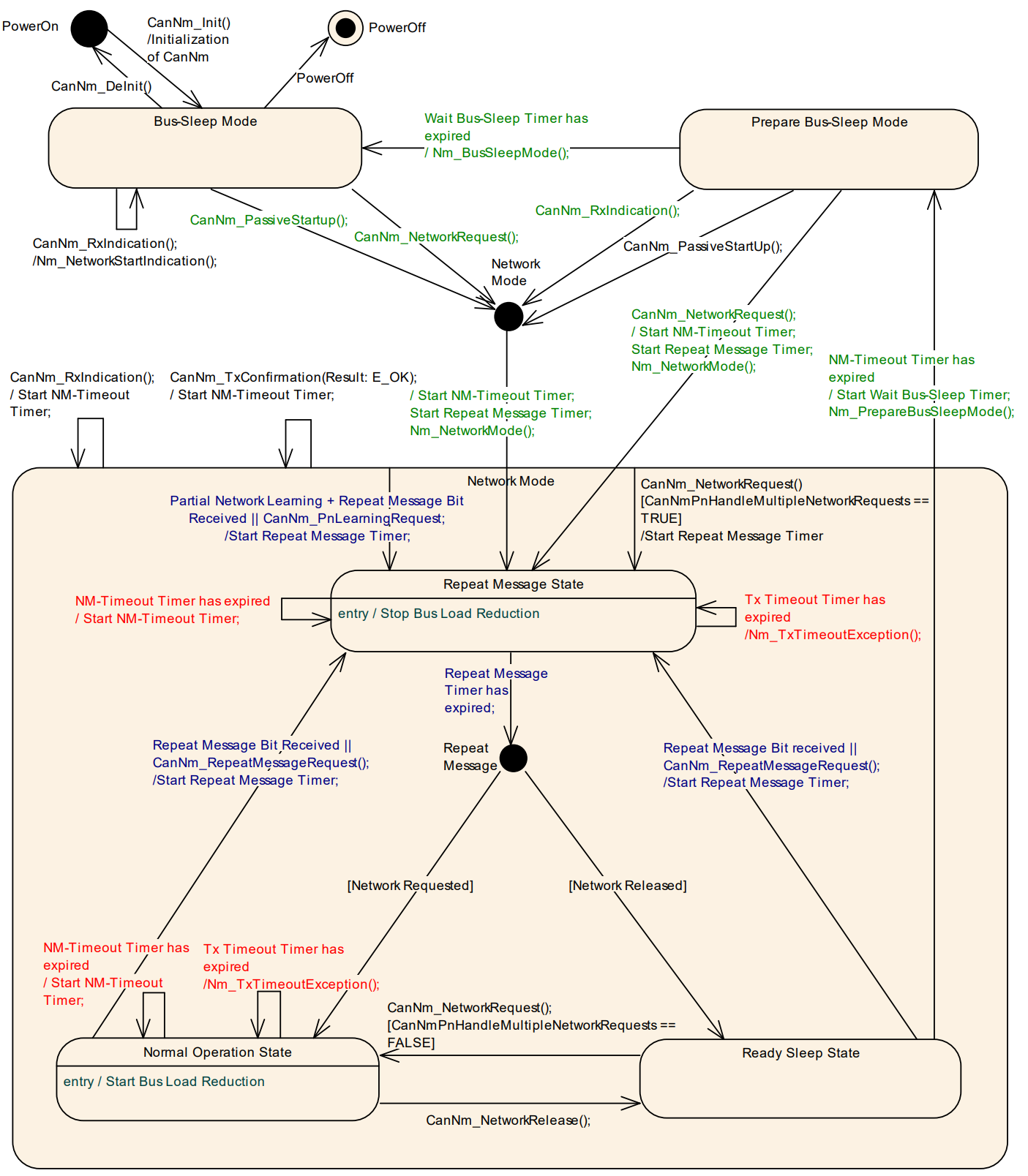
Network Mode
网络模式是 CanNm 状态机中最活跃的部分,其核心职责是通过发送和接收 NM PDU 来维持集群的唤醒状态。网络模式包含三个核心子状态,它们决定了节点是主动“发言”还是被动“监听”:
- Repeat Message State (重复消息状态):通常是进入网络模式的第一站,确保节点在线。
- Normal Operation State (常规运行状态):应用层需要通信时保持心跳的状态。
- Ready Sleep State (准备休眠状态):自身已释放通信,等待其他节点关闭。
- ⏱️ NM-Timeout Timer:网络存活的“呼吸灯”,在网络模式中,所有的活动都围绕着 NM-Timeout Timer 展开。
- 启动与重置:
- 进入模式:一旦从休眠或准备休眠进入网络模式,计时器立即启动。
- 发送确认:每成功发出一个 NM PDU,计时器重置。
- 成功接收:只要收到总线上其他节点的 NM PDU,计时器重置。
- 重要意义:只要计时器在不断重置(因为收到了或发送了报文),节点就会留在网络模式。如果计时器归零,说明总线已经静默,节点将尝试滑向休眠状态。
- 启动与重置:
- 🔄 进入网络模式的默认路径
- 默认入口 :无论是从 Bus-Sleep(冷启动)还是 Prepare Bus-Sleep(唤醒重连)进入网络模式,默认都必须先进入 Repeat Message State,这确保了该节点的存在能够被网络上其他所有节点检测到。
- 上层通知:进入模式时,CanNm 必须通过回调
Nm_NetworkMode通知Nm模块。
- 🧬 部分网络 (Partial Networking) 的动态映射
- PN Learning (PN 学习请求):当系统需要重新映射 PNC 与通道的关系时,会触发学习请求。
- 强制跳转:如果收到或发起了 PN 学习请求,CanNm 必须在 CBV (Control Bit Vector) 字节中设置 Repeat Message Bit 和 Partial Network Learning Bit 为 1,并强制重新进入(Restart) Repeat Message 状态。
- 意义:这通过强制所有相关节点进入重复消息阶段,确保新的网络配置信息能被快速广播并同步。
- 🚫 逻辑约束
- 被动启动限制:如果节点已经在 Network Mode 运行,此时调用 CanNm_PassiveStartUp(通常用于被动唤醒)是非法的,函数会返回 E_NOT_OK。因为节点已经在线,不需要再执行“启动”逻辑。
Repeat Message State
Repeat Message State(重复消息状态) 是网络管理的“声明阶段”,确保节点在进入网络时不仅能被其他节点发现,还能在总线上保持足够的活跃时间。
-
📡 Repeat Message State 的核心作用
- 可见性(Visibility):确保从休眠(Bus-Sleep)或准备休眠(Prepare Bus-Sleep)转换过来的节点能通过发送 NM PDU 让全网感知。
- 节点检测(Node Detection):通过保持一段时间的活跃,方便诊断工具或主节点识别当前总线上有哪些节点在线。
- 最小活跃时间:强制节点至少运行
CanNmRepeatMessageTime这么久,防止网络频繁地在唤醒和休眠之间剧烈抖动。
-
🛠️ 关键行为与需求解析
-
报文发送 :一旦进入此状态,CanNm 必须开始(或重新开始)发送周期性的 NM PDU。这是“我已上线”的物理宣告。
注意:如果配置为被动模式(Passive Mode)或通信被禁用,则不发送。
-
定时器与超时处理:在 Repeat Message 状态下,如果
NM-Timeout Timer到期:-
不会导致休眠:CanNm 会立即重启该计时器。
-
错误报告:它会向 DET 报告
CANNM_E_NETWORK_TIMEOUT。 -
逻辑意义:这说明在 Repeat Message 期间,节点没能从总线上收到任何 NM PDU(包括自己发出的确认),暗示总线可能存在硬件故障或只有自己一个节点。
-
-
状态退出与去向:该状态的停留时间固定由配置参数
CanNmRepeatMessageTime决定。时间一到,节点根据自身的“网络请求状态”决定去向:- 进入 Normal Operation:如果应用层还需要通信(Network Requested)。
- 进入 Ready Sleep:如果应用层已经释放了请求(Network Released)。
-
-
🏁 离开状态时的清理工作
- 当计时结束准备退出 Repeat Message State 时,CanIf 需要清理控制位向量(CBV)中的相关标志:
- **Repeat Message Bit **:如果启用了节点检测,将此位清零。
- **Partial Network Learning Bit **:如果启用了动态 PNC 映射,将学习位清零。
- 当计时结束准备退出 Repeat Message State 时,CanIf 需要清理控制位向量(CBV)中的相关标志:
-
🚫 禁止操作
如果在 Repeat Message State、Prepare Bus-Sleep 或 Bus-Sleep 期间调用
CanNm_RepeatMessageRequest:- 结果:函数直接返回
E_NOT_OK。 - 原因:在这些状态下,系统要么已经在执行重复消息逻辑,要么正处于不可触发该请求的状态。该 API 通常只在
Normal Operation或Ready Sleep状态下使用,用于强制所有节点重新进入 Repeat Message 阶段。
- 结果:函数直接返回
Normal Operation State
Normal Operation State(常规运行状态) 是 CanNm 的核心业务状态:只要应用层(通过 ComM)请求了网络,节点就会留在此状态发送“心跳”,确保整个网络不掉线。
- 🚀 Normal Operation State 的核心职责
- 主动保活:只要本地 ECU 需要使用总线(Network Requested),它就通过周期性发送 NM PDU 来阻止其他节点进入休眠。
- 双向通信:既发送自己的 NM PDU,也监听别人的 NM PDU。
- 🛠️ 关键行为与需求解析
- 恢复发送:如果节点是从 Ready Sleep(只听不发)返回到 Normal Operation(又听又发):
- 动作:CanNm 必须立刻重新开启 NM PDU 的周期性发送。
- 意义:这通常发生在 ECU 本来准备睡觉,但突然应用层又要发数据的情况。
- 定时器异常处理 :在 Normal Operation 状态下,理想情况是不断收到自己发送成功的确认或别人的报文来重置
NM-Timeout Timer。- 异常:如果该计时器到期,说明总线上完全没有通信反馈。
- 处理:CanNm 会重启计时器并向 DET 报告
CANNM_E_NETWORK_TIMEOUT。 - 注意:这不会导致状态跳转,节点会倔强地继续尝试在 Normal Operation 状态发送。
- 释放网络
- 触发:当上层 ComM 调用
Nm_NetworkRelease,表明应用层不再需要总线。 - 动作:节点从 Normal Operation 跳转到 Ready Sleep State。
- 结果:节点停止发送报文,但开始等待全网静默。
- 触发:当上层 ComM 调用
- 强制重入重复消息状态:如果启用了 节点检测(Node Detection):
- 外部触发:收到其他节点发来的 NM PDU,且其 CBV(控制位向量)中的
Repeat Message Request Bit位为 1。 - 内部触发:本地软件调用了
CanNm_RepeatMessageRequest()。 - 动作:节点必须立即跳回 Repeat Message State,并在发送的报文中将
Repeat Message Bit置 1。 - 意义:这用于同步全网节点,让大家一起进入“点名模式”,方便相互识别。
- 外部触发:收到其他节点发来的 NM PDU,且其 CBV(控制位向量)中的
- 恢复发送:如果节点是从 Ready Sleep(只听不发)返回到 Normal Operation(又听又发):
[!note]
💡 深入思考
在 Normal Operation 状态下,发送周期由
CanNmMsgCycleTime决定。如果在这个状态下发生 Bus-Off,CanNm 的状态机本身不会直接崩溃,但由于无法成功发送(收不到 TxConfirmation),NM-Timeout Timer可能会频繁到期并触发 DET 报错。
Ready Sleep State
**Ready Sleep State(就绪休眠状态)**是网络管理中实现“同步关机”的关键环节。在这个状态下,本节点已经不想“说话”了,但它必须留下来陪着总线上其他还在“说话”的节点,直到全场静默。
-
🤫 Ready Sleep State 的核心逻辑
这个状态可以形象地理解为:“我已经准备好睡觉了,但我得等最后一个人关灯。”
-
停止主动发言
- 行为:一旦从 Repeat Message 或 Normal Operation 进入此状态,CanNm 必须停止发送 NM PDU。
- 目的:通过停止自己的心跳,告诉网络其他节点“我已经不再请求网络了”。
- 例外:如果涉及部分网络(Partial Networking),为了确保同步关闭,可能仍会发送特殊的 PN 关闭报文。
-
监听与计时
- 关键动作:节点虽然不发报文,但仍在接收总线上的 NM PDU。
- 重置计时:每当收到总线上其他节点发来的 NM PDU,
NM-Timeout Timer就会重置。 - 跳转条件:只有当
NM-Timeout Timer彻底耗尽(Expire),意味着在配置的时间内总线上没有任何节点发声了,本节点才会进入 Prepare Bus-Sleep Mode。
-
🔄 状态的逆转与中断
- 即使处于准备睡觉的状态,节点也可以被随时拉回活跃状态:
- 应用层反悔:如果在 Ready Sleep 期间,本地应用层(ComM)突然又请求了网络,节点会立即跳回 Normal Operation State 并重新开始发送报文。
- 被要求“点名” :如果启用了节点检测,且收到了带有 Repeat Message Bit 的报文,或者本地触发了 CanNm_RepeatMessageRequest,节点必须跳回 Repeat Message State。
- 即使处于准备睡觉的状态,节点也可以被随时拉回活跃状态:
-
📊 状态行为对比
维度 Normal Operation Ready Sleep 发送 NM PDU ✅ 周期性发送 ❌ 停止发送 接收 NM PDU ✅ 接收并重置计时器 ✅ 接收并重置计时器 超时后果 报 DET 错误,保持原状 跳转至 Prepare Bus-Sleep 本地网络请求状态 Requested (需要总线) Released (释放总线)
Prepare Bus-Sleep Mode
Prepare Bus-Sleep Mode(准备总线休眠模式)。如果说 Ready Sleep 是在等别人关灯,那么 Prepare Bus-Sleep 就是**“最后一次扫除”**——确保所有节点的缓存都清空,总线彻底静默。
- 🧹 Prepare Bus-Sleep Mode 的核心目的
- 在进入物理休眠(Bus-Sleep)之前,必须给硬件驱动和收发器留出一点时间来处理尾声工作:
- 平息总线活动:确保队列中积压的普通应用报文(Application PDUs)全部发出,让所有 Tx-buffers 变为空。
- 软着陆:防止 ECU 还没发完报文就突然断电或进入休眠导致错误。
- 在进入物理休眠(Bus-Sleep)之前,必须给硬件驱动和收发器留出一点时间来处理尾声工作:
- 🛠️ 关键行为与需求解析
- 通知与计时
- 通知上层:进入该模式时,通过
Nm_PrepareBusSleepMode回调通知上层(通常是ComM或CanSm)。 - 停留时间:由参数
CanNmWaitBusSleepTime决定。 - 无限停留模式:如果配置了
CanNmStayInPbsEnabled = TRUE,节点将永远停留在此模式而不会进入 Bus-Sleep。这常用于某些需要保持控制器供电但不通信的特殊测试或特定 ECU 电源策略。
- 通知上层:进入该模式时,通过
- 紧急唤醒与重返 :即使是在“清扫阶段”,节点也可以被随时拉回:
- 外部唤醒:只要在总线上收到了 NM PDU,说明其他节点还没睡,必须立刻返回 Network Mode(进入 Repeat Message 状态)。
- 内部请求:本地应用层突然请求网络,同样跳回 Network Mode。
- 立即重启机制 :这是为了应对一个竞争风险:
- 场景:当本节点在 Prepare Bus-Sleep 模式下收到请求准备重回网络时,其他节点可能还在 Prepare Bus-Sleep 模式中,并且很快就要滑入真正的休眠了。
- 策略:如果开启了
CanNmImmediateRestartEnabled,节点在切换到 Network Mode 的瞬间会立即发送一条 NM PDU。 - 意义:NM PDU 通常有发送偏移(Offset),如果等周期发送可能太慢了。通过立即发送,可以“大喊一声”叫醒那些正准备睡觉的其他节点,防止网络意外中断。
- 通知与计时
- 📋 模式对比:Ready Sleep vs. Prepare Bus-Sleep
| 特性 | Ready Sleep | Prepare Bus-Sleep |
|---|---|---|
| 计时器 | NM-Timeout Timer |
CanNmWaitBusSleepTime |
| 总线活动 | 可能还有其他节点在发报文 | 理论上总线已经静默 |
| 主要动作 | 监听并重置计时器 | 等待缓冲区清空 |
| 收到 NM PDU | 留在 Ready Sleep (重置计时) | 跳回 Network Mode |
Prepare Bus-Sleep 是进入休眠前的**“安全检查站”**。它确保了:
- 通信是优雅地停止而非骤停。
- 只要网络有变,能以**最快速度(Immediate Tx)**恢复通信。
Bus-Sleep Mode
**Bus-Sleep Mode(总线休眠模式)**是网络管理的终点,也是 ECU 节能的核心阶段。在此模式下,节点不仅停止了所有通信,还开启了“监听唤醒”的低功耗监控逻辑。
- 🔋 Bus-Sleep Mode 的核心目的与行为
- 节能降耗:CAN 控制器切换到 Sleep 状态,硬件唤醒机制(如收发器的 WUP 检测)被激活,ECU 功耗降至最低。
- 全网同步休眠:
- 计算公式:进入休眠的总时间 = $CanNmTimeoutTime + CanNmWaitBusSleepTime$。
- 同步性:如果全网节点配置了相同的这两个参数,理论上它们会几乎同时进入休眠。
- 抖动(Jitter)因素:实际上受晶振漂移(Drift)、任务周期(Task Cycle)以及发送确认延迟的影响,各节点进入休眠的时间点会有微小差异。
- 🚨 唤醒逻辑:为什么不自动跳转?
- 这是一个非常关键的设计点 :如果在 Bus-Sleep 模式下收到了 NM PDU(由于硬件可能已部分唤醒或正在启动),CanNm 不会直接跳回 Network Mode。
- 处理方式:它仅调用回调函数
Nm_NetworkStartIndication通知上层。 - 设计初衷(Rationale):
- 为了防止竞态条件(Race Conditions)。
- 唤醒决策权属于上层模块(如
EcuM或ComM)。上层需要判断当前 ECU 是正在执行关机序列还是刚准备启动,从而决定是否允许网络层重新激活。
- **异常记录 **:在休眠状态下收到报文会被视为一种异常指示,会向 DET 报告
CANNM_E_NET_START_IND。
- 处理方式:它仅调用回调函数
- 这是一个非常关键的设计点 :如果在 Bus-Sleep 模式下收到了 NM PDU(由于硬件可能已部分唤醒或正在启动),CanNm 不会直接跳回 Network Mode。
- 🔄 离开休眠模式的路径:离开 Bus-Sleep 进入 Network Mode(默认进入 Repeat Message 状态)只有两种合规途径:
- 被动启动
- 触发:上层调用
CanNm_PassiveStartUp。 - 含义:这通常意味着 ECU 检测到了外部唤醒源(如总线上的 NM 报文),上层决定响应该请求并启动网络管理。
- 触发:上层调用
- 主动请求
- 触发:本地应用层(ComM)请求网络(Network Requested)。
- 含义:ECU 自身需要发送数据,因此主动唤醒并请求进入网络。
- 被动启动
- 📝 CanNm 状态切换总结表
| 模式 | 控制器状态 | 报文发送 | 接收处理 | 跳转至下一步的触发点 |
|---|---|---|---|---|
| Network | STARTED |
✅ 周期发送 | ✅ 重置 $NM-Timeout$ | 本地释放且 $NM-Timeout$ 到期 |
| Prepare Bus-Sleep | STARTED |
❌ 停止发送 | ✅ 收到报文则跳回 Network | $WaitBusSleepTime$ 到期 |
| Bus-Sleep | SLEEP |
❌ 彻底静默 | 🔔 仅通知上层 (Indication) | 收到请求或被动启动 API 调用 |
相关参数
时间参数
| 计时参数 | 功能描述 | 核心作用 |
|---|---|---|
| CanNmTimeoutTime | NM 超时时间。在该时间内如果没有收到或发出 NM PDU,则认为总线已静默。 | 判定总线上是否还有其他活跃节点。 |
| CanNmRepeatMessageTime | 重复消息时间。节点处于 Repeat Message State 的固定持续时间。 |
确保节点上线后有足够的曝光时间,用于节点发现。 |
| CanNmWaitBusSleepTime | 等待总线休眠时间。从检测到总线静默到进入物理休眠之间的缓冲时间。 | 确保所有节点清空缓冲区,实现“软着陆”同步休眠。 |
| CanNmRemoteSleepIndTime | 远端休眠指示时间。如果在该时间内没收到某节点的 NM 报文,则认为该远端节点已准备休眠。 | 用于检测网络中其他节点是否已经释放了网络请求。 |
通过过程可以清晰地看到这些时间参数如何驱动状态机的跳转:
- 启动阶段:进入网络模式后,强制停留
CanNmRepeatMessageTime时长。 - 运行阶段:每次收到或发送 NM PDU,内部的
NM-Timeout Timer就会被重置为CanNmTimeoutTime。 - 准备阶段:当
NM-Timeout Timer减到 0 时,说明总线静默,进入Prepare Bus-Sleep,启动CanNmWaitBusSleepTime计时。 - 休眠阶段:
WaitBusSleep计时结束,进入Bus-Sleep。
[!note]
🔍 什么是 Remote Sleep Indication (远端休眠指示)?
这是一个经常被误解的参数。
- 逻辑:如果一个节点在
CanNmRemoteSleepIndTime时间内没有收到任何其他节点的 NM 报文,它会向应用层发送一个“远端休眠指示”通知。- 应用:这并不直接导致状态跳转,但它可以告诉应用层(通过
Nm_RemoteSleepIndication回调):“目前总线上似乎只有我一个人想保持唤醒了,其他人可能都已经释放了请求。”
⚠️ 配置一致性要求
为了保证全网同步,通常要求同一个 CAN 网络(NM Cluster)中所有节点的以下两个参数必须完全一致:
- CanNmTimeoutTime
- CanNmWaitBusSleepTime
如果配置不一致,会导致某些节点过早进入休眠(产生“僵尸节点”)或某些节点迟迟不肯休眠,从而导致蓄电池耗尽。
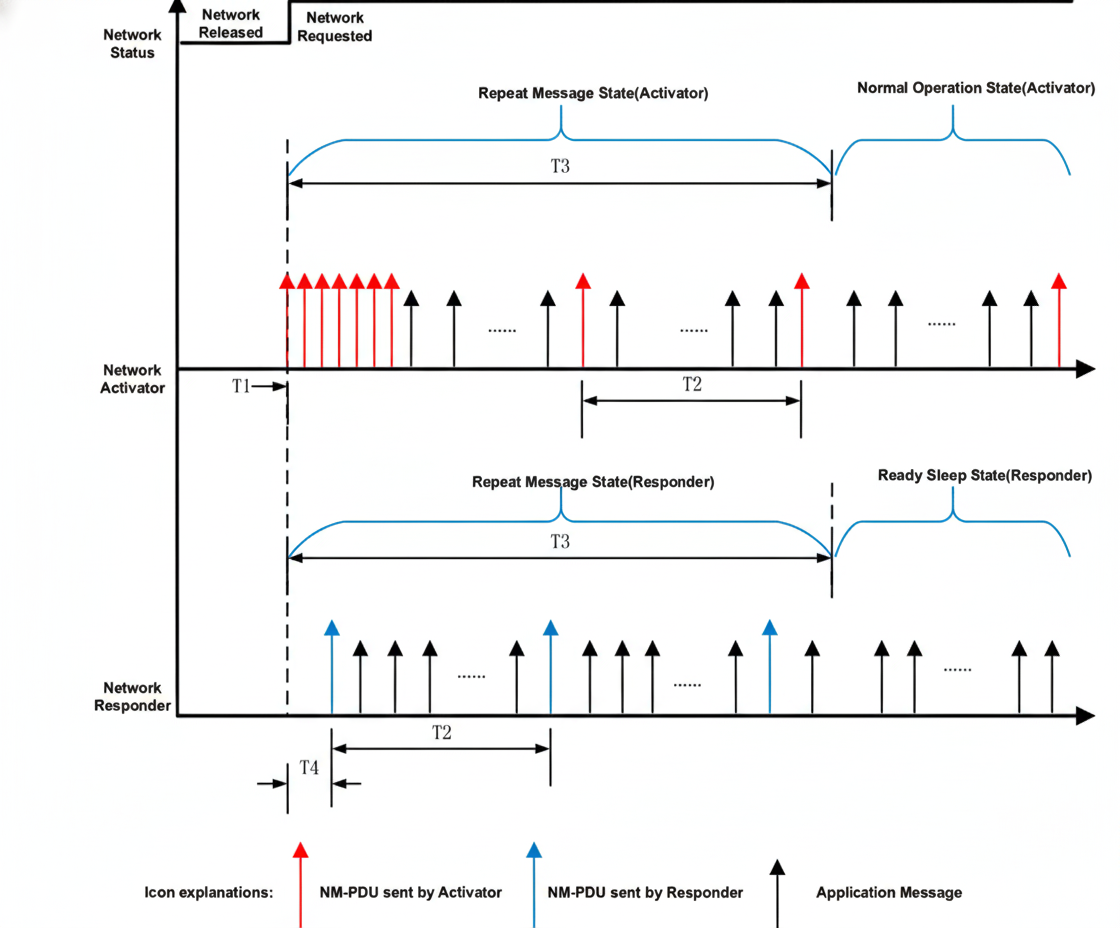
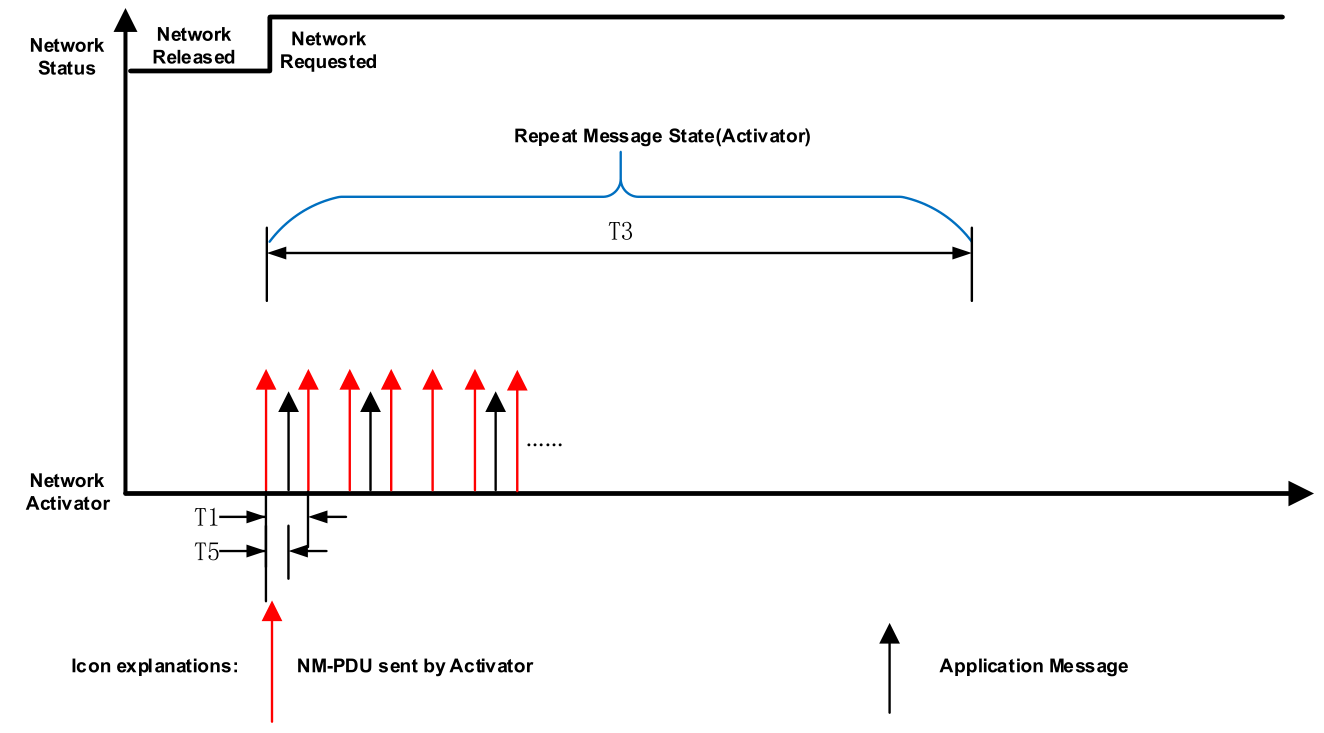
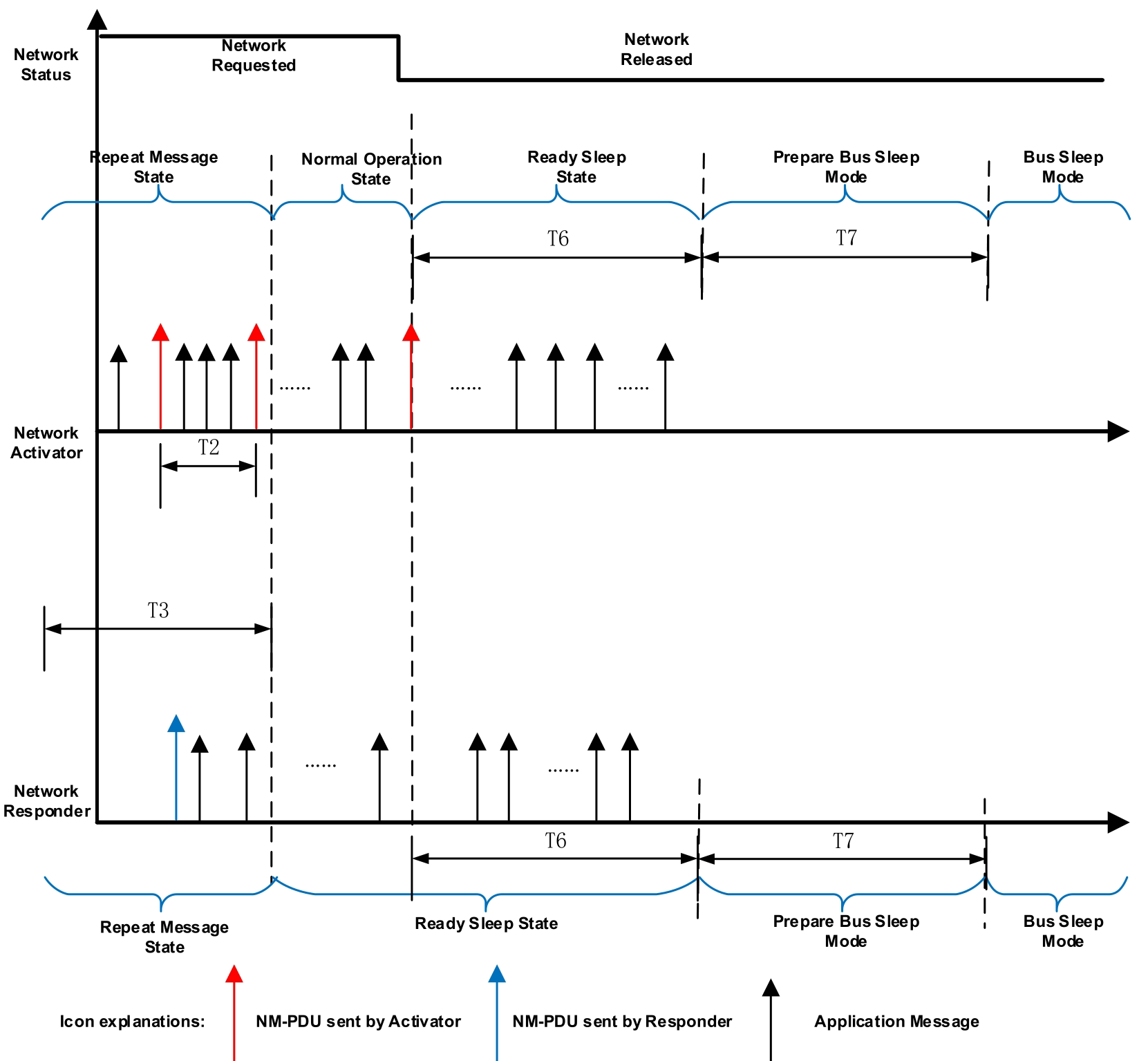
T1: T_NM_ImmediateCycleTime 快速发送子状态下,网络管理报文发送周期;T2: T_NM_MessageCycle 正常发送子状态下,网络管理报文发送周期;T3: T_REPEAT_MESSAGE 节点对于网络上的其他节点的可视时间;T4: NmAsrCanMsgCycleOffSet 被动唤醒节点收到主动唤醒节点的第一帧网络管理报文到自身发出网络管理报文的时间间隔,用于避免网络堵塞。T5: T_STARTx_AppFrame 成功发送第一帧网络管理报文后开始发送应用报文最大间隔时间。T6: T_NM_TIMEOUT 当此定时器到期时,节点将进入预睡眠模式;T7: T_WAIT_BUS_SLEEP 确保所有节点有时间停止其网络活动。
PDU格式
通过控制位向量 (CBV) ,网络中的 ECU 可以交换关键信息,如:谁发出的报文、是否请求重启计时、以及哪些“部分网络”需要激活。
📦 NM PDU 的结构布局为:
| 字节序列 | 数据描述 |
|---|---|
| Byte 7 | PNC data 3 |
| Byte 6 | PNC data 2 |
| Byte 5 | PNC data 1 |
| Byte 4 | PNC data 0 |
| Byte 3 | User data 1 |
| Byte 2 | User data 0 |
| Byte 1 | Control Bit Vector |
| Byte 0 | Source Node Identifier |
- 系统字节 (System Bytes)
- **SNI (Source Node Identifier) **: 发送节点的 ID。位置可配置在 Byte 0、Byte 1 或关闭(Off)。如果关闭,该字节可腾给用户数据。
- **CBV (Control Bit Vector) **: 控制位向量。位置同样可配置在 Byte 0、Byte 1 或关闭。
- 部分网络向量 (PNC Bit Vector)
- 如果开启了 Partial Networking (PN),报文中会包含 PNC 位向量。它的起始位置(Offset)和长度(Length)都是可调的。
- 用户数据 (User Data)
- 除去系统字节和 PNC 向量后,剩余的字节统称为用户数据。
- 布局规则:用户数据必须是连续的,通常位于系统字节之后、PNC 向量之前,或者 PNC 向量之后直到报文末尾。
🕹️ 控制位向量 (CBV) 位定义:CBV 是 NM PDU 的“指挥中心”,每一位(Bit)都承载特定的控制逻辑:
| 位 (Bit) | 名称 | 描述 |
|---|---|---|
| Bit 0 | Repeat Message Request | 1: 请求全网进入重复消息状态(点名模式)。 |
| Bit 1 | PN Shutdown Request | 1: 包含同步的部分网络关闭请求。 |
| Bit 3 | NM Coordinator Sleep | 1: 协调器请求开始同步关机。 |
| Bit 4 | Active Wakeup Bit | 1: 本节点是主动唤醒者(即因为自己需要通信而唤醒总线)。 |
| Bit 5 | PN Learning Bit | 1: 请求进行部分网络学习/映射。 |
| Bit 6 | PN Information Bit | 1: 表示报文中包含有效的 PNC 激活信息。 |
| Bit 7 | Res | 保留 |
对于 CBV 中的 bit 说明如下:
- Bit 0 :重复消息请求
- 0:未请求进入 Repeat Message State
- 1:请求进入 Repeat Message State
- Bit 1,2:保留位,当配置项 CanNmCoordinatorEnabled 使能时,该位等于配置的 CanNmCoordinatorId 的值
- Bit 3 NM 协调器休眠位
- 0:主协调器不要求启动同步休眠
- 1:主协调员请求启动同步休眠
- Bit 4 主动唤醒位
- 0:节点尚未唤醒网络
- 1:节点唤醒了网络
- Bit 6: 局部网络信息位(PNI)
- 0:NM 消息不包含局部网络请求信息
- 1:NM 消息包含局部网络请求信息,该位由配置决定,运行阶段不改变
- Bit5 Bit7 为保留位
NmPdu 中的 UserData 可以通过 CanNm 的配置引用 EcuC 中的 Pdu。未使用的情况下默认全 0xFF,通过 Nm 的接口去抓取当前接收与发送的 UserData。
[!tip]
🚀 主动唤醒位 (Active Wakeup Bit) 的逻辑
这是一个非常重要的诊断和逻辑标志:
- 设置时机:当 ECU 从
Bus Sleep或Prepare Bus Sleep切换到Network Mode是因为本地调用了CanNm_NetworkRequest(即本地应用需要唤醒总线)时,CBV 中的 Active Wakeup Bit 被置为 1。- 清除时机:当节点离开网络模式(准备休眠)时,该位被清零。
- 意义:这允许网络中的其他节点通过查看 NM 报文知道“是谁把大家叫醒的”。
假设一个典型的 8 字节报文配置:
- Byte 0: 发送者 ID (SNI)。
- Byte 1: 控制标志 (CBV),例如
0x10表示主动唤醒。 - Byte 2-3: 自定义的用户数据(如车辆状态信息)。
- Byte 4-7: PNC 位向量,标志着哪些局部网络簇需要保持工作。
工作流
网络状态
除了模式(Network, Bus-Sleep)这种全局状态外,CanNm 还维护着一个内部意图状态。这反映了本地 ECU “主观上”是否想留在总线上。
- **Requested (已请求) **:
- 触发:上层(ComM)调用
CanNm_NetworkRequest。 - 意义:本地应用 SWC 需要发送数据。即使总线上没有别人,我也要通过发 NM 报文来保持网络唤醒。
- 触发:上层(ComM)调用
- **Released (已释放) **:
- 触发:上层调用
CanNm_NetworkRelease。 - 意义:本地应用不需要总线了。
- 重要特性:网络被释放不代表通信立刻停止。如果总线上还有其他 ECU 在发报文(即其他 ECU 处于 Requested),本节点仍会留在 Network Mode 并保持监听。
- 触发:上层调用
初始化
初始化是将 CanNm 从未定义状态带入确定的、安全的初始状态的过程。
-
核心状态设置
- **默认模式 **:初始化成功后,节点必须进入 Bus-Sleep Mode。
- **默认意图 **:网络状态默认为 Released(即默认不想主动唤醒总线)。
-
静态配置与重置
- **配置选择 **:通过指针选择预定义的配置集(如波特率、计时器数值等)。
- **禁止发送 **:初始化后必须停止
Message Cycle Timer。此时不准发送任何 NM PDU,直到被明确请求。 - **总线负载 **:停用“总线负载降低(Bus Load Reduction)”功能,确保初始通信的鲁棒性。
-
数据与控制位的初始值:初始化时,CanNm 会对报文中的控制信息进行“清零”或“预置”:
字段** 初始值 备注 User Data 0xFF 每个字节均设为 0xFF。 Control Bit Vector (CBV) 0x00 初始不设置任何标志位(如 Repeat Message 或 PN 位)。 **PNC Bit Vector ** 0x00 如果启用了部分网络(PN),所有的 PNC 位向量清零。 -
关于部分网络 (PN) 的特殊逻辑
- 如果启用了
CanNmGlobalPnSupport,初始化时会停止NM Message Tx Timeout Timer。 - 原因:在 PN 场景下,报文的发送往往由特定的过滤逻辑触发。在系统未完全启动并确定哪些“部分网络”需要激活之前,不应启动发送监控计时器,以避免产生错误的超时上报。
- 如果启用了
规范特别指出了一点:CanNm 必须在 CanIf 初始化之后进行初始化。
- CanIf_Init: 准备好 CAN 通道。
- CanNm_Init: 状态机进入
Bus-Sleep,意图设为Released,CBV 清零。 - ComM/CanSm: 随后调用 API 来真正开启网络。
发送
CanNm 的发送行为主要取决于节点当前处于状态机的哪个位置。
- 核心发送模式:
- **周期性发送 (Periodic Transmission) **:
- 适用状态:Repeat Message State 和 Normal Operation State。
- 机制:根据
CanNmMsgCycleTime定时器循环发送 NM PDU。
- **总线负载降低模式 (Bus Load Reduction) **:
- 适用状态:仅限 Normal Operation State。
- 机制:采用特殊算法(如基于特定位变化的发送)来减少总线报文总量,优化带宽。
- **周期性发送 (Periodic Transmission) **:
- 立即发送机制 (Immediate NM Transmissions):这是为了解决“唤醒太慢”的问题。在传统的周期性发送中,第一条报文可能因为 Offset 延迟。
- 触发场景:
- 由于本地调用
CanNm_NetworkRequest(主动唤醒)进入 Repeat Message 状态。 - 配置了
CanNmPnHandleMultipleNetworkRequests且在网络模式下再次收到请求。
- 由于本地调用
- 行为:
- 跳过 Offset:第一条报文立即发出。
- 爆发式发送 (Burst):随后的
CanNmImmediateNmTransmissions次发送将使用更短的CanNmImmediateNmCycleTime。 - 重试逻辑:如果
CanIf_Transmit返回失败,CanNm 会在下个MainFunction中立即重试,直到成功发完指定的 Burst 次数。
- 触发场景:
- 定时器管理与冲突处理
- 启动偏移:如果不是因为主动唤醒进入状态,第一条报文会延迟
CanNmMsgCycleOffset再发出,以错开网络中不同节点的发送峰值。 - **同步 PNC 关闭优先 **:
- 如果启用了 Synchronized PNC Shutdown 且当前有待处理的关闭请求,周期性的 NM 报文发送会推迟。
- 原因:关闭指令具有最高优先级,必须立即发送,哪怕会延误一个 MainFunction 周期。
- 安全余量:设计时需确保 $(CanNmPnResetTime - CanNmMsgCycleTime) > n * MainFunctionPeriod$,以容忍这种推迟。
- 启动偏移:如果不是因为主动唤醒进入状态,第一条报文会延迟
- 虚拟发送确认 (Immediate Tx Confirmation)
- 常规方式:CanNm 发出请求 -> CanIf 转发 -> CanDrv 发出成功 -> 回调 CanIf -> 回调 CanNm(TxConfirmation)。
- 立即确认模式:CanNm 调用
CanIf_Transmit后,系统立即模拟一个发送成功的回调给 CanNm。 - 适用场景:离线设计已经规划好 arbitration time 的系统,不关心硬件层面的实际确认,以节省中断处理和函数调用链产生的执行开销。
📝 关键参数汇总
| 配置参数 | 描述 |
|---|---|
CanNmMsgCycleTime |
常规周期发送间隔(通常为 100ms - 1000ms)。 |
CanNmImmediateNmCycleTime |
快速爆发发送的间隔(通常为 10ms - 20ms)。 |
CanNmImmediateNmTransmissions |
进入 Repeat Message 后立即发送的报文数量。 |
CanNmMsgCycleOffset |
节点启动发送时的随机/固定偏移量,防止总线拥堵。 |
CanNm 的发送逻辑非常严密:平时按部就班地发“心跳”(周期发送);遇到唤醒或紧急需求时,立刻开启“大声呼喊”模式(立即发送);在面临 PNC 关闭等关键操作时,懂得“让路”优先保障核心指令。
接收
当 CanIf 模块在总线上识别并接收到一条网络管理报文时,它会触发 CanNm_RxIndication。这是 CanNm 处理外部网络状态的起点。
📥 接收指示(RxIndication)的核心行为
CanNm 在收到该回调时的首要任务是数据同步:
- 原子性拷贝:CanNm 必须立即将接收到的 NM PDU 数据(包含控制位 CBV、节点 ID 以及用户数据)从 CanIf 指向的临时缓冲区拷贝到 CanNm 内部定义的影子缓冲区(Internal Buffer) 中。
- 目的:
- 数据一致性:CanIf 的缓冲区可能会在下一个 MainFunction 周期之前被新的报文覆盖。拷贝到内部确保了 CanNm 在后续的逻辑处理(如状态机跳转判断)中使用的是最新且完整的快照。
- 解耦处理:允许接收中断快速返回,而复杂的协议逻辑(如 PNC 位向量分析、节点检测等)可以在
CanNm_MainFunction中异步处理。
🔄 接收后的连锁反应
成功接收还会触发以下逻辑:
-
重启计时器 :
如果当前处于 Network Mode,NM-Timeout Timer 会被重置,防止节点进入休眠。
-
状态监控:
如果当前处于 Bus-Sleep,会触发 Nm_NetworkStartIndication 通知上层有外部唤醒。
-
解析控制位 (CBV):
CanNm 会检查拷贝后的数据中 Repeat Message Bit 是否为 1。如果是,且启用了节点检测,本地节点将准备跳转回 Repeat Message State。
-
部分网络 (PN) 过滤:
如果启用了 PN,CanNm 会解析 PDU 中的 PNC Bit Vector。只有当收到的 PNC 与本地感兴趣的 PNC 匹配时,才会进一步重置对应的 PnResetTimer。
📝 CanNm 处理报文的“三步走”
- 触发:硬件接收 ->
CanIf_RxIndication->CanNm_RxIndication。 - 拷贝:将数据存入内部 Buffer。
- 处理:在下一个周期中,根据 Buffer 里的 CBV 和数据更新计时器和状态机。
降低总线负载机制
在大型网络(如拥有 30 个 ECU 的 CAN 网络)中,如果每个节点都在 Normal Operation 状态下每 100ms 发送一次 NM PDU,总线负载会非常高。该机制的核心目标是:无论网络中有多少个节点,确保每个周期内总线上最多只出现两条 NM 报文。
⚖️ 总线负载削减的核心算法
这个算法利用了每个节点配置的微小时间差异(CanNmMsgReducedTime)来实现“优胜劣汰”:
- 发送后行为:当本节点发送了一条 NM PDU,它将定时器重置为标准周期
CanNmMsgCycleTime。 - 接收后行为:当本节点收到别人的 NM PDU,它将定时器重置为一个缩短的时间
CanNmMsgReducedTime。- 约束条件:$\frac{1}{2} CanNmMsgCycleTime < CanNmMsgReducedTime < CanNmMsgCycleTime$。
[!note]
- 由于 $ReducedTime < CycleTime$,那些收到报文的节点会比刚发完报文的节点更早触发定时器。
- 通过精细配置每个节点的
CanNmMsgReducedTime,系统会自动演变成:只有两个ReducedTime最小的节点在交替发送报文。- 其他节点因为一直在接收报文并不断重置较短的定时器,它们的
CycleTime永远无法归零,从而保持沉默。
🔄 状态切换与机制激活
该机制并不是一直开启的,它只在稳定的通信阶段生效:
- 进入 Repeat Message 禁用 :进入 Repeat Message State 时必须禁用此机制。
- 原因:该状态是为了“节点发现”,必须让所有节点都有机会发声,不能被削减。
- 进入 Normal Operation 启用:进入 Normal Operation 且配置开启时,激活此机制。
- 原因:此时网络已稳定,只需维持唤醒,不需要所有人都发声。
📋 负载削减逻辑对比
| 场景 | 定时器重置值 | 结果 |
|---|---|---|
| 未启用负载削减 | 无论是发还是收,均设为 CanNmMsgCycleTime |
所有节点周期性齐射报文。 |
| 启用负载削减 (发送后) | CanNmMsgCycleTime |
刚发完的节点暂时进入长周期等待。 |
| 启用负载削减 (接收后) | CanNmMsgReducedTime |
听众节点进入短周期等待,准备“抢答”。 |
🛡️ 鲁棒性保障
该算法具有自动冗余特性:
- 如果当前负责发送的两个节点中有一个故障(停止发送),下一个
CanNmMsgReducedTime最小的节点会发现定时器归零,从而自动接替成为新的“发言人”。 - 如果整个网络只有本节点需要通信,它会退化为每
CanNmMsgCycleTime发送一次的标准模式。
总线负载削减机制通过简单的**“谁听到了报文,谁就缩短下一次发送等待时间”**的逻辑,实现了分布式竞选。它既保证了总线永远有“心跳”维持唤醒,又避免了节点过多导致的通信拥堵。
远程睡眠指示
Remote Sleep Indication(远端休眠指示) 机制是一种“软检测”功能,让一个依然处于活跃状态的节点能够感知到:“虽然我还在发报文保活,但总线上其他所有人都已经想睡觉了。”
🧐 什么是远端休眠指示?
在复杂的网络中,可能只有一个 ECU(例如网关)因为某些后台任务需要保持总线唤醒,而其他 ECU 已经完成了工作并进入了 Ready Sleep State(只听不发)。
- 核心逻辑:如果一个处于
Normal Operation的节点在CanNmRemoteSleepIndTime时间内没有收到来自任何其他节点的 NM PDU,它就推断出其他节点都已经释放了网络请求。
- 触发通知
- 触发条件:在
Normal Operation State下,连续CanNmRemoteSleepIndTime时间未收到 NM PDU。 - 动作:调用回调函数
Nm_RemoteSleepIndication通知上层(Nm/ComM)。 - 配置:必须将
CanNmRemoteSleepIndEnabled设置为 TRUE 才能启用此检测。
- 触发条件:在
- 状态取消(Cancellation)
- 如果之前已经检测到了远端休眠,但在以下情况发生时,必须调用
Nm_RemoteSleepCancellation通知上层“有人醒了”:- **收到报文 **:在
Normal Operation或Ready Sleep状态下再次收到了 NM PDU。 - **进入点名模式 **:节点重新进入了
Repeat Message State(这通常意味着有新的节点加入或有人发起了重置请求)。
- **收到报文 **:在
- 如果之前已经检测到了远端休眠,但在以下情况发生时,必须调用
- API 调用限制
- 约束:只有在
Normal Operation或Ready Sleep状态下检查远端休眠才有意义。 - 禁止:在
Bus-Sleep、Prepare Bus-Sleep或Repeat Message状态下调用CanNm_CheckRemoteSleepIndication将直接返回E_NOT_OK。
- 约束:只有在
📊 为什么需要这个功能?
Remote Sleep Indication 对系统设计有以下几个重要帮助:
- 诊断与监控:帮助网关或主节点监控网络节点的活跃度。
- 电源管理优化:上层 ComM 可以根据此指示决定是否可以提前关闭某些非必要的后台服务,因为除了自己,没有其他 ECU 需要这些服务了。
- 防止“僵尸”节点:如果一个节点一直请求网络却不知道其他人都想睡了,这可能暗示某种系统级的逻辑设计问题。
为了防止混淆,请看这两个相似但用途完全不同的计时器:
| 计时器参数 | 监控对象 | 超时后果 |
|---|---|---|
CanNmTimeoutTime |
整个网络的存活 | 判定总线静默,触发状态跳转(去睡觉)。 |
CanNmRemoteSleepIndTime |
其他节点的意图 | 仅发送回调通知,不改变节点当前状态。 |
注意: 通常配置 $RemoteSleepIndTime < TimeoutTime$,这样节点可以在网络真正关闭之前,先得到“远端已准备好休眠”的预警。
用户数据
- 传统 API 方式:Set/Get User Data:这是最直接的数据交换方式,通过 CanNm 模块提供的专用 API 手动管理数据。
- 发送 :上层调用
CanNm_SetUserData。CanNm 会将这些数据存入内部 Buffer,并在下一次发送 NM PDU 时将其发出。 - 接收:上层调用
CanNm_GetUserData。CanNm 返回最近一次收到的 NM PDU 中的数据。 - 状态约束:
- Repeat Message:肯定会发送用户数据。
- Normal Operation:如果开启了负载削减,只有“胜出”的发送节点会发出用户数据。
- Ready Sleep:不发送用户数据(因为停止了发送)。
- 发送 :上层调用
- COM 映射方式:COM User Data:在现代 AUTOSAR 架构中,更常见的做法是将 NM 用户数据直接映射到 COM 栈。这样应用层可以像处理普通信号一样处理 NM 数据,无需直接调用 CanNm API。
- 核心逻辑与约束
- **API 互斥 **:一旦启用了
CanNmComUserDataSupport,手动设置数据的 APICanNm_SetUserData将失效。 - 触发获取:当 CanNm 准备发送报文时,它会通过 PduR_CanNmTriggerTransmit 向上层(COM 模块)“索取”最新的 I-PDU 数据,并将其与 NM 控制字节(SNI/CBV)合并。
- 错误处理 :如果 PduR 获取数据失败,CanNm 会使用上一次发送成功的旧数据。
- **API 互斥 **:一旦启用了
- 确认与同步
- 发送确认 :当硬件确认报文发出后,CanNm 会调用
PduR_CanNmTxConfirmation,最终由 COM 模块更新其信号状态。 - **长度匹配 **:在配置工具生成代码时,NM PDU 中预留的用户数据字节数必须与 COM 中定义的 I-PDU 长度完全匹配,否则会报错。
- 发送确认 :当硬件确认报文发出后,CanNm 会调用
- 核心逻辑与约束
- 数据流对比:API vs COM
| 特性 | API 方式 (CanNm_SetUserData) | COM 方式 (CanNmComUserDataSupport) |
|---|---|---|
| 数据源 | 应用层手动调用 API | COM 模块的 I-PDU 信号 |
| 数据更新 | 异步(调用即更新 Buffer) | 同步(在发送瞬间通过 PduR 抓取) |
| 上层透明度 | 需要感知 NM 模块 | 就像读写普通 CAN 信号一样 |
| 典型应用 | 简单的节点 ID 或基础状态 | 复杂的跨模块协同信息 |
[!note]
💡 关键提示:TriggerTransmit (触发发送)
规范中提到的 TriggerTransmit 机制非常重要。
- 如果
CanIfTxPduTriggerTransmit为 FALSE:CanNm 主动通过 PduR 拉取数据再发送。- 如果为 TRUE(通常用于 TTCAN 或严格时间触发网络):CanNm 只发出长度请求,实际数据会在更底层的
CanNm_TriggerTransmit回调中从 PduR 获取。
通过 CanNmComUserDataSupport,AUTOSAR 实现了 “管理面” (NM) 与 “数据面” (COM) 的解耦。这使得开发人员可以利用已有的信号处理逻辑(如信号超时监控、信号过滤)来处理网络管理报文里的负载数据。
PN
在汽车电子(AUTOSAR)领域,PN (Partial Networking,部分网络) 的核心作用是:“按需唤醒,节能减排”。
在没有 PN 技术的传统网络中,只要总线上一台 ECU 发出唤醒信号,全车几十个甚至上百个 ECU 都会被同时叫醒。这种“一人开灯,全家不睡”的模式在电动化和高度智能化的今天,会产生严重的电能浪费。
以下是 PN 解决的核心问题和工作机制:
- PN 的核心用途:实现“局部待机”
- PN 允许将整车的 ECU 划分为多个逻辑上的 PNC (Partial Network Cluster,局部网络簇)。
- 传统模式(全网唤醒):你只是想在车里听个歌,结果发动机控制单元(ECU)、雷达控制单元、座椅控制单元全都得通电待命,即使它们根本不干活。
- PN 模式(局部唤醒):你听歌时,只有娱乐系统相关的几个 ECU 保持活跃,其他不相关的 ECU(如底盘、动力系统)继续在“深度休眠”中省电。
- PN 允许将整车的 ECU 划分为多个逻辑上的 PNC (Partial Network Cluster,局部网络簇)。
- PN 是如何工作的?(报文过滤机制)
- PN 的实现依赖于一种特殊的硬件(支持 PN 的 CAN 收发器)和软件(CanNm 过滤算法)。
- PNC 位向量 (Bit Vector):在 NM 报文(网络管理报文)中,有一段专门的位域,每一位代表一个 PNC。
- 掩码匹配 (Filter Mask):每个 ECU 内部都存有一个“掩码”,记录了自己属于哪几个 PNC。
- 精准判断:当一个 ECU 收到 NM 报文时,它会对比报文里的位向量。
- 如果报文里请求的 PNC 与自己无关 $\rightarrow$ 忽略报文,继续睡觉。
- 如果报文里请求的位正好命中了自己 $\rightarrow$ 重置计时器,保持唤醒。
- PN 的实现依赖于一种特殊的硬件(支持 PN 的 CAN 收发器)和软件(CanNm 过滤算法)。
- PN 的关键优势
- 降低静态电流(Quiescent Current):对于新能源汽车(EV)尤为重要。在充电或远程空调预热时,只需唤醒少量 ECU,能显著延长电池续航。
- 减少总线负载:不活跃的节点不发报文,总线带宽利用率更高。
- 符合环保标准:有助于汽车厂商满足日益严苛的碳排放和能效限制。
RX处理
当 CanNm 接收到一条 NM PDU 时,它会根据配置和报文控制位(CBV)进入不同的处理分支:
-
当 PN 功能禁用时
如果
CanNmPnEnabled为 FALSE,不做任何过滤。所有的 NM PDU 都会按常规流程处理(重启超时计时器)。 -
当 PN 功能启用时
- PNI (Partial Network Information) 位为 0 表示该报文不包含特定的 PNC 激活信息。
- Case A: 如果
CanNmAllNmMessagesKeepAwake为 TRUE(通常用于网关),报文被接受,节点保持唤醒。 - Case B: 如果该参数为 FALSE,报文被丢弃。节点不会因为这条报文而重启计时器。
- Case A: 如果
- PNI (Partial Network Information) 位为 1是 PN 逻辑的核心。CanNm 会提取 PNC Bit Vector(位向量)并交给上层(Nm 模块)进行过滤匹配。
- 转发逻辑:CanNm 根据偏移量提取位向量,调用
Nm_PncBitVectorRxIndication。 - 处理条件:只有满足以下之一,报文才会被进一步处理(即维持唤醒):
CanNmAllNmMessagesKeepAwake为 TRUE。- CanSM 尚未确认 PN 的可用性(初始化阶段为了安全,默认全部接受)。
- 关键点:
RelevantPncRequestDetectedPtr返回 TRUE。这意味着报文中请求的某个 PNC 正好是本 ECU 感兴趣的。
- 转发逻辑:CanNm 根据偏移量提取位向量,调用
- PNI (Partial Network Information) 位为 0 表示该报文不包含特定的 PNC 激活信息。
🛑 同步 PNC 关闭 (Synchronized PNC Shutdown) 逻辑:这是针对更高级场景(如网关协调关闭)的保护机制:
-
非法请求处理
如果一个**主动协调器(Active Coordinator)**收到了带有
PNSR(Shutdown Request)位的报文,这是逻辑冲突的。- 动作:忽略该报文,向 DET 报运行时错误。
- 反应:如果开启了错误反应机制,它会立即发送一条包含当前正确 PN 信息的报文来“纠正”总线状态。
-
合法转发
当 PNI=1 且 PNSR=1 时,CanNm 提取位向量并通过
Nm_ForwardSynchronizedPncShutdown转发。这确保了关闭指令能跨拓扑传递,实现整个网络簇的同时休眠。
📊 报文布局示例解析
规范中提供了一个清晰的 8 字节 PDU 示例,展示了数据是如何挤在一起的:
| 字节 (Byte) | 字段名称 | 示例值 | 含义 |
|---|---|---|---|
| 0 | CBV | 0x40 |
二进制 0100 0000:PNI=1, PNSR=0。表示包含 PN 信息。 |
| 1 | NID | 0x00 |
发送节点 ID。 |
| 2 - 3 | User Data | 0xFF |
填充的用户数据。 |
| 4 | PNC Vector Data1 | 0x12 |
PNC 位向量。用于匹配过滤掩码(Filter Mask)。 |
| 5 | PNC Vector Data2 | 0x8E |
二进制数据为0001 0010,那么PNC ID就对应1和4(bit1和bit4为1) |
| 6 | PNC Vector Data3 | 0x80 |
二进制数据为1000 1110,那么PNC ID对应9, 10, 11, 15 。这里需要注意的是,位是从第8bit开始的,所以PNC id是从8开始 |
| 7 | PNC Vector Data4 | 0x01 |
以此类推 |
Tx的处理
CanNm 发送报文时 PN(部分网络)标志位的设置,以及一个非常关键的机制:同步 PNC 关闭(Synchronized PNC Shutdown)。其核心目标是:当某个功能(PNC)不再需要时,通知全网相关 ECU 同时关闭该功能,以达到最高效的省电效果。
-
PN 标志位的基本设置
在 NM 报文的 CBV(控制位向量) 中,有一个 PNI (Partial Network Information) 位:
- 启用 PN 时:发送的报文中 PNI 位必须设为 1。
- 禁用 PN 时:发送的报文中 PNI 位必须设为 0。
-
正常发送流
当需要发送一条普通的 NM 报文(非关闭请求)时,CanNm 遵循以下精密顺序:
- 获取状态:调用
Nm_PncBitVectorTxIndication获取本地当前哪些 PNC 是活跃的。 - 组装向量:将获取到的 PNC 状态填入报文的 PNC Bit Vector 区域。
- 合并用户数据:如果开启了用户数据,从 COM 或内部缓存抓取数据填入。
- 执行发送:调用
CanIf_Transmit发射报文。
- 获取状态:调用
-
同步 PNC 关闭机制 (Synchronized PNC Shutdown)
这是该规范最复杂也最重要的部分。当网关或主节点决定关闭某个 PNC 时,它不能只是自己闭嘴,必须发一个“撤退命令”。
触发与存储
上层调用 CanNm_RequestSynchronizedPncShutdown。CanNm 会把这个关闭请求存起来,等待在 MainFunction 中异步处理。
构造关闭报文 (PNSR Bit)
关闭报文与普通报文的不同点:
- PNSR 位 = 1:在 CBV 中将“PN 关闭请求位”置 1。
- 精准位图:将需要关闭的
PncId转换成位图。例如PncId 10对应byteIndex = 1(10/8),bitIndex = 2(10%8)。 - 覆盖写入:在此报文中,只有请求关闭的 PNC 位设为 1,其他设为 0。
重传与错误处理
由于关闭指令至关重要,CanNm 引入了重传计时器:
- 重传启动:第一次发关闭报文时,启动
CanNmPnShutdownMessageRetransmissionDuration计时器。 - 确认机制:
- 收到 E_OK:任务完成,清除存储的关闭请求,停止重传计时器。
- 收到 E_NOT_OK 或发送失败:如果在重传周期内,下个周期立刻重试。
- 超时失败:如果计时器到期还没发成功,上报 DET 错误
CANNM_E_TRANSMISSION_OF_PN_SHUTDOWN_MESSAGE_FAILED。
冲突预防
如果一个 PNC 正准备关闭,但此时突然:
- 外部唤醒:收到了别人发来的该 PNC 激活报文。
- 内部请求:本地应用突然又需要这个 PNC 了。
- 动作:CanNm 必须立刻从“待关闭列表”中移除该 PNC,取消关闭行动。
📊普通 NM 报文 vs PN 关闭报文
| 特性 | 普通 NM PDU | PN 关闭 (Shutdown) PDU |
|---|---|---|
| CBV PNI 位 | 1 | 1 |
| CBV PNSR 位 | 0 | 1 |
| PNC 位向量内容 | 当前所有活跃的 PNC | 仅包含请求关闭的 PNC |
| 优先级 | 正常周期 | 高优先级(可能推迟普通报文) |
| 重传机制 | 依赖下个周期 | 专门的重传计时器快速重试 |
CanSm
[!tip]
CanSM和上一章介绍的CanNm是两兄弟,都是基于interface层,对上则服务于ComM服务。只不过两兄弟所实现的功能不一样,在具体介绍CanSM模块之前,得先搞清楚状态管理是个什么玩意。首先这里管理的状态其实是对应其总线的通信状态,所以CanSM模块管理的就是CAN总线的通信状态,而这里的通信状态则包含能不能发送报文,能不能接收报文,总线上有没有错误等。CanSM提供的主要功能主要有:
- 总线模式切换
- Busoff 恢复管理
- 切换波特率
- 唤醒确认管理
模块交互
CanSM模块针对CAN总线状态而言,由上而下,CanSM接收其他模块的总线状态切换请求并通知CanIf模块去执行,由下而上,CanSM接收CanIf模块的总线状态切换反馈并汇报给其他模块。下图显示了在AUTOSAR的BSW层中其他模块与CanSM的交互情况:
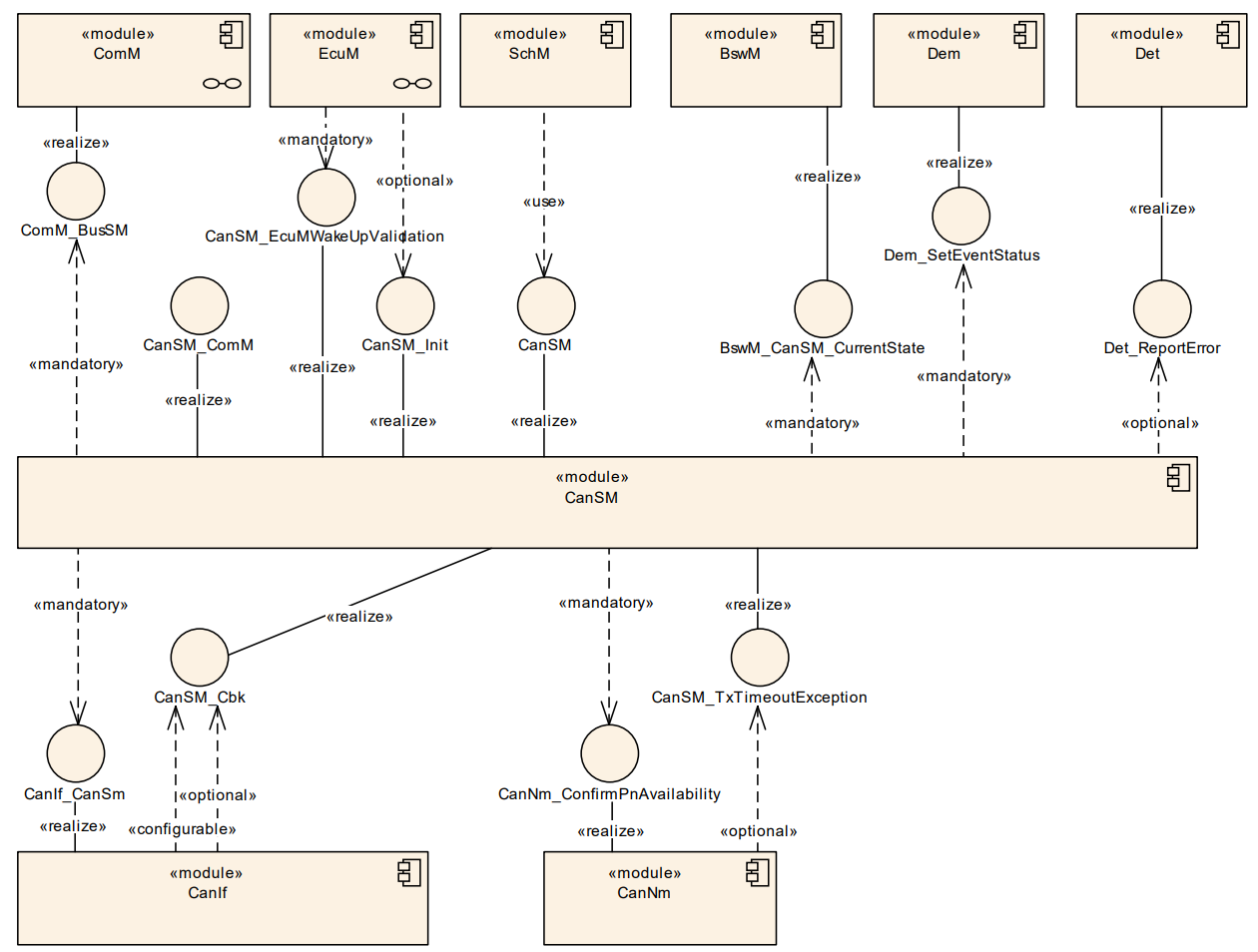
- ECuM模块会初始化CanSM模块,并与CanSM模块交互进行CAN总线唤醒的验证。
- ComM模块使用CanSM模块请求CAN网络的通信模式,CanSM模块会将其CAN网络的当前通信模式通知给ComM模块。
- CanSM模块使用Canlf模块来控制CAN控制器和CAN收发器工作模式,Canlf模块通知CanSM模块CAN总线相关事件。
- CanSM模块向Dem模块报告总线特定的故障信息。
- CanSM将总线特定的模式更新通知到BswM模块。
- CanSM模块将部分网络可用性通知给CanNm模块,并在部分联网的情况下处理已通知的CanNm超时异常。
- CanSM模块向Det模块报告开发和运行时错误。
通信模式
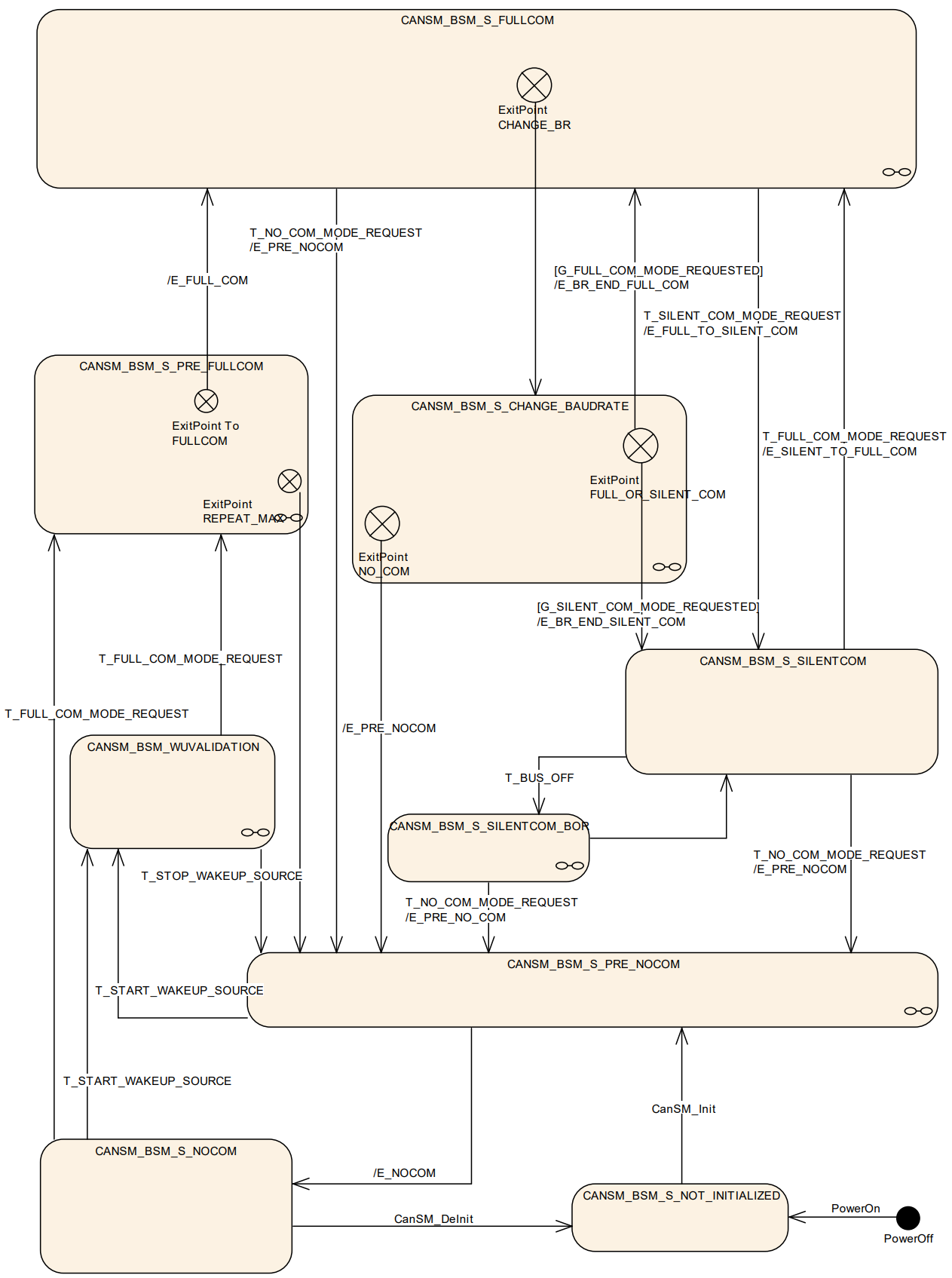
在CAN通信(基于AUTOSAR架构)中,有三种通信模式:
- 完全通信模式(FULL_COMMUNICATION):节点正常收发数据,参与总线通信(如ECU运行时)。
- 控制器:
CANIF_CS_STARTED(启动状态,处理协议层)。 - 收发器:
TRCVMODE_NORMAL(主动驱动差分信号)。
- 控制器:
- 静默通信模式(SILENT_COMMUNICATION):节点仅接收数据,不发送数据,避免干扰总线(如诊断监听)。
- 控制器:
CANIF_TX_OFFLINE(发送关闭,仅接收)。 - 收发器:仍保持
TRCVMODE_NORMAL(需接收物理层信号)。
- 控制器:
- 无通信模式(NO_COMMUNICATION): 节点完全离线,进入低功耗状态(如车辆熄火后)。
- 控制器:
CANIF_CS_STOPPED(协议层停止运行)。 - 收发器:
TRCVMODE_STANDBY(待机模式,仅保留唤醒能力)。
- 控制器:
模式切换逻辑为:
- 唤醒事件(如总线活动):
NO_COMMUNICATION→ 唤醒 →FULL_COMMUNICATION。 - 诊断需求:
FULL_COMMUNICATION→ 静默 →SILENT_COMMUNICATION。 - 休眠指令:
FULL_COMMUNICATION→ 关闭 →NO_COMMUNICATION。
[!tip]
在上面的状态机中实际上还有其他的状态,对于通信模式而言只有三种稳定状态,其余都是中间状态。
- NOT_INITIALIZED 状态下,只能调用 CanSM_Init。
- PRENOCOM/WUVALIDATION/PRE_FULLCOM/CHANGE_BAUDRATE/SILENTCOM_BOR 为中间状态,正常情况下,CanSM不会停留在这些状态中,在这些状态下,调用 CanSM_RequestComMode 会被拒绝。
- NOCOM\FULLCOM\SILENTCOM 为稳定状态,处于这些状态下,可接受新的CanSM_RequestComMode 请求。
[!Note]
在以上状态机图中,不同的前缀条件代表不同的条件:
- T: Trigger
- G: Guarding condition
- E: Effect
在图中详细描述了 CanSM 模块的状态机触发条件(Trigger)、判定条件(Guard)以及产生的效应(Effect)。CanSM 通过这些机制在 ComM(通信管理器)和 CanIf(CAN 接口)之间起到承上启下的作用。
- 状态机触发条件 (Triggers):状态机的跳转由外部 API 调用或底层回调触发:
- 系统初始化与去初始化:
- PowerOn: 初始状态为
CANSM_BSM_NOT_INITIALIZED。 - CanSM_Init: 触发所有配置网络的初始化流程。
- CanSM_DeInit: 触发去初始化,前提是网络已处于
NO_COMMUNICATION。
- PowerOn: 初始状态为
- 唤醒源控制:
- T_START_WAKEUP_SOURCE: 由
CanSM_StartWakeUpSource成功返回后触发。 - T_STOP_WAKEUP_SOURCE: 由
CanSM_StopWakeUpSource成功返回后触发。
- T_START_WAKEUP_SOURCE: 由
- 模式请求 (来自 ComM):
- T_FULL_COM_MODE_REQUEST: 请求进入全通信模式。
- T_SILENT_COM_MODE_REQUEST: 请求进入静默模式(通常用于准备进入总线睡眠)。
- T_NO_COM_MODE_REQUEST: 请求关闭通信。
- 异常监控:
- T_BUS_OFF: 底层检测到控制器 Bus-Off 时通过回调触发。
- 系统初始化与去初始化:
- 判定条件 (Guarding Conditions):在执行某些跳转前,状态机会检查最近一次被接受的模式请求:
- G_FULL_COM_MODE_REQUESTED: 检查最后一次请求是否为
COMM_FULL_COMMUNICATION。 - G_SILENT_COM_MODE_REQUESTED: 检查最后一次请求是否为
COMM_SILENT_COMMUNICATION。
- G_FULL_COM_MODE_REQUESTED: 检查最后一次请求是否为
- 执行效应 (Effects):当状态跳转发生时,CanSM 会通过一系列 API 调用来配置底层硬件并通知上层模块。
- 进入全通信模式 (E_FULL_COM):这是最复杂的效应,包含多个步骤:
- 设置 PDU 模式:
- 若 ECU Passive 为 FALSE:调用
CanIf_SetPduMode为CANIF_ONLINE。 - 若 ECU Passive 为 TRUE:设置为
CANIF_TX_OFFLINE_ACTIVE。
- 若 ECU Passive 为 FALSE:调用
- 通知 ComM:调用
ComM_BusSM_ModeIndication指示COMM_FULL_COMMUNICATION。 - 通知 BswM:调用
BswM_CanSM_CurrentState指示CANSM_BSWM_FULL_COMMUNICATION。
- 设置 PDU 模式:
- 进入静默模式 (E_FULL_TO_SILENT_COM):执行步骤如下:
- 通知 BswM:设置为
CANSM_BSWM_SILENT_COMMUNICATION。 - 设置 PDU 模式:调用
CanIf_SetPduMode为CANIF_TX_OFFLINE。 - 通知 ComM:指示
COMM_SILENT_COMMUNICATION。
- 通知 BswM:设置为
- 关闭通信流程 (E_PRE_NOCOM & E_NOCOM)
- E_PRE_NOCOM: 预关闭阶段,通知 BswM 状态为
CANSM_BSWM_NO_COMMUNICATION。 - E_NOCOM:
- 更新内部存储的模式为
COMM_NO_COMMUNICATION。 - 若请求确实是关闭通信,则向 ComM 发送最终的模式指示。
- 更新内部存储的模式为
- E_PRE_NOCOM: 预关闭阶段,通知 BswM 状态为
- 进入全通信模式 (E_FULL_COM):这是最复杂的效应,包含多个步骤:
📝 效应汇总表
| 效应名称 | 目标通信模式 | 主要动作 |
|---|---|---|
| E_FULL_COM | Full Com | 开启 PDU 传输(Online),通知 ComM/BswM。 |
| E_FULL_TO_SILENT_COM | Silent Com | 禁用发送(TX_Offline),通知 ComM/BswM。 |
| E_NOCOM | No Com | 更新内部状态,通知 ComM。 |
子状态机
[!note]
如果观察下面的所有状态机,就会发现,在设置控制器模式之前都需要将先设置为Stop模式,将收发器设置为Nomal模式。这是因为控制器可能在上电后默认处于未初始化状态,需先复位到“停止模式”作为启动前的统一基准状态。同理,收发器状态也需要做基准。
CANSM_BSM_WUVALIDATION
以下是唤醒校验的状态机图:
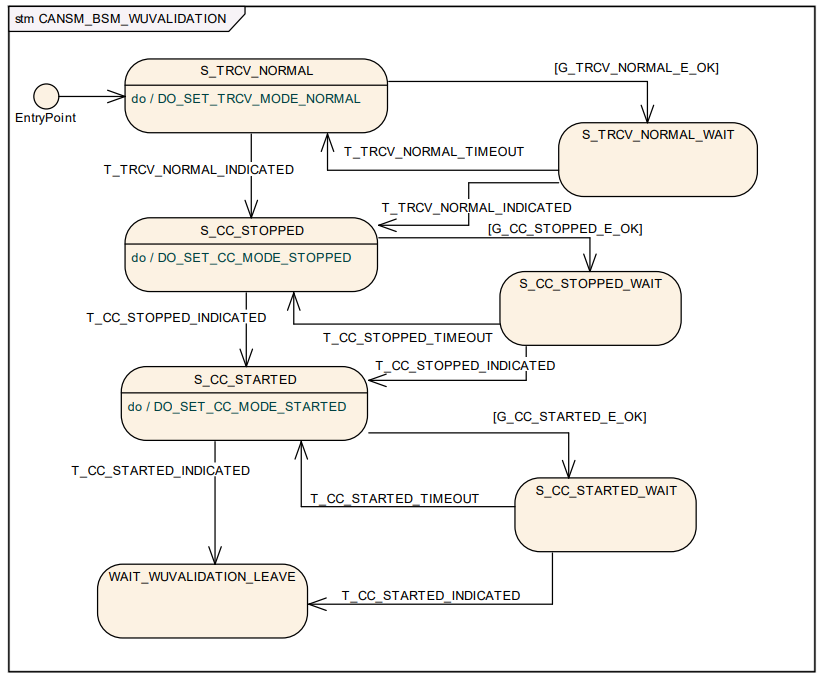
该状态机确保在进入全通信模式之前,CAN 收发器(Transceiver)和控制器(Controller)能够正确、安全地切换到目标工作状态。
-
收发器状态操作:S_TRCV_NORMAL
当状态机处于收发器模式设置阶段时,必须确保硬件已准备就绪。
- 状态行为 (DO Action):只要处于
S_TRCV_NORMAL状态,CanSM 就必须重复调用CanIf_SetTrcvMode,请求将收发器模式设置为CANTRCV_TRCVMODE_NORMAL。 - 判定条件:只有当
CanIf_SetTrcvMode返回E_OK时,判定条件G_TRCV_NORMAL_E_OK才算通过。 - 成功触发:当 CanSM 收到底层确认回调(模式指示),证明收发器已成功进入 Normal 模式,触发
T_TRCV_NORMAL_INDICATED进行状态跳转。 - 超时触发:如果等待指示的时间超过了配置的
CANSM_MODEREQ_REPEAT_TIME,则触发T_TRCV_NORMAL_TIMEOUT。
- 状态行为 (DO Action):只要处于
-
控制器停止操作:S_CC_STOPPED
在某些唤醒或重置流程中,需要先将控制器置于停止状态。
- 状态行为:如果当前控制器模式不是
CAN_CS_STOPPED,CanSM 必须持续请求CanIf_SetControllerMode为停止模式。 - 判定条件:所有配置的控制器请求都返回
E_OK后,G_CC_STOPPED_OK判定通过。 - 成功与超时:
- 收到所有控制器的停止模式指示后,触发
T_CC_STOPPED_INDICATED。 - 若在
CANSM_MODEREQ_REPEAT_TIME时间内未完成,触发T_CC_STOPPED_TIMEOUT。
- 收到所有控制器的停止模式指示后,触发
- 状态行为:如果当前控制器模式不是
-
控制器启动操作:S_CC_STARTED
这是唤醒校验的关键步骤,确保控制器能够正常启动。
- 状态行为:CanSM 重复调用
CanIf_SetControllerMode,请求将模式设置为CAN_CS_STARTED。 - 判定条件:所有启动请求返回
E_OK后,G_CC_STARTED_E_OK判定通过。 - 跳转逻辑:
- 成功指示:所有控制器均反馈已启动,触发
T_CC_STARTED_INDICATED。 - 超时反馈:超时未启动则触发
T_CC_STARTED_TIMEOUT。
- 成功指示:所有控制器均反馈已启动,触发
- 状态行为:CanSM 重复调用
💡唤醒校验的核心机制:请求-确认-重试
CanSM 在管理底层硬件时遵循一个严密的闭环逻辑:
- Do Action: 持续发起请求(Do Action),直到获得 API 的
E_OK。 - Wait for Indication: 等待异步回调(Indication)来确认硬件实际状态已切换。
- Timeout Guard: 使用统一的重复间隔时间
CANSM_MODEREQ_REPEAT_TIME监控每一个阶段,防止因硬件故障导致状态机死锁。
所以收发器的变化过程为:Normal->Stop->start
CANSM_BSM_S_PRE_NOCOM
以下是预备无通信状态的状态机:
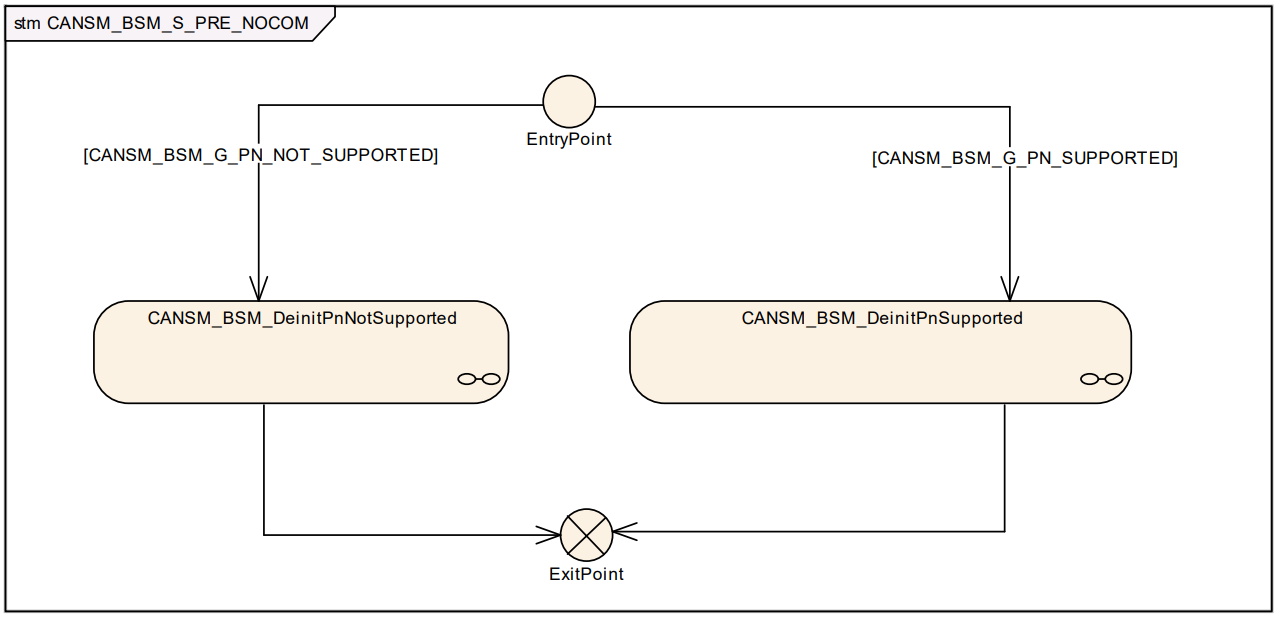
首先根据硬件配置判断是否支持 PN(部分网络)。这是因为支持 PN 的收发器在休眠前需要额外的操作(如清除唤醒标志)。
-
判定条件:不支持 PN (
G_PN_NOT_SUPPORTED)当满足以下任一条件时,状态机认为该网络不支持 PN 功能:
-
未配置收发器:在配置参数
CanSMTransceiverId中没有关联任何 CAN 收发器。 -
收发器未开启 PN:虽然配置了收发器,但其对应的硬件配置参数
CanTrcvPnEnabled被设置为FALSE。
后果:状态机将跳过所有与 PN 相关的子状态(如清除 WUF 标志),直接执行常规的控制器停止和收发器进入 Standby 的流程。
-
-
判定条件:支持 PN (
G_PN_SUPPORTED)只有同时满足以下两个条件,状态机才会进入 PN 处理流程:
-
已配置收发器:
CanSMTransceiverId引用了一个有效的收发器。 -
收发器开启 PN:该收发器的
CanTrcvPnEnabled参数设置为TRUE。
后果:状态机会进入更复杂的子状态机(通常涉及
S_PN_CLEAR_WUF等状态),确保在收发器进入睡眠模式前,硬件的唤醒帧过滤器已正确重置。 -
在这个状态机中,对于支持PN功能的程度不同走了两个不同的分支,但是实际上控制器和收发器的最终状态是一致的,改变过程为:
- 设置CAN控制器为Stopped状态,CanIf_SetControllerMode(CAN_CC_STOPPED)
- 设置CAN控制器为Sleep状态,CanIf_SetControllerMode(CAN_CC_SLEEP)
- 设置CAN收发器为Normal状态,CanIf_SetTrcvMode(CANTRCV_TRCVMODE_NORMAL)
- 设置CAN收发器为Standy状态,CanIf_SetTrcvMode(CANTRCV_TRCVMODE_STANDBY)
所以最终的收发器状态为Standy,控制器状态为Sleep。
其中CANSM_BSM_DeInitPnSupported状态机为:
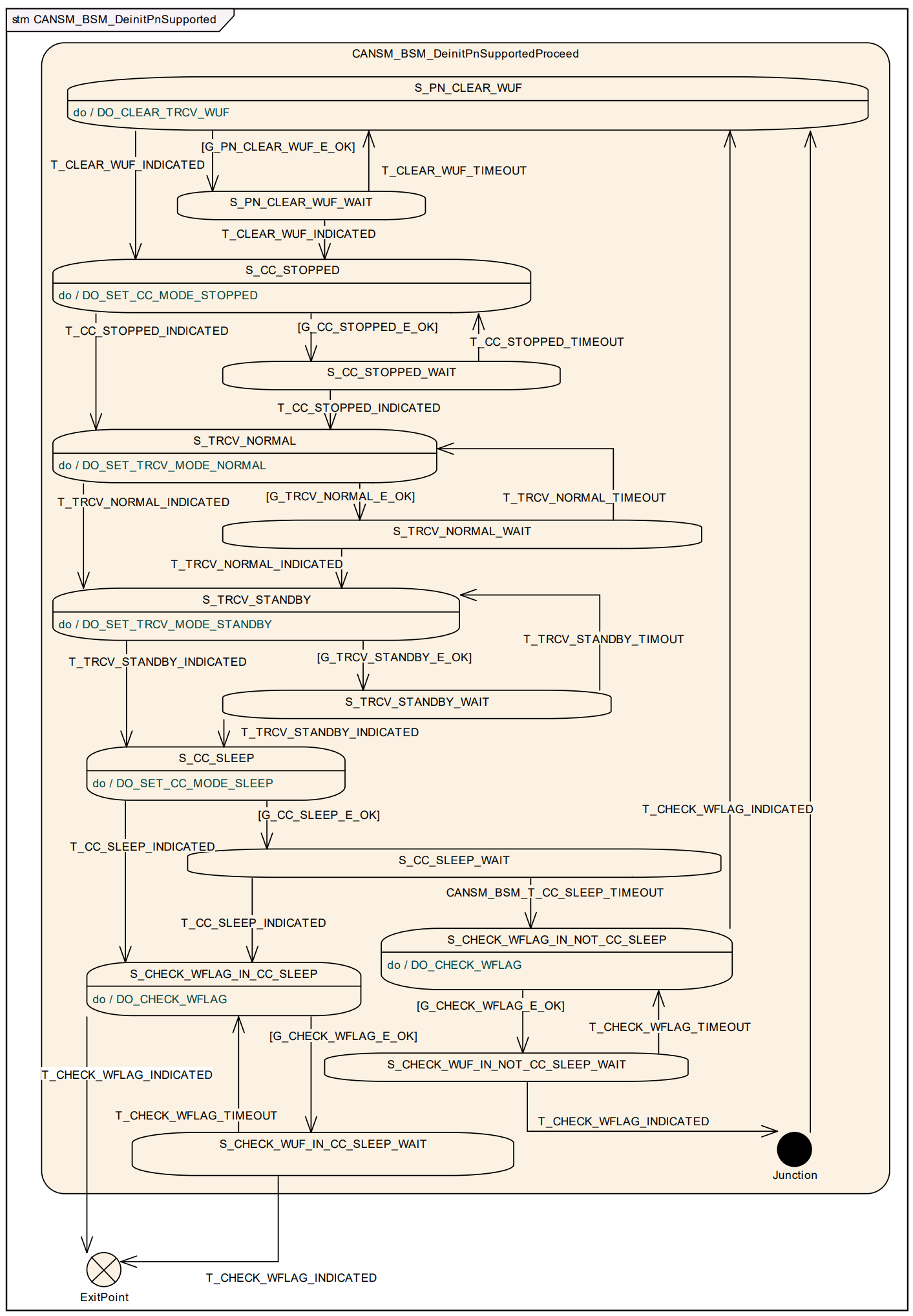
其核心逻辑仍然遵循 “执行 DO Action -> 检查 Guard -> 等待 Indication -> 超时重试” 的闭环模式。
在支持 PN 的路径下,关机序列比普通路径多出了“清除唤醒标志”和“检查唤醒标志”的关键步骤:
-
第一阶段:清除唤醒标志 (WUF)
- S_PN_CLEAR_WUF: CanSM 持续调用
CanIf_ClrTrcvWufFlag。 - 跳转条件: 当 API 返回
E_OK且收到CanSM_ClearTrcvWufFlagIndication回调时,触发T_CLEAR_WUF_INDICATED进入下一阶段。
- S_PN_CLEAR_WUF: CanSM 持续调用
-
第二阶段:硬件状态同步(停止与 Normal 化)
- S_CC_STOPPED: 将所有控制器设置为
CAN_CS_STOPPED。 - S_TRCV_NORMAL: 将收发器暂时切回
NORMAL模式(这是为了确保后续能正确检测唤醒标志)。
- S_CC_STOPPED: 将所有控制器设置为
-
第三阶段:进入深度休眠
- S_TRCV_STANDBY: 将收发器置于
STANDBY模式。 - S_CC_SLEEP: 将所有控制器设置为
CAN_CS_SLEEP模式。
- S_TRCV_STANDBY: 将收发器置于
-
第四阶段:最终唤醒标志检查
S_CHECK_WFLAG_…: 在控制器处于休眠或非休眠状态下,再次调用
CanIf_CheckTrcvWakeFlag以确认没有挂起的唤醒请求。
执行 DO Action 后,状态机的流转规律如下:
| 当前执行的 DO Action | 成功跳转条件 (Next State) | 超时处理 (Retry) |
|---|---|---|
| DO_CLEAR_TRCV_WUF | 收到 ClearWuf 指示 |
重复执行直到成功或达到 RepetitionMax |
| DO_SET_CC_MODE_STOPPED | 收到所有控制器 STOPPED 指示 |
触发 T_CC_STOPPED_TIMEOUT 重新尝试 |
| DO_SET_TRCV_STANDBY | 收到收发器 STANDBY 指示 |
触发 T_TRCV_STANDBY_TIMEOUT 重新尝试 |
| DO_CHECK_WFLAG | 收到 CheckWakeFlag 指示 |
触发 T_CHECK_WFLAG_TIMEOUT |
超时机制与状态机退出
- 内部重试: 每个子状态都有对应的
T_..._TIMEOUT。如果硬件在CANSM_MODEREQ_REPEAT_TIME时间内没有给出 Indication 回调,状态机会跳回该子状态的入口,重新执行 DO Action。 - 最终退出: 只有当整个
DeinitPnSupported链条上的所有 Indication 全部按序到齐,状态机才会从该子状态机“出去”,回到主状态机并最终进入CANSM_BSM_S_NOCOM。
CANSM_BSM_DeInitPnNotSupported的状态机为:
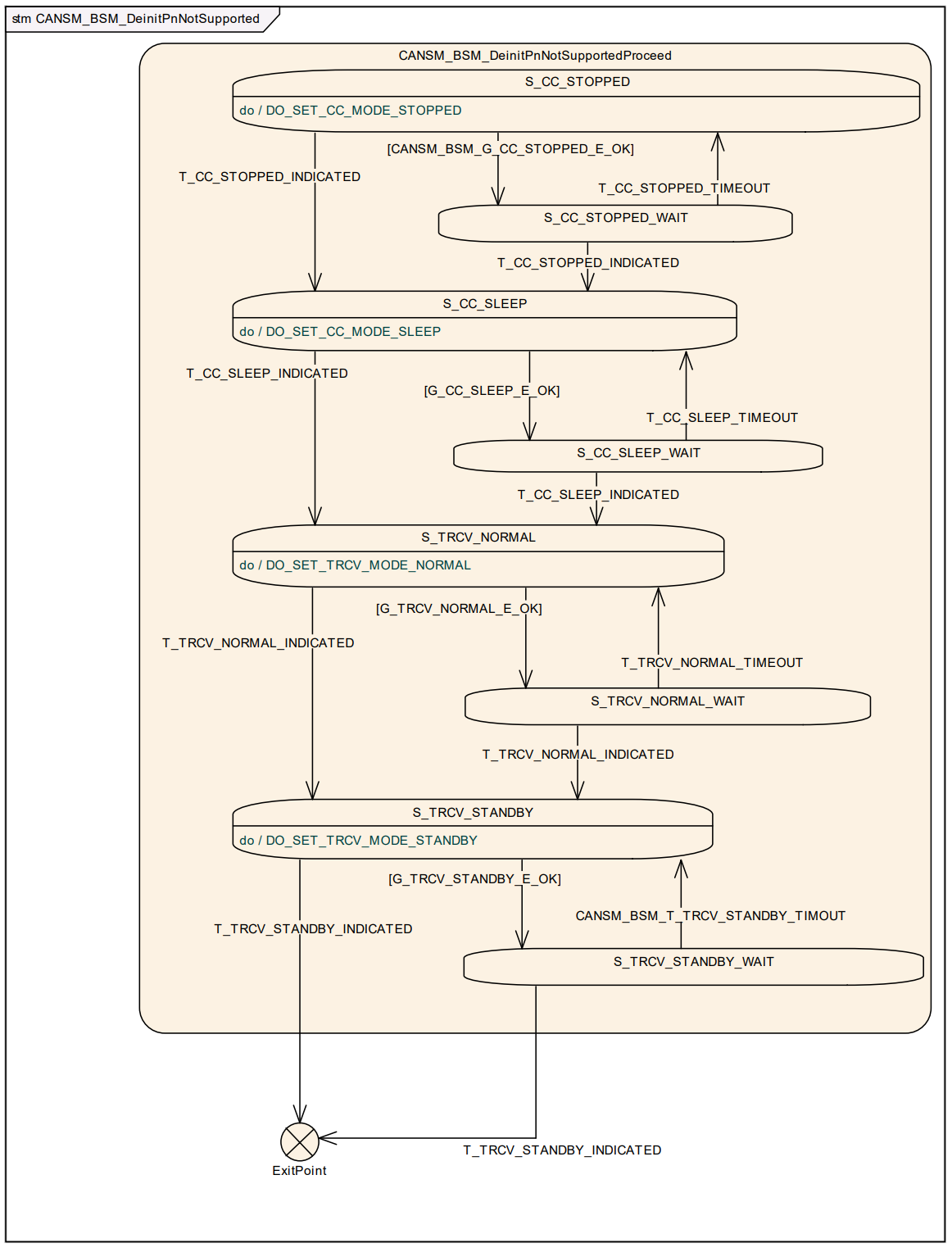
在不支持部分网络(PN)的情况下,CANSM_BSM_DeinitPnNotSupported 子状态机负责执行简化的关机序列。与 PN 路径类似,它遵循 “发起请求(DO Action) -> 确认成功(Guard OK) -> 等待硬件反馈(Indication)” 的闭环控制逻辑。
关机序列该子状态机通过以下四个核心阶段,将 CAN 控制器和收发器逐步置于休眠状态:
- 第一阶段:控制器停止 (S_CC_STOPPED)
- 动作:如果当前模式不是
STOPPED,CanSM 会持续调用CanIf_SetControllerMode将控制器设为停止状态。 - 跳转:API 返回
E_OK后进入等待,收到所有控制器的模式确认回调(Indication)后触发T_CC_STOPPED_INDICATED。
- 动作:如果当前模式不是
- 第二阶段:收发器 Normal 化 (S_TRCV_NORMAL)
- 动作:将收发器设为
NORMAL模式。 - 特殊逻辑:如果没有配置收发器,状态机会直接触发
T_TRCV_NORMAL_INDICATED跳过此步。
- 动作:将收发器设为
- 第三阶段:收发器待机 (S_TRCV_STANDBY)
- 动作:将收发器设为
STANDBY模式。 - 特殊逻辑:若无收发器配置,直接触发
T_TRCV_STANDBY_INDICATED跳转。
- 动作:将收发器设为
- 第四阶段:控制器休眠 (S_CC_SLEEP)
- 动作:最后将所有控制器设置为
CAN_CS_SLEEP模式。 - 完成:收到所有休眠确认指示后,触发
T_CC_SLEEP_INDICATED。
- 动作:最后将所有控制器设置为
执行 DO Action 后,在子状态机内部,执行完 DO Action 后的流转严格受 Guard 和 Trigger 控制:
| 当前状态 | 执行的 DO Action | 跳转至 WAIT 或下一状态的条件 | 超时处理 (Retry) |
|---|---|---|---|
| S_CC_STOPPED | DO_SET_CC_MODE_STOPPED |
所有调用返回 E_OK 且收到 T_CC_STOPPED_INDICATED |
触发 T_CC_STOPPED_TIMEOUT 重新执行 |
| S_TRCV_NORMAL | DO_SET_TRCV_MODE_NORMAL |
调用返回 E_OK 且收到 T_TRCV_NORMAL_INDICATED |
触发 T_TRCV_NORMAL_TIMEOUT 重新执行 |
| S_TRCV_STANDBY | DO_SET_TRCV_MODE_STANDBY |
调用返回 E_OK 且收到 T_TRCV_STANDBY_INDICATED |
触发 T_TRCV_STANDBY_TIMEOUT 重新执行 |
| S_CC_SLEEP | DO_SET_CC_MODE_SLEEP |
所有调用返回 E_OK 且收到 T_CC_SLEEP_INDICATED |
触发 T_CC_SLEEP_TIMEOUT 重新执行 |
与 PN 路径的主要区别为:
- 流程简化:去掉了清除和检查唤醒标志(WUF/WFLAG)的复杂步骤。
- 硬件兼容性:通过
SWS_CanSM_00556和SWS_CanSM_00557显式处理了没有收发器的情况,确保纯控制器环境下的逻辑闭环。
CANSM_BSM_S_SILENTCOM_BOR
在该状态机中,BOR表示Bus-Off Recovery(总线离线恢复),需要将Can设备重启(控制器为S_RESTART_CC状态)。同时应该调用Dem_SetEventStatus报告Bus Off事件。
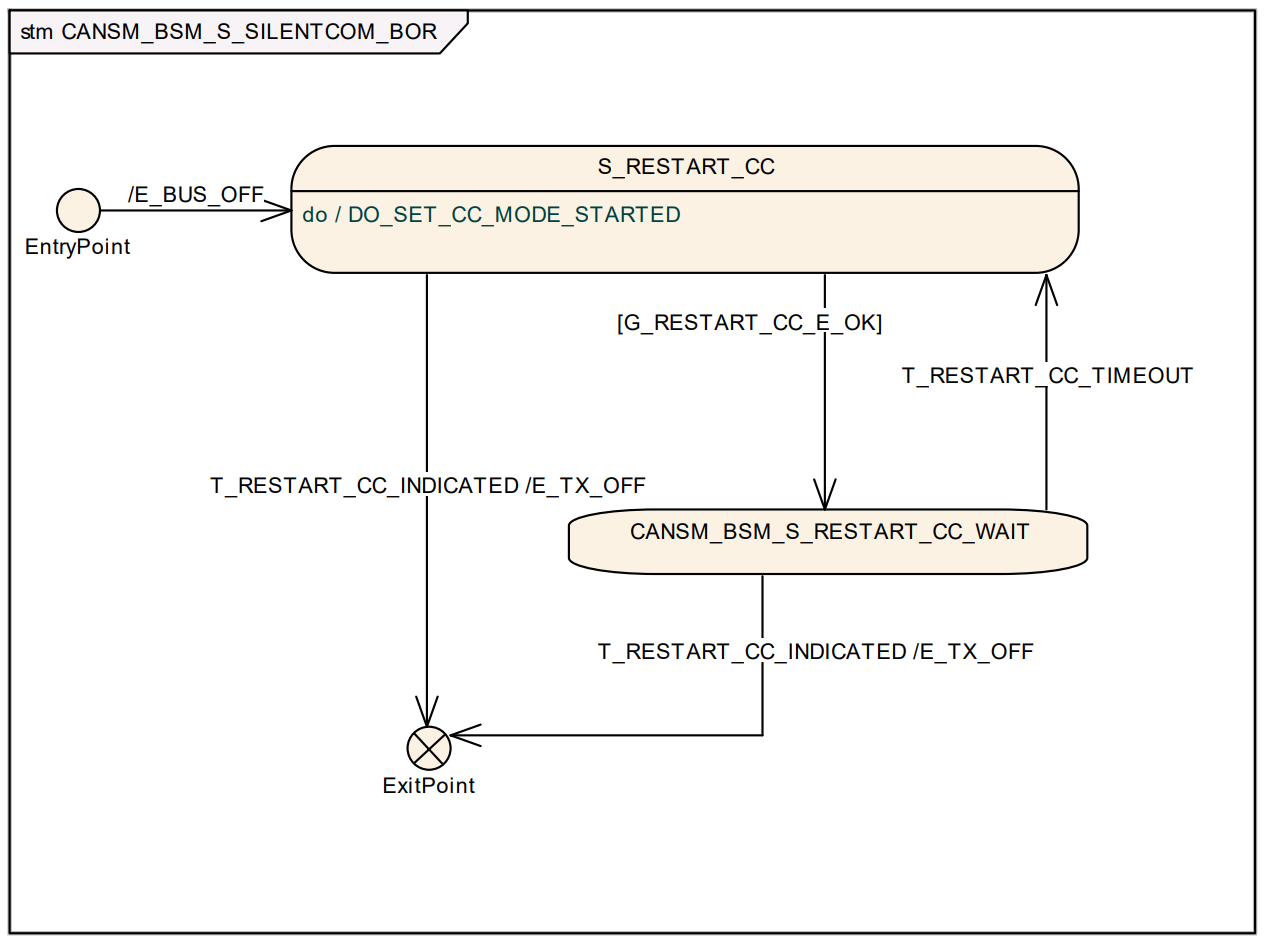
当 CAN 网络发生 Bus-Off 错误且处于 SILENTCOM(静默通信)模式时,状态机会进入 CANSM_BSM_S_SILENTCOM_BOR 子状态机进行恢复处理。
关于执行 DO Action 后的跳转逻辑及其效应,解析如下:
-
Bus-Off 初始效应:E_BUS_OFF
当检测到 Bus-Off 时,CanSM 首先会执行故障上报:
- 故障上报:调用
Dem_SetEventStatus将CANSM_E_BUS_OFF事件的状态设置为DEM_EVENT_STATUS_PRE_FAILED。
- 故障上报:调用
-
执行 DO Action:S_RESTART_CC (控制器重启)
在
SILENTCOM_BOR子状态机中,核心任务是将因 Bus-Off 停止的控制器重新启动:- 执行 DO Action:只要处于
S_RESTART_CC状态,CanSM 就会持续检查各控制器的状态。如果当前模式不是STARTED,则重复调用CanIf_SetControllerMode请求进入CAN_CS_STARTED。 - 跳转逻辑 (Guard):一旦所有的 API 请求都返回了
E_OK,判定条件G_RESTART_CC_OK就会通过,状态机进入**等待(WAIT)**环节。
- 执行 DO Action:只要处于
-
退出与重试机制
执行完重启请求后,状态机的下一步流转取决于硬件的反馈:
- 成功退出:当 CanSM 收到了所有配置控制器的模式指示回调(Indication)时,触发
T_RESTART_CC_INDICATED。这标志着控制器已成功恢复,子状态机完成使命并退出。 - 超时重试:如果在
CANSM_MODEREQ_REPEAT_TIME时间内未收到所有指示,则触发T_RESTART_CC_TIMEOUT。此时状态机会跳回S_RESTART_CC状态,重新开始执行 DO Action(即再次请求启动控制器)。
- 成功退出:当 CanSM 收到了所有配置控制器的模式指示回调(Indication)时,触发
-
特殊效应:E_TX_OFF
由于控制器在 Bus-Off 重启后的默认 PDU 模式已经是 TX OFF(符合
SILENTCOM要求的只听不发状态),因此该效应不执行任何操作。
在 SILENTCOM_BOR 流程中,执行完 DO Action 后的逻辑是:
- 不直接退出,而是跳转到内部的等待逻辑。
- 依赖反馈:只有硬件指示(Indication)到齐后才真正退出子状态机。
- 循环尝试:如果超时,它会不断循环执行 DO Action 尝试拉起控制器,直到硬件响应或达到全局的最大重试次数限制。
CANSM_BSM_S_PRE_FULLCOM
CANSM_BSM_S_PRE_FULLCOM(预备全通信状态),其中正常的状态转移为:
- 设置CAN收发器为Normal状态,CanIf_SetTrcvMode(CANTRCV_TRCVMODE_NORMAL)
- 设置CAN控制器为Stopped状态,CanIf_SetControllerMode(CAN_CS_STOPPED)
- 设置CAN控制器为Started状态,CanIf_SetControllerMode(CAN_CS_STARTED)
所以最终的收发器状态为Normal,控制器状态为Started。
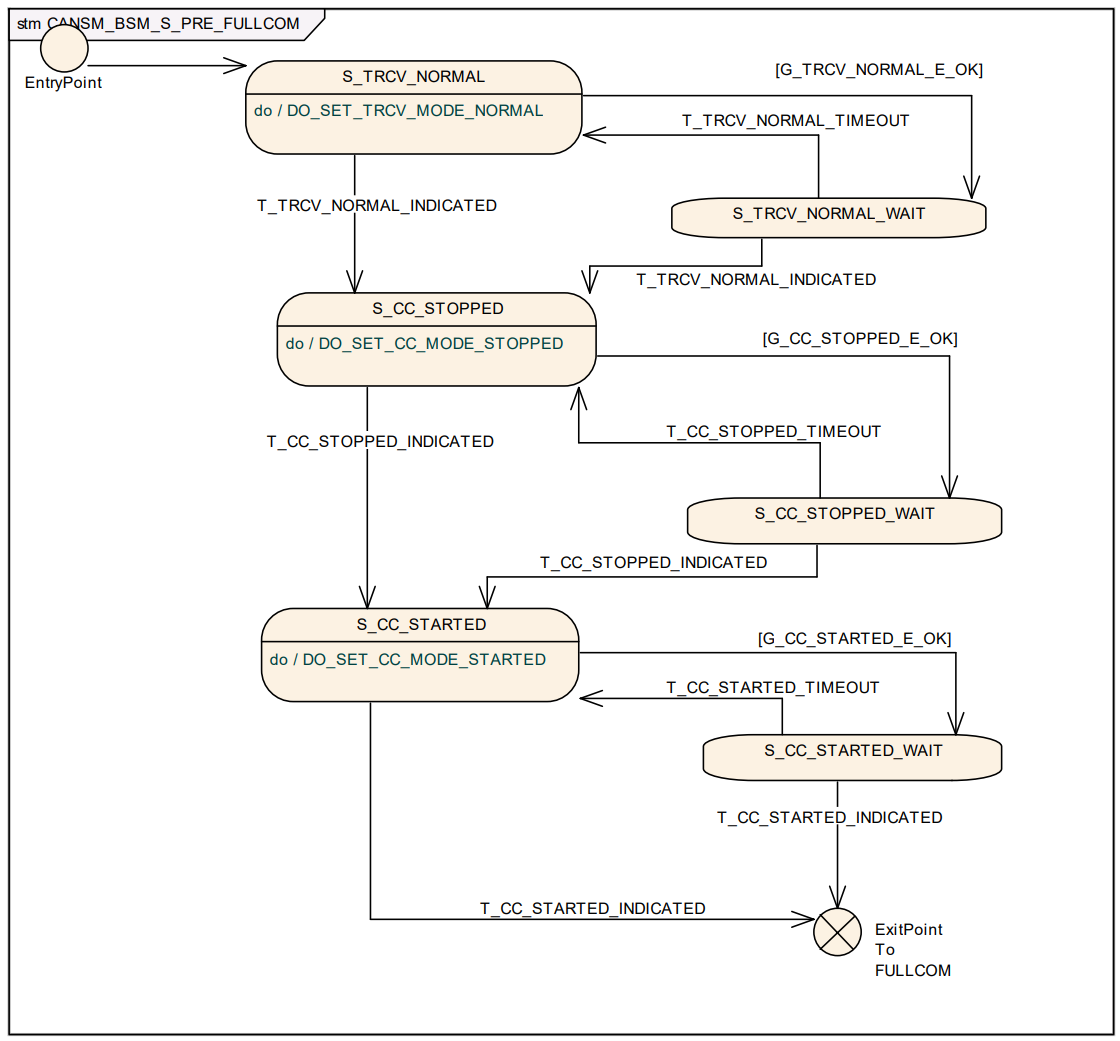
-
核心运行逻辑:请求与反馈
在
S_PRE_FULLCOM中,CanSM 的目标是确保硬件(收发器和控制器)在正式开启 PDU 传输前达到工作状态。- 执行 DO Action:只要处于对应的
S_...状态,CanSM 就会持续尝试发起模式请求(如CanIf_SetTrcvMode或CanIf_SetControllerMode)。 - Guard 判定:执行完 API 调用后,状态机会立即检查 Guard 条件。只有当 API 返回
E_OK时,才会认为“请求已成功发出”,并允许逻辑停留在该状态或进入等待环节。 - Indication 触发跳转:执行完 DO Action 且 API 返回成功后,状态机不会自动进入下一个功能阶段。它必须等待底层的异步回调通知(Indication)。一旦收到确认,相应的
T_..._INDICATED触发器才会将状态机推向序列的下一步。
- 执行 DO Action:只要处于对应的
-
状态机内部跳转序列
该子状态机按照以下顺序强制执行硬件初始化:
阶段 状态 (State) 执行的 DO Action 退出到下一阶段的条件 1. 收发器 S_TRCV_NORMALDO_SET_TRCV_MODE_NORMAL收到收发器 Normal 指示 2. 控制器停止 S_CC_STOPPEDDO_SET_CC_MODE_STOPPED收到所有控制器 Stopped 指示 3. 控制器启动 S_CC_STARTEDDO_SET_CC_MODE_STARTED收到所有控制器 Started 指示 -
超时与容错处理
- 循环重试:如果在等待 Indication 的过程中触发了
T_..._TIMEOUT(即超过了CANSM_MODEREQ_REPEAT_TIME),状态机会返回到当前阶段的起始点,重新执行 DO Action。 - 无硬件兼容性:如果没有配置收发器,
S_TRCV_NORMAL状态会直接模拟收到T_TRCV_NORMAL_INDICATED指示,从而直接跳转到控制器处理阶段。
- 循环重试:如果在等待 Indication 的过程中触发了
-
最终退出点
当最后的
T_CC_STARTED_INDICATED被触发后,该子状态机执行完毕。根据主状态机图(图 7-1),此时会产生效应
E_FULL_COM。这意味着 CanSM 此时才会调用CanIf_SetPduMode(CANIF_ONLINE)来真正允许报文在总线上发送,并最终向 ComM 模块发送模式指示。
CANSM_BSM_S_FULLCOM
该状态机的核心功能是在CAN通信正常激活后,监控总线状态(如总线离线、发送超时)、处理故障恢复(如Bus-Off恢复)以及支持波特率切换,确保CAN总线持续稳定通信。
- E_TX_OFF/ON:总线结果为TX_OFFLINE/TX_ONLINE
- G_BUS_OFF_PASSIVE:如果CANSM_BOR_TX_CONFIRMATION_POLLING禁能且E_TX_ON持续时间大于等于CANSM_BOR_TIME_TX_ENSURED;或如果CANSM_BOR_TX_CONFIRMATION_POLLING使能且API:CanIf_GetTxConfirmationState返回CANIF_TX_RX_NOTIFICATION则满足条件G_BUS_OFF_PASSIVE。
- T_SILENT_COM_MODE_REQUEST:CanSM_RequestComMode(COMM_SILENT_COMMUNICATION)
- T_BUS_OFF:如果回调函数CanSM_ControllerBusOff,则以T_BUS_OFF触发状态切换。
- T_RESTART_CC_INDICATED:在重启CAN控制器后,CanSM获得状态指示,则以T_RESTART_CC_INDICATED触发状态切换。
- G_TX_ON:如果参数CanSMEnableBusOffDelay是FALSE:当bus-off恢复次数小于CanSMBorCounterL1ToL2时,经过时间CanSMBorTimeL1;或当bus-off恢复次数大于等于CanSMBorCounterL1ToL2时,经过时间CanSMBorTimeL2则满足G_TX_ON。
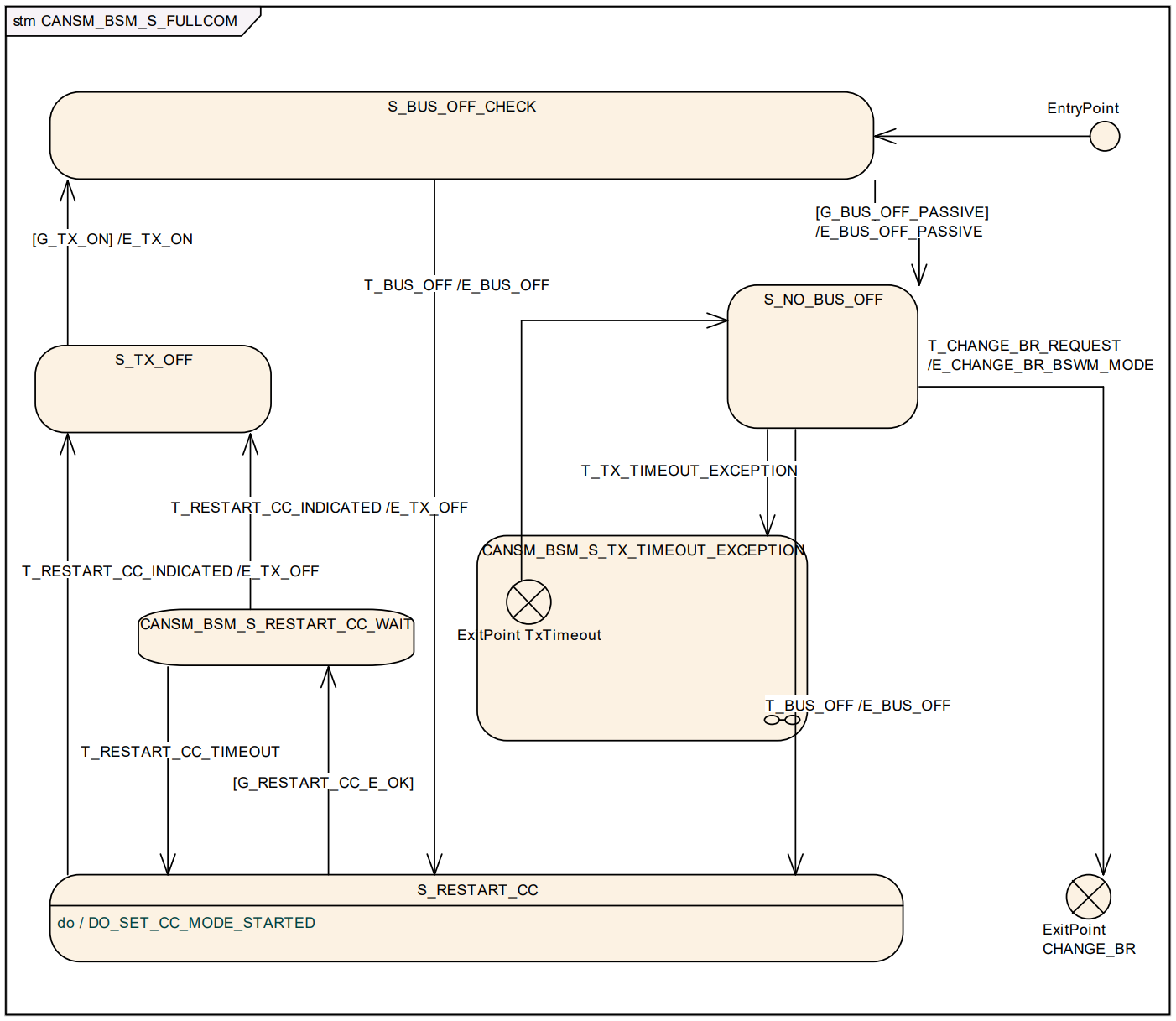
CanSM 通过分层恢复策略(L1 和 L2)来平衡网络的可用性与稳定性。
-
Bus-Off 恢复的分层策略 (L1 vs L2)
当 CAN 控制器发生 Bus-Off 时,CanSM 不会盲目重启,而是根据重试次数采用不同的等待时间:
-
L1 (快速恢复):如果 Bus-Off 重试次数未达到
CanSMBorCounterL1ToL2,则等待CanSMBorTimeL1(较短时间)后尝试恢复。 -
L2 (慢速恢复):如果连续失败次数过多,则进入 L2 阶段,等待
CanSMBorTimeL2(较长时间),以避免在故障严重时频繁冲击总线。 -
随机延迟:如果开启了
CanSMEnableBusOffDelay,会在上述时间基础上增加一个随机抖动,防止多个 ECU 同时重启导致总线再次冲突。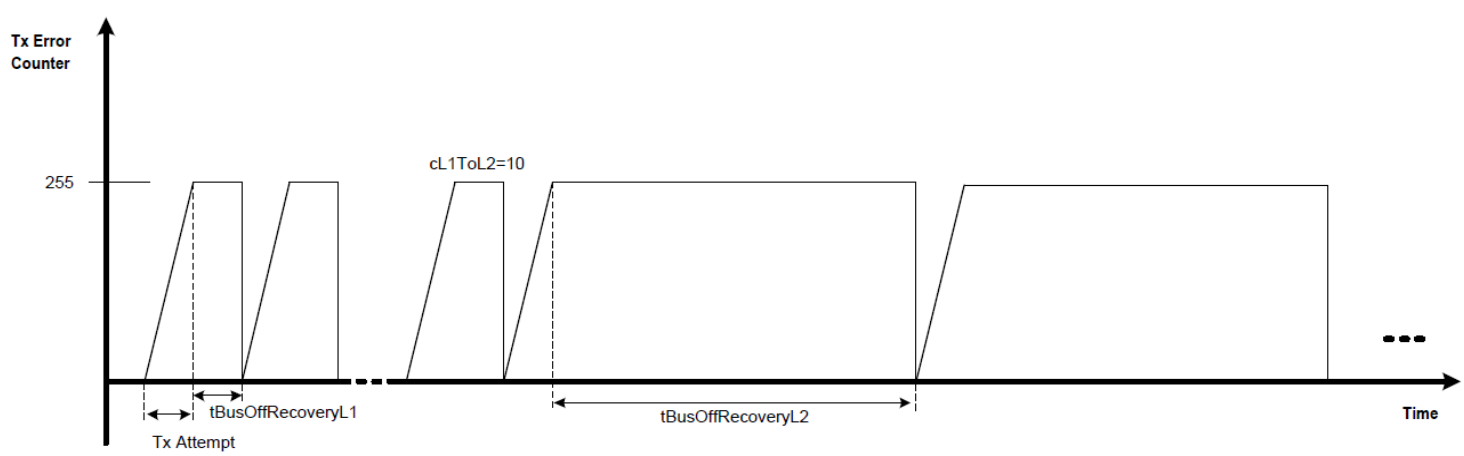
-
-
Bus-Off 发生时 (E_BUS_OFF)
一旦收到
CanSM_ControllerBusOff回调:- 通知 BswM:状态切至
CANSM_BSWM_BUS_OFF。 - 通知 ComM:通信模式降级为
COMM_SILENT_COMMUNICATION(只听不发)。 - 记录故障:向 DEM 报告
PRE_FAILED。 - 联动停止:如果一个网络有多个控制器,其中一个 Bus-Off,其他控制器也会被一并停止。
- 通知 BswM:状态切至
-
恢复通信 (E_TX_ON)
当等待时间结束并成功重启控制器后:
- 开启 PDU:根据 ECU Passive 状态,将
CanIf设为ONLINE或TX_OFFLINE_ACTIVE。 - 模式回升:通知 BswM 恢复全通信,并向 ComM 发送
COMM_FULL_COMMUNICATION指示。
- 开启 PDU:根据 ECU Passive 状态,将
-
恢复成功判定 (G_BUS_OFF_PASSIVE)
这是 BOR 逻辑闭环的关键点。只有满足以下条件,Bus-Off 计数器才会重置,DEM 才会上报
PASSED:- 基于时间:从开启发送(E_TX_ON)起,正常运行超过
CANSM_BOR_TIME_TX_ENSURED。 - 基于确认:或者开启了轮询模式,且
CanIf确认所有控制器都有成功的发送或接收记录。
- 基于时间:从开启发送(E_TX_ON)起,正常运行超过
-
波特率更改 (T_CHANGE_BR_REQUEST)
在全通信状态下,CanSM 允许通过
CanSM_SetBaudrate异步更改波特率。- 触发
T_CHANGE_BR_REQUEST后,会通知 BswM 进入CANSM_BSWM_CHANGE_BAUDRATE状态进行流程同步。
- 触发
🔄 状态流转汇总表
| 触发/状态 | 动作 (Action) / 效应 (Effect) | 目的 |
|---|---|---|
| T_BUS_OFF | E_BUS_OFF |
停止发送,降级模式,上报 DEM |
| S_RESTART_CC | DO_SET_CC_MODE_STARTED |
尝试重启 CAN 硬件控制器 |
| G_TX_ON (Wait) | 根据计数器选择 L1 或 L2 时间 | 故障恢复间隔控制 |
| E_TX_ON | CanIf_SetPduMode(ONLINE) |
重新开启总线通信 |
| G_BUS_OFF_PASSIVE | 重置计数器,DEM PASSED | 确认 Bus-Off 故障已真正消除 |
其中子状态CANSM_BSM_S_TX_TIMEOUT_EXCEPTION为:
CANSM_BSM_S_TX_TIMEOUT_EXCEPTION(发送超时异常)子状态机旨在通过重启控制器的方式来尝试恢复异常的发送功能。当底层驱动检测到发送超时并触发 CanSM_TxTimeoutException 回调时,状态机会进入此流程。
其核心逻辑依然遵循 CanSM 典型的“请求-确认”循环,但目的变为“冷启动”硬件:
-
核心异常恢复流程
该子状态机通过先“停止”后“启动”控制器的序列,尝试重置控制器的发送逻辑:
第一阶段:强制停止控制器 (S_CC_STOPPED)
- 动作 (DO Action):只要处于
S_CC_STOPPED状态,CanSM 会持续检查并调用CanIf_SetControllerMode将控制器设为CAN_CS_STOPPED。 - 跳转逻辑:
- API 成功:当 API 调用返回
E_OK时,满足G_CC_STOPPED_E_OK判定条件。 - 确认指示:收到所有控制器的停止指示回调后,触发
T_CC_STOPPED_INDICATED跳转到下一阶段。 - 超时处理:如果超过
CANSM_MODEREQ_REPEAT_TIME未收到反馈,则触发T_CC_STOPPED_TIMEOUT重新尝试。
- API 成功:当 API 调用返回
第二阶段:重新启动控制器 (S_CC_STARTED)
- 动作 (DO Action):持续请求
CanIf_SetControllerMode为CAN_CS_STARTED。 - 跳转逻辑:
- API 成功:满足
G_CC_STARTED_E_OK。 - 确认指示:收到所有控制器的启动指示回调后,触发
T_RESTART_CC_INDICATED。
- API 成功:满足
- 动作 (DO Action):只要处于
-
最终退出效应 (ExitPoint: TxTimeout)
与常规 Bus-Off 恢复不同,发送超时异常恢复在退出时有一个关键的自动操作:
- 自动恢复通信:一旦收到
T_CC_STARTED_INDICATED信号,在退出子状态机时,CanSM 会自动调用CanIf_SetPduMode(CANIF_ONLINE)。
这确保了控制器在重启后,报文传输(PDU Mode)能够立即回到正常工作状态。
- 自动恢复通信:一旦收到
在这个子状态机中,执行完 DO Action 后的行为是:
- 挂起等待:在 Guard 条件满足(API 返回
E_OK)后,状态机保持在当前状态(或逻辑上的 WAIT 状态)。 - 不直接退出:必须等到硬件层给出 Indication(指示)。
- 循环直到成功:如果硬件没反应,通过 TIMEOUT 机制不断回到 DO Action 重新发起请求。
CANSM_BSM_S_CHANGE_BAUDRATE
CanIf_SetBaudrate() 如果直接设置波特率失败,执行
- 设置CAN控制器为Stopped状态,CanIf_SetControllerMode(CAN_CS_STOPPED)
- 设置CAN控制器为Started状态,CanIf_SetControllerMode(CAN_CS_STARTED)
CANSM_BSM_CHANGE_BAUDRATE 子状态机负责处理波特率的动态更改。CanSM 提供了两种路径:一种是直接更改(Direct),另一种是通过重启序列(Stop-Change-Start)进行的异步更改。
-
路径一:直接更改 (Direct Change)
当调用
CanSM_SetBaudrate时,状态机会首先尝试“最快”的方式:- DO Action: 执行
DO_SET_BAUDRATE_DIRECT,立即调用CanIf_SetBaudrate。 - 跳转逻辑:
- 成功 (G_SET_BAUDRATE_DIRECT_OK): 如果 API 返回
E_OK,逻辑直接结束,认为波特率已生效。 - 失败 (G_SET_BAUDRATE_DIRECT_NOT_OK): 如果 API 返回
E_NOT_OK,说明当前硬件状态不支持直接修改,状态机会自动切换到“路径二”进行处理。
- 成功 (G_SET_BAUDRATE_DIRECT_OK): 如果 API 返回
- DO Action: 执行
-
路径二:异步重启更改 (Async Change Sequence)
如果直接更改失败,CanSM 会通过标准的“停止-修改-启动”序列来确保硬件正确重置:
阶段 A:停止控制器 (S_CC_STOPPED)
- DO Action: 持续请求
CAN_CS_STOPPED。 - 反馈跳转: 收到所有控制器的
T_CC_STOPPED_INDICATED后向下流转。
阶段 B:执行效应 (E_CHANGE_BAUDRATE)
这是核心动作点,在跳转过程中执行:
- 模式降级: 通知 ComM 进入
COMM_NO_COMMUNICATION(因为重启期间总线不可用)。 - 再次修改: 在控制器停止状态下,再次调用
CanIf_SetBaudrate。
阶段 C:重新启动 (S_CC_STARTED)
- DO Action: 持续请求
CAN_CS_STARTED。 - 反馈跳转: 收到
T_CC_STARTED_INDICATED后,准备退出子状态机。
- DO Action: 持续请求
-
最终出口判定 (Guarding conditions)
当硬件重启完成后,子状态机会检查外部的通信请求,决定下一步去向:
- 返回 FullCom: 如果最新的请求是
FULL或SILENT模式,通过G_NO_COM_MODE_NOT_REQUESTED路径回到主状态机的通信流程中。 - 保持 NoCom: 如果此时已经请求了
COMM_NO_COMMUNICATION,则通过G_NO_COM_MODE_REQUESTED路径跳转,这避免了不必要的通信恢复。
- 返回 FullCom: 如果最新的请求是
📝 执行 DO Action 后的状态流转
| 执行的 DO Action | API 返回 E_OK 后 | 最终跳转触发点 | 超时处理 |
|---|---|---|---|
| DO_SET_BAUDRATE_DIRECT | 判定 Guard 条件 | 无需等待 Indication | 若失败则转入异步序列 |
| DO_SET_CC_MODE_STOPPED | 满足 Guard | 等待 T_CC_STOPPED_INDICATED |
触发 TIMEOUT 重新执行 |
| DO_SET_CC_MODE_STARTED | 满足 Guard | 等待 T_CC_STARTED_INDICATED |
触发 TIMEOUT 重新执行 |
模式切换
==启动流程:No Communication → Full Communication==
这是最标准的硬件初始化序列。它严格遵循“收发器 Normal -> 控制器 Stopped -> 控制器 Started”的逻辑。
sequenceDiagram
participant ComM
participant CanSM
participant BswM
participant CanIf_Trcv as CanIf (Transceiver)
participant CanIf_Ctrl as CanIf (Controller)
Note over CanSM: 状态: S_NO_COMMUNICATION
ComM->>CanSM: CanSM_RequestComMode(FULL_COM)
rect rgb(240, 240, 240)
Note right of CanSM: 步骤 1: 准备收发器 (S_TRCV_NORMAL)
CanSM->>CanIf_Trcv: CanIf_SetTrcvMode(NORMAL)
CanIf_Trcv-->>CanSM: CanSM_TransceiverModeIndication(NORMAL)
end
rect rgb(240, 240, 240)
Note right of CanSM: 步骤 2: 重置控制器 (S_CC_STOPPED)
CanSM->>CanIf_Ctrl: CanIf_SetControllerMode(STOPPED)
CanIf_Ctrl-->>CanSM: CanSM_ControllerModeIndication(STOPPED)
end
rect rgb(240, 240, 240)
Note right of CanSM: 步骤 3: 启动控制器 (S_CC_STARTED)
CanSM->>CanIf_Ctrl: CanIf_SetControllerMode(STARTED)
CanIf_Ctrl-->>CanSM: CanSM_ControllerModeIndication(STARTED)
end
Note right of CanSM: 步骤 4: 开启通信 (Effect: E_FULL_COM)
CanSM->>CanIf_Ctrl: CanIf_SetPduMode(ONLINE)
CanSM->>BswM: BswM_CanSM_CurrentState(FULL_COM)
CanSM->>ComM: ComM_BusSM_ModeIndication(FULL_COM)
Note over CanSM: 状态: S_FULL_COMMUNICATION==关机流程:Full Communication → No Communication (不支持 PN)==
关机时,CanSM 会先停止控制器,再将收发器置于 Standby 模式,以节省功耗。
sequenceDiagram
participant ComM
participant CanSM
participant CanIf_Trcv as CanIf (Transceiver)
participant CanIf_Ctrl as CanIf (Controller)
Note over CanSM: 状态: S_FULL_COMMUNICATION
ComM->>CanSM: CanSM_RequestComMode(NO_COM)
rect rgb(230, 230, 230)
Note right of CanSM: 步骤 1: 停止控制器
CanSM->>CanIf_Ctrl: CanIf_SetControllerMode(STOPPED)
CanIf_Ctrl-->>CanSM: CanSM_ControllerModeIndication(STOPPED)
end
rect rgb(230, 230, 230)
Note right of CanSM: 步骤 2: 控制器进入睡眠
CanSM->>CanIf_Ctrl: CanIf_SetControllerMode(SLEEP)
CanIf_Ctrl-->>CanSM: CanSM_ControllerModeIndication(SLEEP)
end
rect rgb(230, 230, 230)
Note right of CanSM: 步骤 3: 收发器进入待机 (S_TRCV_STANDBY)
CanSM->>CanIf_Trcv: CanIf_SetTrcvMode(STANDBY)
CanIf_Trcv-->>CanSM: CanSM_TransceiverModeIndication(STANDBY)
end
CanSM->>ComM: ComM_BusSM_ModeIndication(NO_COM)
Note over CanSM: 状态: S_NO_COMMUNICATION==异常恢复:Bus-Off 恢复流程 (BOR)==
当硬件发生 Bus-Off 时,CanSM 会暂时关闭发送功能,并尝试重启控制器。
sequenceDiagram
participant DEM
participant CanSM
participant CanIf_Ctrl as CanIf (Controller)
participant CanDrv as CAN Driver
CanDrv-->>CanSM: CanSM_ControllerBusOff(Ctrl_0)
rect rgb(255, 240, 240)
Note right of CanSM: 步骤 1: 发生 Bus-Off (E_BUS_OFF)
CanSM->>DEM: Dem_SetEventStatus(BUS_OFF, PRE_FAILED)
CanSM->>CanIf_Ctrl: CanIf_SetPduMode(OFFLINE)
end
Note over CanSM: 等待 BOR 时间 (L1 或 L2)
rect rgb(240, 255, 240)
Note right of CanSM: 步骤 2: 重启控制器 (S_RESTART_CC)
CanSM->>CanIf_Ctrl: CanIf_SetControllerMode(STARTED)
CanIf_Ctrl-->>CanSM: CanSM_ControllerModeIndication(STARTED)
end
Note right of CanSM: 步骤 3: 恢复发送 (E_TX_ON)
CanSM->>CanIf_Ctrl: CanIf_SetPduMode(ONLINE)
Note over CanSM: 运行并监测 T_BOR_TX_ENSURED
CanSM->>DEM: Dem_SetEventStatus(BUS_OFF, PASSED)状态切换中的组件变化规律
| 切换类型 | 控制器 (Controller) 变化 | 收发器 (Transceiver) 变化 | PDU 传输状态 |
|---|---|---|---|
| 启动 (Go Full) | Stopped → Started | Standby → Normal | Offline → Online |
| 关机 (Go No) | Started → Stopped → Sleep | Normal → Standby | Online → Offline |
| Bus-Off 恢复 | Started (Error) → Started | 保持 Normal | Online → Offline → Online |
| 波特率切换 | Started → Stopped → Started | 保持 Normal | Online → Offline → Online |
Busoff
除了上面所说的总线状态机,CanSM模块还有另外一个小型状态机,那就是用来实现的Busoff 恢复机制。
当CanSM模块从CanIf模块收到 Busoff 通知时,将会进入 Busoff 恢复的状态,恢复机制如下:
- 快恢复,产生 Busoff 后,延时 CanSMBorTimeL1 时间尝试恢复;
- 快恢复次数达到 CanSMBorCounterL1ToL2 后,进行慢恢复;
- 慢恢复,产生 Busoff 后,延时 CanSMBorTimeL2 时间尝试恢复;
- 慢恢复次数为无限次。
尝试恢复指的是,重新打开Can的发送能力,并从Busoff Recovery状态切换至CHECK_BUS_OFF状态。在首次进行快恢复和慢恢复时,CanSM模块会分别给出回调函数通知用户。
当 CanSM 尝试恢复 Busoff 后,有两种方法对总线是否恢复进行确认。
- 若 CanSMBorTxConfirmationPolling 为 false,停留在BUS_OFF_CHECK状态没有超过时间参数CanSMBorTimeTxEnsured,在此时间段内,没有新的 Busoff 事件产生,则认为 Busoff恢复成功。
- 若 CanSMBorTxConfirmationPolling 为 true,停留在 BUS_OFF_CHECK状态,直到检测到确实有一帧 Can 报文发送成功并给出了发送确认则认为 Busoff 恢复成功。这种情况下,需要调用 CanIf 的CanIf_GetTxConfirmationState 接口。
Busoff 恢复成功后,BUS_OFF_CHECK状态将切换为 NO_BUS_OFF状态,总线通信恢复正常(注:BUS_OFF_CHECK和NO_BUS_OFF是FULLCOM状态中的两个小状态)。
如果Busoff 恢复不成功,节点一直在慢恢复期,意味着该节点不会外报文(应用报文和网络管理报文均不会外发),其他节点会上报对应的节点丢失故障。
概述
什么是Can Bus Off
车上有一个ECU 1, 一直向总线发送消息,可怎么都发送不出去。
如果这个累计到一定的次数(255),按照CAN总线协议: ECU 1自己进入 BUSOFF模式,这个时候ECU 1 一时半会是不能发送信息了。
BusOff 后如何处理
ECU 1在自己内部检测到BUS OFF后,默默的从逻辑上退出了总线,暂时他没妨碍大家,ECU 1他自己也搞不明白啥回事,于是ECU 1拿着小本子,记下了 x年x月x日x时x分x秒, 汽车电压,里程,xxx 是多少多少,我bus off 了。
写完备案后,ECU 1 开始数时间,等待 5 秒后,重启自己的CAN模块
BusOff时计数的变化规律
bus off是个非常集体的概念:
- ECU自己发送失败,TX error count + 8,
- ECU自己发送成功,TX error count - 1,
这个TX error count 超过255,ECU就必须进入Bus Off 状态,并需要逻辑上断开总线
Can Frame的一些常见错误
- 发送ECU检查
- 有无ACK
- CRC检查,CRC Delimiter, ACK Delimiter,EOF等
- BIT监控, 送的那个ECU,自己校对每个BIT,看有没有都送对(ID区域,和ACK区域除外)
- 接收ECU检查
- CRC检查,CRC Delimiter, ACK Delimiter,EOF等
- 检查有无连续6比特是全0、或全1的
故障界定
为了避免某个设备因为自身原因(例如硬件损坏)导致无法正确收发报文而不断的破坏总线的数据帧,从而影响其它正常节点通信,CAN网络具有严格的错误诊断功能,CAN通用规范中规定每个CAN控制器中有一个发送错误计数器和一个接收错误计数器。根据计数值不同,节点会处于不同的错误状态,并根据计数值的变化进行状态转换,状态转换如下图所示。
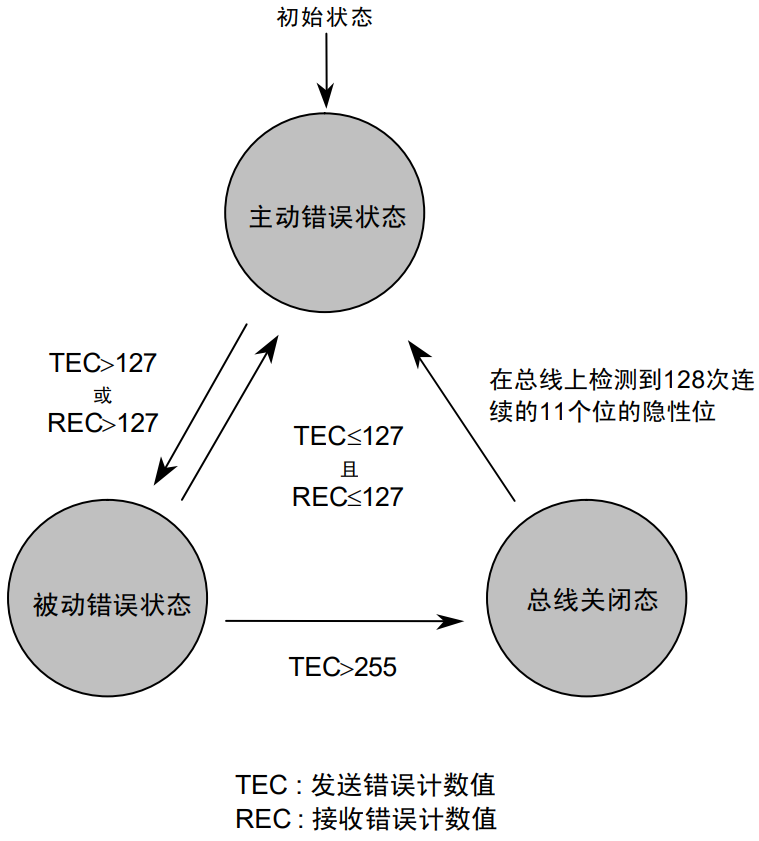
以上三种错误状态表示发生故障的严重程度,总线关闭是节点最严重的错误状态。并且,节点在不同的状态下具有不同的特性,在总线关闭状态下,节点不能发送报文或应答总线上的报文,也就意味着不能再对总线有任何影响。
状态跳转和错误计数的规则使得节点在发生通信故障时有了较好的自我错误处理和恢复机制,从一种较严重的错误状态跳转到另一种严重性相对较低的状态,本质上就是一种恢复过程。上图所呈现的转换过程是CAN通用规范所要求的,我们从设备供应商买回来的CAN控制器已经把这些功能固化在硅片之中。
在通信过程中,错误主动和错误被动两种状态下节点的恢复过程一般不需要MCU进行额外的编程处理,直接使用CAN控制器固有功能即可。但对于总线关闭状态,往往不直接使用CAN控制器固有的恢复过程,而是对其进行编程控制,以实现“快恢复”和“慢恢复”机制。
快恢复和慢恢复
当节点进入总线关闭状态后,如果MCU仅是开启自动恢复功能,CAN控制器在检测到128次11个连续的隐性位后即可恢复通信,在实际的CAN通信总线中,这一条件是很容易达到的。以125K的波特率为例,12811(1/125000)= 0.011264s。这意味着如果节点所在的CAN总线的帧间隔时间大于0.011264s,节点在总线空闲时间内便可轻易恢复通信。我们已经知道,当进入总线关闭状态时,节点已经发生了严重的错误,处于不可信状态,如果迅速恢复参与总线通信,具有较高的风险,因此,在实际的应用中,往往会通过MCU对CAN控制器总线关闭状态的恢复过程进行编程处理,以控制节点从总线关闭状态恢复到错误主动状态的等待时间,达到既提高灵活性又保证节点在功能上的快速响应性的目的。具体包括“快恢复”和“慢恢复”策略,两种策略一般同时应用。
通过以上的讨论,我们可以知道,节点进入总线关闭状态后,存在以下几种恢复情况:
-
MCU仅开启CAN控制器的自动恢复功能,节点只需检测到128次11个连续的隐性位便可以恢复通信,恢复过程如上节图所示。
-
MCU没有开启CAN控制器的自动恢复功能,也不主动干预总线关闭错误,节点将一直无法“自动”恢复总线通信,只能通过重新上电的方式使节点恢复, 恢复过程如下图所示。
-
MCU对CAN控制器的恢复过程进行编程处理,这时,节点的恢复行为由具体的编程逻辑决定,各厂家普遍采用了先“快恢复”后“慢恢复”的恢复策略,恢复过程如下图所示。
MCU编程实现总线关闭“快恢复”和“慢恢复”的一般过程可用以下流程图描述:
节点以正常发送模式发送报文的过程中,如果出现了发送错误,发送错误计数会增加,只要发送错误计数没有超过255, CAN控制器便会自动重发报文,如果出现多次发送错误,使发送错误计数累加超过255,则节点跳转为总线关闭状态。MCU能够第一时间知道节点进入了总线关闭状态(例如在错误中断处理逻辑中查询状态寄存器的相应位),这时MCU控制CAN控制器进入“快恢复”过程,即控制CAN控制器停止报文收发,并进行等待,计时达到需要的时间T1(如100ms)后,MCU重新启动恢复CAN控制器参与总线通信,这样便完成了一次“快恢复”过程。
节点每进入一次“快恢复”过程时,MCU会对此进行计数,当节点“快恢复”计数达到设定的值N(如5次),则后续再次进入总线关闭状态时MCU把恢复总线通信的等待时间T2进行延长(如1000ms),这样便实现了“慢恢复”过程。“快恢复”和“慢恢复”过程的主要区别就在于恢复节点参与总线通信的等待时间的不同。
通过MCU对于总线关闭后的恢复行为进行编程控制,实际上是对CAN控制器的错误管理和恢复机制进行了补充,使得总线关闭状态后的恢复过程更加灵活,更能适应实际应用的需要。对于 “快恢复”和“慢恢复”的等待时间,以及“快恢复”计数多少次后进入“慢恢复”过程,不同厂家可根据具体的需求进行编程实现。
[!note]
当我们进行干扰的时候,不用Rx口就可以知道数据帧发送是否正确,以下使用Ack干扰来举例:
CAN总线采用"线与"逻辑,发送节点在ACK槽(ACK Slot)发送隐性位(逻辑1),而正确接收的节点会覆盖为显性位(逻辑0)。发送节点通过实时回读总线电平与自身发送的电平对比:
- 成功应答:若回读到显性位(0),说明至少有一个节点正确接收。
- 应答错误:若回读到隐性位(1),说明无节点应答,触发ACK错误。
此过程由CAN控制器硬件自动完成,无需软件干预。发送节点在TX发送的同时通过内部回环检测总线实际状态,而非依赖RX口 。
问题:不走Rx是怎么知道发出去的报文是正确的‼‼‼‼‼‼‼‼
ComM
[!tip]
前面分别介绍了ComNm和ComSM两兄弟,这一章则来看看两兄弟的老板,那就是Communication Stack中管理层中最核心的一个模块,那就是ComM模块。
前面已经分别介绍了干活两兄弟NM模块和SM模块,NM模块主要负责的是基于总线报文管理ECU休眠,SM模块则是控制总线通信状态,这两兄弟其实都是实际执行者,ComM模块则是真正的总线管理者,用户只要对ComM模块告知自己想要的通信模式,ComM模块则会直接协调NM和SM两兄弟直接干活以达到用户想要的通信模式。
ComM 模块位于 AUTOSAR 的系统服务层,透过 RTE 与用户(这里的用户指的是可以对ComM模块下达请求的模块,可以是BswM,SWC, Runables等)直接交互。向下控制各总线状态管理器和网络管理器(SM 和 Nm),为用户提供统一的通信管理功能,同时协调SM 和 Nm 之间的状态关系。
graph TD
%% 节点定义
subgraph Upper_Layer [应用层]
App1[App]
App2[App]
App3[App]
end
ComM[AUTOSAR ComM]
subgraph Mid_Layer [网络管理与状态管理层]
BSM1["<Bus Specific><br/>State Manager"]
BSM2["<Bus Specific><br/>State Manager"]
subgraph NM_Group [NM 接口层]
NmInt[Generic NM Interface<br/>Nm]
BSNM1["<Bus Specific><br/>NM"]
BSNM2["<Bus Specific><br/>NM"]
end
end
BSIf["<Bus Specific><br/>Interface"]
%% 连接关系
Upper_Layer --- ComM
ComM --- BSM1
ComM --- BSM2
ComM --- NmInt
NmInt --- BSNM1
NmInt --- BSNM2
BSM1 --- BSIf
BSM2 --- BSIf
BSNM1 --- BSIf
BSNM2 --- BSIf
%% 样式美化
style Upper_Layer fill:none,stroke:none
style App1 fill:#A9A9A9,stroke:#333,stroke-width:1px
style App2 fill:#A9A9A9,stroke:#333,stroke-width:1px
style App3 fill:#A9A9A9,stroke:#333,stroke-width:1px
style ComM fill:#4FC3F7,stroke:#039BE5,stroke-width:1px,color:#000
style BSM1 fill:#81C784,stroke:#388E3C,stroke-width:1px,color:#000
style BSM2 fill:#81C784,stroke:#388E3C,stroke-width:1px,color:#000
style NM_Group fill:none,stroke:none
style NmInt fill:#E1BEE7,stroke:#8E24AA,stroke-width:1px,color:#000
style BSNM1 fill:#E1BEE7,stroke:#8E24AA,stroke-width:1px,color:#000
style BSNM2 fill:#E1BEE7,stroke:#8E24AA,stroke-width:1px,color:#000
style BSIf fill:#FFCC80,stroke:#F57C00,stroke-width:1px,color:#000ComM 定义了三种基本的通信状态,但对外部用户(如应用软件组件 SW-C 或诊断 DCM)的请求权限做了严格区分:
- COMM_FULL_COMMUNICATION (全通信):最高模式,允许物理通道进行数据的发送和接收。
- COMM_NO_COMMUNICATION (无通信):最低模式,强制停止物理通道的所有发送和接收活动。
- COMM_SILENT_COMMUNICATION (静默通信):中间模式。用户不能直接请求此模式,它仅由系统内部用于与网络管理(NM)进行同步。
ComM 作为一个协调者,需要处理来自多个独立用户的请求:
- 仲裁原则:如果多个用户对同一个通道提出了不同的请求,ComM 遵循“最高者胜”策略。例如,只要有一个用户请求“全通信”,那么该通道的最终目标状态就是“全通信”,即使其他用户请求的是“无通信”。
- 覆盖机制:ComM 不会给用户请求排队。如果同一个用户连续发送了两次请求,后一次请求会立即覆盖前一次,无论前一次请求是否已经处理完成。
- 诊断特权:当诊断模块(DCM)发出诊断激活指示时,ComM 会将其自动视为一个“全通信”请求。
目标模式与实际模式的分离:强调了“想变”和“变完”之间的区别:
- 目标状态:ComM 根据用户请求计算出一个“目标模式”。
- 实际状态:真正的物理总线状态由各个总线状态管理器(如 CanSM)控制。由于硬件切换需要时间,或者可能存在模式禁止(Inhibition),目标模式与实际模式在时间上可能不一致。
- 查询机制:
- 用户可以查询自己请求过什么模式。
- 用户也可以查询通道当前的真实模式。当调用查询接口时,ComM 会向底层的总线状态管理器获取最新状态并反馈。
除了用户请求外,ComM 还有一个底层的权限开关:
- 初始化保护:ComM 初始化后,默认所有通道的“通信许可”标志位均为
FALSE(不允许通信)。 - 动态控制:系统必须通过专门的 API 指示(通常来自 EcuM 或 BswM)将该标志位显式设为
TRUE,该通道才具备开启通信的前提条件。
ComM 模块主要功能如下:
- 初始化
- 用户或 DCM 请求通信模式
- 通知应用通信模式切换
- 限制通道或 ECU 的通信功能
- 与 EcuM 的唤醒功能协同、与 BswM 控制通信协同
- 控制各通道的总线状态
- 请求或释放网络管理服务
模块交互
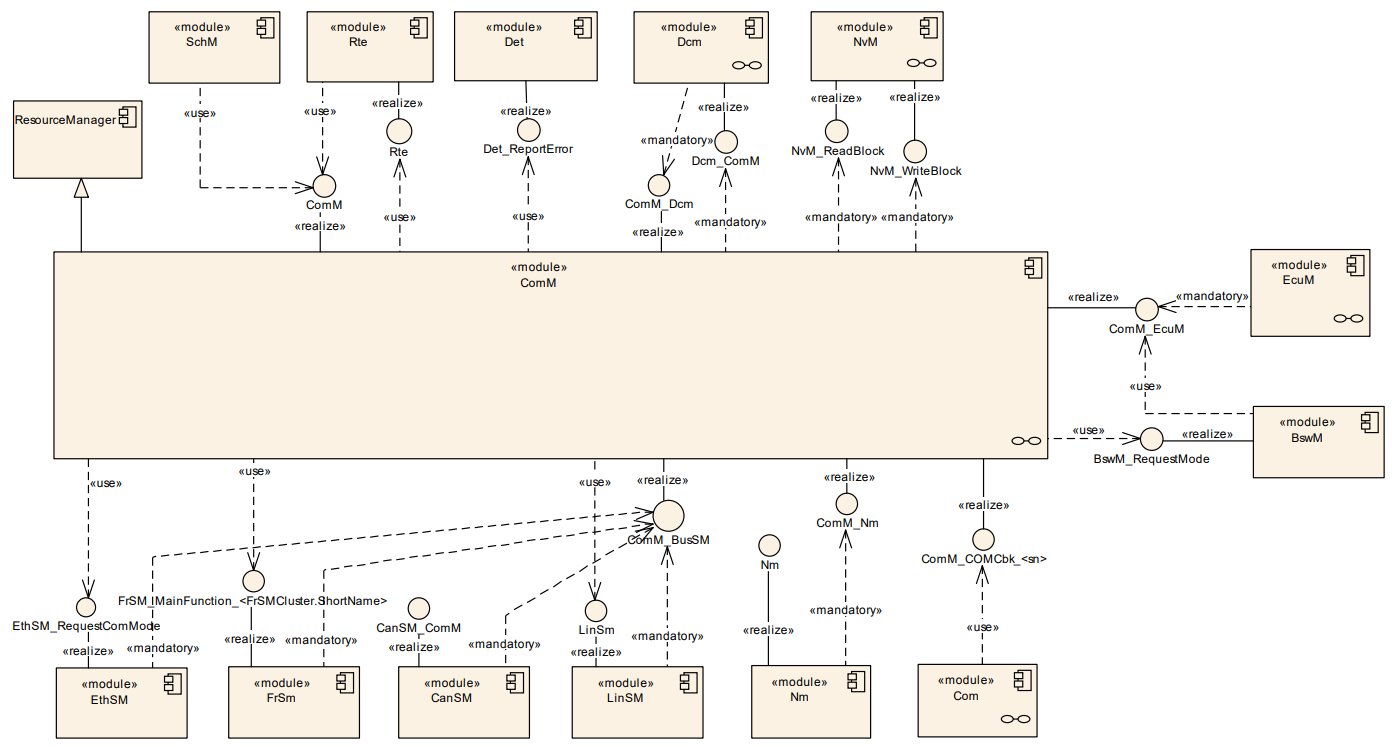
-
模式请求的传递路径 (RTE & ComM)
- **RTE **: 充当“中转站”,将上层应用(User)的通信模式请求传达给
ComM模块,并将ComM的状态反馈给用户。 - **ComM **: 它是核心决策者,负责收集所有用户(包括应用、DCM、总线网络管理等)的请求,并仲裁出当前网络应处于的状态(如
FULL、SILENT或NO通信)。
- **RTE **: 充当“中转站”,将上层应用(User)的通信模式请求传达给
-
状态控制与仲裁 (BswM & EcuM)
- **BswM **: 负责“模式仲裁”和“模式控制”。
- 它可以根据配置转发请求给
ComM。 - 核心权力:它通过调用
Com_IpduGroupControl来实际控制 PDU 组的开启或关闭。 - 状态接收:
ComM必须向BswM指示所有通道主状态和 PNC(部分网络簇)状态的变化。
- 它可以根据配置转发请求给
- **EcuM **: 负责基础的唤醒验证,并将验证后的指示发给
ComM。它与BswM协同处理 ECU 的停机和允许通信的逻辑。
- **BswM **: 负责“模式仲裁”和“模式控制”。
-
总线状态管理器 (Bus State Managers)
各类总线管理器(LIN, CAN, FlexRay, Ethernet SM)的共同职责:
- 它们负责将
ComM的抽象请求(通信模式)映射为具体的总线物理状态。 - 例如,
CanSM负责控制 CAN 控制器和收发器的实际模式。
- 它们负责将
-
特殊模块的交互逻辑
- **DCM **: 诊断模块被视为一个特殊的“用户”。当需要执行诊断时,它会请求
COMM_FULL_COMMUNICATION以确保通信链路处于激活状态。 - **NVRAM Manager **: 负责存储和读取非易失性配置数据。
- 初始化顺序:
NVRAM必须在ComM之前完成初始化,否则ComM无法读取配置。 - 去初始化:当
ComM停止工作时,会将当前数据写入NVRAM。
- 初始化顺序:
- NM: 用于网络协同,确保网络中的多个节点能够同步启动和关闭。
- **COM **: 主要用于通过信号分发 PNC(部分网络簇)的状态信息。
- **DCM **: 诊断模块被视为一个特殊的“用户”。当需要执行诊断时,它会请求
交互图勾勒出了一个 “三层架构”:
- 需求层 (App/DCM/NM): 发出通信需求。
- 管理层 (ComM/BswM/EcuM): 接收并仲裁需求,决定“该不该通”以及“什么时候通”。
- 执行层 (CanSM/LinSM等): 将决策转化为具体的硬件驱动调用,实现总线的实际开启或关闭。
PNC状态管理
ComM进行通信模式管理提供有两大状态机,其中一个就是PNC 状态管理,在介绍之前,得搞清楚PNC到底是个啥?PNC是Partial Network Cluster的缩写,一般将这些在某种条件下需要保持同样工作状态,且连接在同一总线(或由网关连接)的ECU称之为一组PNC,对这些ECU统一进行网络管理。在一些特殊应用中,如果网关也使能了PNC,那么则可以通过网关进行网络协调,让不同总线上的ECU组成一个大型PNC组。
ComM 模块对每组 PN 定义了一组状态机,用于描述各 PN 组的状态、状态转移关系和状态转移动作。该状态机共包含 4 种状态,分别为:
- PNC_NO_COMMUNICATION
- PNC_PREPARE_SLEEP
- PNC_READY_SLEEP
- PNC_REQUESTED
状态切换如下图所示:

观察状态切换图,可以看到上面出现了ERA, EIRA的字眼,无论是开启还是关闭ECU的通信功能,都是需要进行请求的,而这个请求则分为内部请求与外部请求,我们称之为External Internal Request Array,也即EIRA。每一个ECU都需要有EIRA,来根据部分网络活动进而切换IPdu Group的状态。至于ERA,External Requested Array,它主要用于网关,仅收集外部PN请求的场景。网关会将外部PN请求镜像回请求总线,同时将这个请求发送到其他的总线上。IRA,Internal Requested Array,代表ECU内部对于PNC状态的请求,既可以是SWC通过RTE直接请求ComM接口,或者在某种条件满足时,由BswM请求ComM接口。
系统上电后整个PNC的状态在COMM_PNC_NO_COMMUNICATION。
在PNC状态切换过程中如果是主动唤醒节点直接请求FULL通信,或者是网关节点控制的节点在收到网关下的ERA数组的相关状态位,直接从COMM_PNC_NO_COMMUNICATION进入到COMM_PNC_REQUESTED阶段。如果是被动唤醒的节点,则根据接收到唤醒报文中的PNC位状态切换到COMM_PNC_READY_SLEEP或者COMM_PNC_PREPARE_SLEEP。
而COMM_PNC_FULL_COMMUNICATION内部的三个子状态的切换也是根据该节电的是否能被动唤醒功能进行内部的状态切换,主要体现是主动唤醒下需要Request Full相关的操作以及NM报文中对应的UserData中相关的PNC位进行转换的。
总结一下可以让ComM的PNC状态机切换的事件可以来自于:
- 来自用户的请求 ComM_RequestComMode()函数调用
- 来自 EcuM 模块的唤醒通知 ComM_EcuM_WakeUpIndication()
- 来自 Com 模块的 PNC 值变化通知
- ComM 模块内部定时器超时事件
Channel状态管理
上面提到ComM进行通信模式管理提供有两大状态机,另外一个就是Channel状态管理。这里的Channel指的是一个通信总线,比方说,一路ECU有两路CAN,一路FlexRay,那么就可以说对于ComM模块就有3个Channel。ComM 模块对每一个Channel都定义了一个状态机,用于描述通道的各种状态、状态转移关系和状态转移动作。该状态机共包含 3 个主状态,分别为:
- COMM_NO_COMMUNICATION
- COMM_FULL_COMMUNICATION
- COMM_SILENT_COMMUNICATION
其中除 COMM_SILENT_COMMUNICATION 外,其余状态还包含有子状态。其状态转移图如下:

-
COMM_NO_COMMUNICATION:系统上电后进入到COMM_NO_COMMUNICATION,在该状态下具有下面两个子状态
- COMM_NO_COM_NO_PENDING_REQUEST
- COMM_NO_COM_REQUEST_PENDING。
-
COMM_NO_COM_NO_PENDING_REQUEST:在初始化完成ComM后进入该状态,该状态下总线不能进行任何的通信活动,需要等待FULL_COM请求切换状态,请求可来源于:
- 用户请求User Request;
- DCM Notification需要激活对应的通道;
- 来自于EcuM或者NM的Passive WakeUp通知。
-
COMM_NO_COM_REQUEST_PENDING:收到FULL_COM请求后,会切换至COMM_NO_COM_REQUEST_PENDING状态,然后等待Communication Allowed的触发信号,只有 “CommunicationAllowed=TRUE时” 才能将通信模式转换为FULL_COM模式下进行数据通信,如果没有Allowed的使能,则对FULL_COM请求将不会被执行。
-
COMM_FULL_COMMUNICATION:离开NO_COM状态后,则进入COMM_FULL_COMMUNICATION状态,在该状态下总线可以进行正常的数据通信,其也有两个子状态:COMM_FULL_COM_NETWORK_REQUESTED和COMM_FULL_COM_READY_SLEEP。而这两个模式的切换则是会根据NmVariant的变化来变化,后面会对NmVariant进行介绍。
-
COMM_SILENT_COMMUNICATION:该状态主要用于支持NM的Sleep流程处理,是NM状态机的Prepare Sleep阶段,只有在NM进入到prepare Sleep模式下该状态才进入。
总结一下可以让ComM的Channel状态机切换的事件可以来自于:
-
来自 User 的请求 ComM_RequestComMode()函数调用
-
来 自 Dcm 模 块 的 ComM_DCM_ActiveDiagnostic() 和ComM_DCM_InactiveDiagnostic()函数调用
当诊断仪与 Dcm 模块通信时,需要保证通道的正常可用状态,不能进入休眠。这时Dcm 模块通过在适当的时机调用 ComM 模块的 ComM_DCM_ActiveDiagnostic()来请求通道保持在FULL_COM状态 。 完成诊断通信后 , Dcm模块再调用ComM_DCM_InactiveDiagnostic()接口释放对通道的使用。这时如果没有其他用户再使用该通道,则通道最终将进入 NOCOM 模式,通道关闭,所以在前面介绍Channel状态管理状态切换的时候就提到了Dcm模块是让ComM Channel状态切换的一个重要来源。
-
来 自 Nm 模 块 的 网 络 状 态 通 知 ComM_Nm_NetworkMode() 与ComM_Nm_PrepareBusSleepMode()和 ComM_Nm_BusSleepMode()函数调用
-
来自 Nm 的 ComM_Nm_RestartIndication()和 ComM_Nm_NetworkStartIndication()
-
来自 EcuM 模块的唤醒通知 ComM_EcuM_WakeUpIndication()
当某个通信通道发生唤醒事件后,EcuM 会调用 ComM_WakeupIndication()函数通知ComM 模块。该通知会作为通道正常工作的一个触发源,将该通道状态切换到 FULLCOM模式。这时 ComM 会调用网络管理模块的 Nm_PassiveStartup()唤醒网络管理模块。
-
ComM 模块内部定时器等
通信禁止功能
通信禁止包含两种情况:
- 禁止唤醒总线
- 限制通信。
在某些唤醒线路故障情况下,某些应用会错误地请求总线,从而错误地唤醒总线上其他 ECU。这时可以通过调用 ComM_PreventWakeUp()接口,忽略用户请求,从而避免系统错误。该功能称为禁止唤醒总线。该功能只在对应通道进入 NO_COM 或 SILENT_COM时有效。
当通道处于 FULL_COM 模式时,应用可以调用 ComM_LimitChannelToNoComMode()或 ComM_LimitECUToNoComMode()来强制某个通道或整个 ECU 所有通道进入 NO_COM模式。这时 ComM 将忽略 User 对通道的占用,调用 Nm_NetworkRelease()释放网络管理。当远程休眠条件满足时,通道将最终进入 NO_COM 模式。该功能称为限制通信。该功能只在对应通道处于 FULL_COM 时有效。
不同类型的NM
NM模块有一个参数叫做NmVariant,可以指定每一个通道所对应的NM模块的网络管理能力,分为四种类型:
- FULL:该通道具备网络管理模块的所有功能,因此本 ECU 具备保持总线唤醒的能力,同时可以由 NM 向 ComM 模块指示何时进入网络同步休眠状态。
- PASSIVE:该通道的网络管理模块处于 PASSIVE 模式,即本身只接收网络管理报文,但不向外发送网络管理报文。本 ECU 不具备保持总线唤醒的能力,但可以根据其他 ECU的网络管理报文,向 ComM 模块指示进入网络同步休眠状态。
- LIGHT:该通道不具有网络管理模块,因此不会接收或发送网络管理报文。但可以通过配置定时器,在没有通信需求的一段时间以后自动进入休眠状态。该配置项一般用于需要延迟休眠的场景。
- NONE:该通道不具有网络管理模块,因此不会接收或发送网络管理报文。一旦进入FULL_COM模式就不会退出,也不会自动进入休眠状态,只有通过 ECU 电源才能控制网络关闭。
在同一个 ECU 上,FULL 和 PASSIVE 不能同时存在,即当某个通道配置了 PASSIVE类型时,本 ECU 上所有通道都只能为 PASSIVE、LIGHT 或 NONE 之一,不能为 FULL。当某个通道配置了 FULL 时,本 ECU 上所有通道都只能为 FULL、LIGHT 或 NONE 之一,不能为 PASSIVE:
- FULL 是最常见的网络类型,在大部分应用场景中推荐使用该配置,这时需要将 NM的 PASSIVE 模式禁用。在 FULL 类型网络通道上,状态转移图与标准图一致。
- PASSIVE 节点对网络的休眠唤醒没有决定权,完全听从其他节点的仲裁。例如本节点在仍有发送应用报文的需求时,网络上其他节点决定休眠,则本节点会无条件同步休眠,关闭总线接口的发送功能。
- LIGHT 节点和 NONE 节点不具备网络管理功能,若接入一个具备网络管理功能的网络中,会影响网络正常休眠唤醒功能。一般应当独立使用或同样类型的节点组网。这两种类型的通道没有 SILENT 状态。NONE 节点一旦进入 FULL_COM 状态就无法切回NO_COM,除非系统复位。LIGHT 节点从 FULL_COM 到 NO_COM 是通过内部的一个定时器实现的,该定时器参数值由配置参数 ComMNmLightTimeout 决定。
User、PNC与Channel的映射
上面提到了ComM模块的两种状态机,那么怎么样正确使用这两种状态机呢?用户,PNC,Channel三者的映射关系如下图所示:

每个 User 向下可以关联多个 PNC,每个 PNC 向上也可以关联多个 User,User 既可以关联 PNC 也可以直接关联 Channel,每个 PNC 向下可以关联多个 Channel,每个 Channel向上也可以关联多个 PNC 或 User。但是同一 Channel 不能既关联 User,又关联该 User下的 PNC。说得简单点就是自上而下,是交叉树状自上而下,用户想要控制一个一个总线接口,可以是User->PNC->Channel, 也可以是User->Channel。
User 可以通过接口请求 FULLCOM 和 NOCOM 模式,此时所有该 User 映射的通道或 PNC 都会收到请求。由于一个通道或 PNC 可以映射多个 User,因此只有当映射的所有 User 都请求了 NOCOM 时,ComM 才会在该通道或 PNC 上释放通信能力,否则只要有一个 User 请求 FULLCOM,ComM 都会为该通道或 PNC 保持通信能力。
在某些特殊情况下,用户可以通过 API 限制某个通道或整个 ECU 的通信能力,这时即使有用户请求FULLCOM,该请求也会被暂时抑制。限制通信的优先级高于 User 对通道的请求。
DCM 模块会使用某些通道作为诊断通道。它通过 API 激活该通道的通信能力。此时不论该通道映射的 User 请求何种模式,也不论该通道是否被限制通信,ComM 都会为该通道保持通信能力,也就是说 DCM 激活通道的优先级最高。
状态保存
ComM 的一些配置状态和计数值可以保存到非易失存储器中,在下次上电后恢复。可以保存的内容包含:
- ECU 所有通道的禁止唤醒总线状态(NoWakeup)
- ECU 组分类(EcuGroupClassification)
- 禁止计数器
当使能此功能时,需要在 NvM 模块配置这几个 Block,且需要将其在 NvM 模块中将这几个模块配置在 ReadAll 和 WriteAll 列表中,以便在上电时自动恢复数据,以及下电前自动保存数据。
PduR、IpduM
首先介绍一个在Communication Stack中出现频率很高的词I-PDU, 全称为Interaction Layer Protocol Data Unit, 意思就是交互PDU,可以理解成是软件协议层面上的一个完整性消息。PduR即为PDU Router。PduR 模块位于 AUTOSAR 的通信服务的核心位置, 作为上层模块与下层接口模块或传输层模块传输 I-PDU 的桥梁。说的简单一点就是个内部消息路由器,当PduR 收到底层传输层或者interface抽象层传输的 I-PDU后,将其传输到对应的服务模块,而上层服务模块需要发送 I-PDU时,PduR模块则会将消息传输到相应的传输层或者interface抽象层。
通信模块根据其在 AUTOSAR 架构中的位置和传输 I-PDU时的角色,可以分为三类:
- 上层模块:上层模块位于 PduR 上层,一般包括 Com、 Dcm 和 Cdd。
- 下层接口模块:下层接口模块位于 PduR 下层,一般包括 CanIf、 LinIf、 SoAdIf、 FrIf、 CddIf 等。
- 下层传输层模块:下层传输层模块同样位于 PduR 下层,一般包括 CanTp、 LinTp、 SoAdTp、 DoIPTp、FrTp 和 CddTp 等。
而PduR模块则是连接这些模块的枢纽,位于上层模块和下层模块之间,充当一个终极消息中转站。

PduR模块主要包含两部分,分别是路由表和路由引擎,其中路由表非常好理解,就是它会给上层服务的所有 I-PDU编号,静态确定消息路径,里面会包含各种总线特征,比如CAN ID,这样PduR模块就可以根据路由表来进行消息路由,路由引擎则就是用来传输消息的搬运工,负责把 I-PDU从源方路由到目标方。
PduR 模块主要功能如下:
- 初始化
- 接收下层模块(接口模块、传输层模块) I-PDU并传递给上层模块
- 发送上层模块 I-PDU到低层模块
- 接收接口层 I-PDU并传递给其他接口层模块
- 接收传输层 I-PDU并传递给其他传输层模块
I-PDU的传输
下面举一个最简单的例子,如果PduR的下层模块为接口模块,以CAN为例子,那下层接口模块即为CanIf模块。如果Com模块需要通过CAN总线发送一条消息,那么这条消息的流向应该如下:

Com调用PduR_ComTransmit发起消息发送, PduR模块接收到消息查表后确认消息目的方为CAN,然后调用CanIf_Transmit触发CAN消息的发送,消息发送成功后,最终由CanIf模块传来发送确认。
当PduR的下层模块为传输层模块的时候,则当传输层接收到 FF 或 SF 时,传输层将调用 PduR_StartOfReception 通知 PduR模块接收开始, PduR 模块通过调用_StartOfReception 传递给相应的上层模块,例如_StartOfIReception。传输层通过调用函数 PduR__CopyRxData 将数据传递给 PduR, PduR 模块通过调用_CopyRxData 将数据传递给上层模块。当接收完成时传输层模块将调用 PduR_RxIndication 通知 PduR 模块, PduR 将此指示传递给上层模块通过_TpRxIndication 函数。
路由路径
PduR 通过路由路径实现路由。一个路由路径由一个源 Id 和一个(或多个)目的 Id组成。当路由路径只包含一个目的 Id 时,称为单播,当路由路径包含多个目的 Id 时,称为多播。路由路径全部静态配置,不支持动态路由。
某个路由路径的目的可能同时包含多个接口,如 CanIf 接口和 LinIf 接口,为了能够支持整体关闭某种接口, PduR 具有路由路径组的概念。一个路由路径组包含多个目的 Id,它们可以属于同一个路由路径,也可以属于不同路由路径。反过来一个路由路径的不同目的 Id 可以属于不同的路由路径组。
路由路径组也是静态配置的。路由路径组可以单独使能或关闭。每个路由路径组的初始状态由配置决定。 PduR 提供了两个接口函数来动态使能或关闭某个路由路径组,分别为 PduR_EnableRouting()和PduR_DisableRouting(),它们主要由 BswM 模块调用。
Zero Cost Operation
Zero Cost Operation是指当 PduR 只充当简单的路由功能时,为了优化性能而将各主要函数实现为宏的形式。该功能通过配置项 ZeroCostOperation 使能。要使用该功能,必须同时满足如下条件:
- 用户配置的 PduRRoutingTable 路径中仅包含 Com-CanIf, CanIf-Com, Dcm-CanTp,CanTp-Dcm , CanNm-Com , Com-CanNm时;
- PduRGeneral 里 PduRVersionInfoApi 为 FALSE 时;
- 不包含 Routing Group 时。
IpduM模块
在结构上PduR的旁边有一个IpduM(Interaction PDU multiplexer)模块,该模块看上去比较独立,它在AUTOSAR架构中,只和PduR模块和Com模块有交互。PDU多路复用即PDU的PCI相同而SDU布局不同,简单的来说就是使用相同的 IpduM I-PDU 发送或接收不同的 Com I-PDU,再简单一点说就是使用同一个PDU ID来发送不同的报文内容。对于多路复用的I-PDU来说,它的数据流向则变成了Com->PduR->IpduM->PduR->CanIf。
那么IpduM模块是怎么实现PDU复用的呢?IpduM 提供了两种模式来实现多路复用:
-
I-PDU Multiplexing
其实现方式则为将一个多路复用的I-PDU分为一个静态部分和一个动态部分,其中静态部分由零个或多个信号或信号组组成,静态部分信号或者信号组的位置大小都是固定的,不会随着PDU多路复用而变化; 动态部分由Selector Field和一个或多个信号或信号组组成,这一部分除了Selector Field的位置不会变动外,信号和信号组的位置是可以随意发生变化的。如下图所示:

静态部分和动态部分的位置可根据I-PDU进行配置,静态部分和动态部分可以被细分为不同的段。对于每个多路复用的I-PDU,只能定义一个Selector Field,所以IpduM模块就是通过Selector Field的值来进行PD路由,根据其不同的值来解包I-PDU的动态部分的内容。Selector Field大小可以配置为1到16个连续位,其位置也可以通过配置来定义。
-
Multiple PDU to Container Mapping
这种方式就更好理解了,即创建一个容器,然后将多路复用的每一种PDU layout都分配一个Header,当Com层出发信号发送时,则会根据该信号的I-PDU layout的所对应的Header在容器中来进行查找,然后进行数据组装最好进行发送,接收同理。

Com
首先得了解一下AUTOSAT面向信号的通信理念,什么个意思呢?这里的信号可以理解成是应用层关心的实际值,比方说电压值,电流值,转速等,这些都是信号,应用层接收和发送信号的时候,它只需要调用相关信号的接口函数触发动作即可,至于这些信号值是通过哪种方式传送和哪种协议解析,应用层根本不关心,这就是AUTOSAR面向信号的通信理念。为了在软件中实现这个理念,Com模块在这其中起着至关重要的作用。
Com 模块位于 RTE 和 PDUR 的中间,其充当 RTE 和 PDUR 通信服务层的接口层,如下图所示:

其主要功能就是负责为上层提供各种信号的接收和传送,说得简单点一点,就是把很多信号打包成PDU(这里的PDU则是软件协议层面上的一条消息,映射到硬件上,可能是一帧或者几帧,这取决于软件协议组包的方式,比如说TCP\IP协议栈的组包),然后往各种总线上送,或者从各种总线上接收到PDU后解包成信号提供给上层。 但是众所周知,AUTOSAR就是会把简单的东西搞得及其得复杂,所以Com里面又有一大堆新玩意。
[!note]
首先在介绍Com功能时,就不得不提一下DBC和LDF文件了, 在基于AUTOSAR架构进行通信协议栈的研发时,大家不可避免都会涉及到这两种文件,那么这两种文件到底有什么用呢?在这个世界还没有AUTOSAR之前,其实这两种文件就已经存在且被广泛应用,这两种文件主要定义了CAN报文(DBC文件定义)或者LIN报文(LDF文件定义)的组包方式,除此之外还有不同报文的发送和接收熟悉。
在AUTOSAR的方法论中,一切文件皆ARXML,所有输入输出文件都是ARXML文件类型,包括与DBC文件和LDF文件起到相同作用的文件,不过当时这两种文件已经特别通用,所以这两种格式的文件也无缝融入了的AUTOSAR的研发过程中,也有很多软件都能实现DBC文件和LDF文件与ARXML文件之间格式的转换。
关于DBC文件的介绍大家可以参考文章:《细说DBC(一)——初识》,关于LDF文件的介绍大家可以参考文章《LIN数据库文件LDF介绍及使用》。
Com 模块主要功能如下:
- 提供基于信号的发送机制;
- 提供不同的发送方式(例如:周期、事件);
- 对报文发送超时进行监测与处理;
- 提供发送状态通知机制;
- 提供基于信号的发送接口函数。
- 提供基于信号的接收机制;
- 对报文接收超时进行监测与处理;
- 提供接收状态通知机制;
- 提供基于信号的接收接口函数。
- 支持信号路由功能;
- 支持信号滤波功能;
- 支持长报文(TP)传输;
- 支持动态信号收发
报文的发送
首先得强调一点就是信号和报文(PDU)的关系是一条报文会包含一个或者多个消息。 报文的发送则是由报文传输特性及信号传输特性共同决定的。首先得了解一下报文和信号各有哪些传输特性。
报文的传输特性包括:
- NONE:该类型的报文不会被发送;
- PERIODIC:该类型报文的发送方式为周期发送,不会随发送信号的传输特性改变而改变;
- DIRECT:该类型报文的发送方式完全由发送信号的传输特性决定;
- MIXED:该类型报文的发送方式由报文的传输特性及发送信号的传输特性综合决定。
信号的传输特性包括:
- PENDING:该类型信号的发送,是依据其所在报文的发送类型;
- TRIGGERED_WITHOUT_REPETITION:每当写该信号时,触发一次发送;
- TRIGGERED:每当写该信号时,触发多次发送;
- TRIGGERED_ON_CHANGE_WITHOUT_REPETITION:每当该信号的值发送变化时,触发一次发送;
- TRIGGERED_ON_CHANGE:每当该信号的值发送变化时,触发多次发送。
[!tip]
注1:触发多次发送时,发送次数由该信号所在报文的 ComTxModeNumberOfRepetitions属性决定。多次发送的周期,由该信号所在报文的 ComTxModeRepetitionPeriod 属性决定。
注 2:触发发送时,并非立即发送,而是需要等到下一个 Com_MainFunctionTx 的调度周期,才开始进行发送。
所以两者结合后,导致最终一条报文最终传输特性为:

[!tip]
注 3:DBC和LDF对信号和报文属性的定义和AUTOSAR中定义报文属性是有点不同的,当使用AUTOSAR工具导入DBC/LDF文件时,会根据规则转换。
另外在Com模块中,还可以给每一条报文配置额外的发送模式,也就是说一条报文可以拥有两种发送规则,可改变的规则包括:
- 报文传输特性;报文重复发送周期;
- 报文重复发送次数;
- 报文发送首次偏移时间;
- 报文周期时间。
当上层程序发起信号的发送时,Com模块将信号装进PDU里并发送的过程如下图所示:

- 首先上层的SWC通过RTE调用对应的Signal/Signal Group接口(Com_SendSignal/Com_SendSignalGroup)
- 请求信号发送,COM层内部置位对应信号或者信号组的Update Bits;
- 信号的长度超过一个Byte时,需要进行字节序的转换(即:大端模式或者小端模式);
- 随后添加信号的发送属性以及选择报文的发送模式,最后会调用PduR的接口(PduR_ComTransmit/Com_TriggerTransmit)触发报文的发送;
- 在整个发送过程中Com会对每一条报文的发送进行定时监控;还可以为每一个PDU配置一个"I-PDU Callout",可以在PDU发送请求之前,在此Callout中实现一些特殊功能。
报文的接收
Com 在接收到报文后,将按照如下流程进行处理,如下图所示:

- 首先PduR模块通过Com_RxIndication通知Com接收到PDU后
- Com模块会复位PDU对应的超时定时器Deadline Monitor Timer,如果如果配置了回调函数,则调用Com_cbkRxTout(),如有配置的I-PDU Callout,调用对应的用户接口;
- 如果一个Signal或者Signal Group配置了Update Bits。
- 只有Update Bits置位(=1)时,此Signal或者Signal Group才会进一步的处理,处理包括:
- 过滤
- 通知
- 信号路由
- 字节序转换等
- 如果Signal的Update Bits未有置位,当上层再次读取该信号值时,可以使用该信号的上次历史值或者初始值;
- 只有Update Bits置位(=1)时,此Signal或者Signal Group才会进一步的处理,处理包括:
路由信号
如果用户配置了信号路由,Com 在接收到源信号后,将自动将该信号的值,写入目的发送信号,完成信号路由操作。信号路由只是对信号值的路由,不影响信号的接收和发送方式,这主要包括:
- 源信号需要通过正常的接收处理流程,如无效值、接收滤波等,才能进行路由;
- 发送端信号值更新后,需要按照发送报文的发送方式进行发送。
信号的路由过程如下图所示:

其实过程也很简单,收到信号后,会立马把该信号的值更新到发送PDU中去发送出去。
滤波
Com模式提供的滤波方式包括:
| 滤波方式 | 描述 |
|---|---|
| ALWAYS | 全部通过 |
| NEVER | 屏蔽所有信号 |
| MASKED_NEW_EQUALS_X | 满足下述条件通过,value&Mask = X |
| MASKED_NEW_DIFFERS_X | 满足下述条件通过,value&Mask != X |
| MASKED_NEW_DIFFERS_MASKED_OLD | 满足下述条件通过,newvalue&Mask != oldvalue&Mask |
| NEW_IS_WITHIN | 通过信号值在某个范围值内的信号 |
| NEW_IS_OUTSIDE | 通过信号值超出某个范围值内的信号 |
| ONE_EVERY_N | 信号每 N 次滤波,通过一次 |
TP报文
需要使用传输协议进行传输的报文(通常是因为报文长度较大,单帧无法进行传输),需要配置为 TP 报文。对 COM 模块而言,TP 报文与非 TP 报文的区别主要包括:
- 与 PDUR 交互的接口不同;
- 由于 TP 报文需要多个周期才能发送成功,为保证数据一致性,TP 报文发送过程中,禁止更新发送信号,直至报文发送成功或超时;
- 多帧报文在接收过程中,可能出现丢帧、超时或其他错误情况,在接收错误的情况下,COM 将丢弃未成功接收的报文,并且调用 Com_CbkInv 通知用户。
功能组
用户可以对不同的 PDU 进行分组,位于同一组内的 PDU,可以同步的进行启动或停止的操作。PDU 组的功能默认是开启的,默认的分组规则是,每个通道单独分组,每个通道分为发送和接收两个功能组。
位于功能组内的报文,在初始化后,处于关闭的状态。用户需要调用相关接口,启动该组后,组内的报文才可以正常的收发。不属于任何功能组的报文,在初始化后,处于开启的状态,可以正常进行收发。
同一报文可以属于多个功能组,称为关联组。开启一个功能组时,只开启属于本功能组的所有报文。关闭一个组时,如果该功能组有关联组,则会关闭本组及所有关联组内的所有报文。不同的功能组也可以组成一个新的功能组,这称为多级的功能组。
超时监测
超时属性是属于信号属性,需要通过配置工具进行配置。但实际上,信号是不能单独进行传输的,必须以报文为单位进行传输,因此,COM 的超时监测实际是以报文为单位进行的。同一条报文中,不同信号可以配置不同超时值。报文的超时值等于信号中最小的超时值,报文中各信号的实际超时值等于报文的超时值。
发送超时是指从启动报文发送到发送确认之间的时间。如果信号的传输特性中配置了重发机制(Repetition),那么在发送超时的时间内,必须将全部重发次数发完,否则 COM 会上报发送超时(在这里简单得解释一下Repetition机制,就是有的事件型报文触发之后可以配置它在短时间内发送多次,然后这里得超时时间则指的是在超时时间内必须将多次全部发送完成)。超时后,未完成的发送将被丢弃。COM 监测到发送超时事件后,会调用 Com_CbkTxTOut 通知用户。
接收超时是指在规定时间内没有接收到报文。接收超时有两种超时:1. 首次接收超时(ComFirstTimeout),仅在下列场景使用: 初始化后;报文所在的功能组重新启动; 报文所在的功能组的接收超时重新启动。2. 正常接收超时(ComTimeout),正常情况下的超时监测。首次超时时间一般设置的比较长,因为初始化时,总线上各控制器的初始化时间可能比较长。COM 监测到接收超时事件后,会调用 Com_CbkRxTOut 通知用户,并会根据配置,执行不同的动作:1. REPLACE:使用初始值替换当前的信号值;2. NONE:无特殊动作。
最小延迟时间
为防止总线的负载率过高,用户可以为发送的 Pdu 配置最小延迟时间。配置了最小延迟时间后,在该时间内,最多只能有 1 帧报文发送到总线上。如果在该时间内有多于 1 次发送请求,则后续的请求会被退后到最小延迟时间之后发送。该时间仅对相同 PduId 的发送报文起作用,不同 PduId 的报文之间无最小延迟时间的限制。
Dcm
[!tip]
Dcm 模块为诊断服务提供标准的函数接口,在控制器产品开发、制造和售后服务期间,用户可以通过外部诊断工具访问 Dcm 模块实现对控制器进行刷新、故障诊断等操作。说白就是Dcm是AUTOSAR架构对UDS协议的具体实现,Dcm模块是PduR模块的上层模块,当PduR接收到下层传输模块的UDS PDU后,就会将其路由发送到Dcm模块,同理,PduR模块也会将Dcm模块下发的PDU路由到对应的传输层模块。
为实现 Dcm 功能,AUTOSAR 规范根据诊断服务执行的过程,将 Dcm 模块分为 3个子模块,分别是:
- DSL(Diagnostic Session Layer)实现诊断数据的接收和发送、管理诊断时间参数、管理诊断会话状态和安全等级;
- DSD(Diagnostic Service Dispatcher)检查诊断服务是否支持、管理从 DSP 子模块得到的诊断响应;
- DSP(Diagnostic Service Processing)执行诊断服务处理。

DSL:诊断服务层
DSL(Diagnostic Service Layer)做了下面几件事:
- 确定诊断数据请求和响应的数据流;
- 监控和确保诊断请求和响应的时序
- 管理诊断状态(特别是诊断会话和安全状态)
请求处理
- 当DcmDslProtocolRxPduId 开始接收新的诊断请求内容时,PduR模块通过调用Dcm_StartOfReception()指示DCM模块。它通知DCM模块要接收的数据大小,并提供第一帧或单个帧的数据,并允许DCM在数据大小超出其缓冲区大小或请求的服务不可用时拒绝接收。
- 使用Dcm_CopyRxData函数将数据从提供的缓冲区复制到DCM缓冲区。
- 如果诊断请求的接收完成(当Dcm_StartOfReception成功时),PduR模块将调用Dcm_TpRxIndication()给DCM模块一个接收指示。
- 当地址信息由Dcm_StartofReception()通过DcmRxPdu提供给DCM时,DCM应该能够使用通用连接。这个地址必须要存储并且用于响应和检测来自同tester的请求。
- DSL子模块在调用Dcm_TpRxIndication函数后,如果返回Result = E_OK,才会将接收到的数据转发给DSD子模块。
- 一旦收到请求消息(当Dcm_TpRxIndication函数返回E_OK之后,直到调用Dcm_TpTxConfirmation()来获取相关的TxDcmPduld), DSL子模块将阻塞相应的DcmPduld。在处理此请求期间,不能接收相同DcmDslConnection的其他请求(例如,可以通过OBD会话结束增强会话),直到发送相应的响应消息并再次释放dcmPduld(并发的testpresent请求除外)。
对于不同的诊断通信应用程序,允许有不同的dcmPduld。例如:
-
OBD DcmRxPduld:用于接收OBD请求
OBD DcmTxPduld:用于传输OBD响应;
-
UDS phys DcmRxPduld:用于接收UDS物理地址请求;
UDS功能DcmRxPduld:用于接收UDS功能寻址请求;
UDS DcmTxPduld:用于传输UDS响应。
每个DcmRxPduld配置地址类型(物理/功能寻址)。每个DcmRxPduld的配置是可能的,因为对于功能和物理接收,总是有不同的DcmRxPduld值,独立于传输层的寻址格式(扩展寻址,正常寻址)。
[!tip]
当ECU接收到会话保持请求(SID: 0x3E Sub: 0x80),不会发到DSP。
响应处理
响应处理实际上接收DSP的数据,调用发送触发PduR的数据发送;
- 当DcmDslMainConnection的诊断响应准备好时,DSL子模块通过PduR_DcmTransmit函数向PduR发送诊断响应,其中Pduld参数为DcmDsIProtocolTxPduRef。
- 在周期性传输的情况下,Dcm应提供调用PduR_DcmTransmit()获取完整的有效负载数据(不使用Dcm_CopyTxData函数)
- 在周期性传输的情况下,使用Dcm_TxConfirmation()调用Dcm进行周期性传输,从而获取传输结果
- 响应与DcmTxPduld一起发送,它在DCM模块配置中链接到DcmRxPduld,即接收请求的ID(参见配置参数DcmDsIProtocolTx)。
- 在PduR_DcmTransmit()中,仅给PduR模块提供长度信息和一般连接的寻址信息。在DCM模块成功调用PduR_DcmTransmit()后,PduR模块将调用Dcm_CopyTxData()要求DCM模块提供要传输的数据,并在完整的PDU成功传输或发生错误后调用Dcm_TpTxConfirmation()。
- 如果DSL子模块在成功发送完整的DCM PDU后收到确认消息,或者调用Dcm_TpTxConfirmation()发生错误,则DSL子模块应将此确认消息转发给DSD子模块。如果传输失败(PduR_DcmTransmit()请求失败)或错误确认(Dcm_TpTxConfirmation()带有错误)时,DSD子模块不得重复诊断响应传输。
[!note]
注意:只有当PduR_DcmTransmit成功时才需要Dcm_TpTxConfirmation。如果DcmDsIProtocolTx的Multiplicity设置为“0”,Dcm将处理接收到的诊断请求而不发送响应。
在DSL中支持多种服务:
-
支持周期性传输:对应的服务ReadDataByPeriodicIdentifier (0x2A),该服务用于向由一个或多个periodicDataIdentifiers标识的ECU请求定期传输数据记录值。
DCM模块应使用单独的协议和可配置大小的单独缓冲区发送周期性传输的响应。DcmDslPeriodicTransmissionConRef配置参数允许将用于接收周期性传输请求/发送周期性传输响应的协议链接到用于传输周期性传输消息的协议。注意,可以将多个DcmTxPdulds分配给周期性传输协议。根据通信方式的不同,DCM模块有以下几个限制:
- 周期传输通信只能在完全通信模式下进行。
- 在未处于完全通信模式时可能发生周期性传输事件。因此存在以下要求:
- DCM模块丢弃全通信模式旁边的周期性传输事件,不将其排队传输。
- 周期传输事件不激活完全通信模式。
-
支持ResponseOnEvent (ROE) 传输:对应的UDS服务ResponseOnEvent (0x86), 通过该服务。测试人员可以请求ECU启动或停止传输由指定事件发起的响应。当注册一个事件进行传输时,测试者也指定相应的服务来响应(例如:UDS service ReadDataByIdentifier 0x22)。
-
支持分段响应: 在某些情况下,例如在例程执行的情况下,应用程序需要立即请求一个NRC 0x78(响应等待),该请求应立即发送,而不是仅仅在到达响应时间之前(P2ServerMax分别为P2*ServerMax)。当Dcm模块调用一个操作并得到一个错误状态DCM_E_FORCE_RCRRP时,DSL子模块将触发NRC 0x78(响应等待)的负响应传输。这个响应需要从一个单独的缓冲区发送,以避免覆盖正在进行的请求处理。
DcmDslProtocolMaximumResponseSize 仅当 DcmPagedBufferEnabled 设置为 TRUE时才存在
- 当DcmPagedBufferEnabled=TRUE时,如果生成的响应长度大于DcmDsIProtocolMaximumResponseSize,则Dcm响应NRC 0x14 (响应长度过长)。
- 当DcmPagedBufferEnabled == FALSE时,并且生成的响应大于Dcm_MsgContextType结构元素的resMaxDataLen,则Dcm响应NRC 0x14().
使用分页缓冲处理,ECU不会要求提供与最大响应长度一样大的缓冲区。注意:
- 分页缓冲区处理仅用于发送-不支持接收。页缓冲区处理不适用于应用程序(仅在dcm内部使用)。
- Dcm应提供TP请求的正确数据量,如果请求的数据量不可用,则返回bufreqe_busy。
注意:如果请求的数据量不可用,Dcm应该立即填满分页缓冲区。
-
支持由应用程序触发的 ResponsePending 响应:当需要响应诊断请求时,DSL模块通过调用PduR_DcmTransimit()和Dcm_CopyTxData()将数据传递至PDUR模块,其中PduR_DcmTransimit()函数只是传递长度信息、地址信息,数据是通过Dcm_CopyTxData()函数传递至PDUR模块,当数据传输成功后,PDUR模块通过Dcm_TpTxConfirmation()函数告知DCM数据接收成功。PDUR会将数据诊断请求数据从上层的Buffer中Copy到诊断的接收Buffer中,DSD会从此Buffer中取出数据进行处理。
-
支持等待响应:上位机发送诊断请求后会要求ECU在一个最大响应时间(一般是50ms)内发出响应报文,但是对于一些请求的处理,ECU内部会耗时比较长(比如0x2E写NVM的请求),来不及在规定时间发出响应。这个时候ECU可以发送0x78(Pending)的否定响应吗来通知上位机ECU内部繁忙(Busy),需要上位机等待(Pending,一版Pending时间可以设置为1秒)。上位机收到0x78(Pending)的否定响应码后就会等待,直到ECU发出积极响应或者Pending时间超时。这个发送Bussy响应来保证诊断时序的功能由DSL模块实现。
如果应用程序(或DSP子模块)能够执行请求的诊断任务,但需要额外的时间来完成任务并准备响应,则DSL子模块应在达到响应时间(DcmDspSessionP2ServerMax -DcmTimStrP2ServerAdjust)时发送NRC 0x78(响应等待)的负响应。DSL子模块应该从一个单独的缓冲区发送负面响应。这是为了避免覆盖正在进行的请求处理,
例如,应用程序已经在诊断缓冲区中准备了响应内容。对于一个诊断请求,带有NRC 0x78(响应挂起)的否定响应的数量受到配置参数的限制DcmDsIDiagRespMaxNumRespPend。这避免了应用程序中的死锁。
如果请求的诊断任务的否定响应数达到配置参数DcmDsIDiagRespMaxNumRespPend中定义的值,Dcm模块将停止处理活动诊断请求,并通过设置活动端口接口的OpStatus参数通知应用程序或BsW(如果此诊断任务意味着调用SW-C接口或BsW接口)。到DCM_CANCEL,并发送带有NRC 0x10(一般拒绝)的否定回复。
安全管理
在安全管理模块中,有以下功能:
- 管理安全级别
- 处理Key和Seed
DSL提供Dcm_GetSecurityLevel()、DslInternal_SetSecurityLevel()两个函数分别用于获取当前的安全等级和设置安全等级。
对于配置层面而言,DSL菜单主要是配置诊断帧,包括物理寻址和功能寻址,单次通信的最大Buffer,以及时间参数,包括回复0x78的时间和为了防止诊断服务异常,允许0x78的最大次数等。
在 Dcm 初始化期间,安全级别设置为值 0x00 (DCM_SEC_LEV_LOCKED), 在满足下列条件其中之一时,DSL会将安全级别重置为值 0x00:
- 从任意非默认会话切换到另一个非默认会话(包括当前已激活的会话)。
- 从任意非默认会话切换到默认会话(当使用UDS 的0x10服务或 S3 Server 超时执行)
[!note]
一次只能激活一个安全级别
每次安全级别更改时,Dcm 应更新 ModeDeclarationGroup 的DcmSecurityAccess
DcmDspSecurityResetAttemptCounterOnTimeout参数应该在仅当 DcmDspSecurityRow 的 DcmDspSecurityAttemptCounterEnabled 设置为 TRUE 时,才应存在。
会话管理
会话(session)一般有三种:
- 缺省会话(0x00, Default session)
- 编程会话(0x01, Programming session)
- 扩展会话(0x02Extended session)
DCM的会话管理有以下几个功能:
- 管理会话状态处理当前激活的Session以及设置新的Sesstion
- 管理权限状态分为权限模式和默认的模式
- 跟踪活动的非默认会话
- 允许修改时间。
DSL子模块保存当前活动会话的状态,为了访问这个变量,DSL子模块提供了以下接口:
- 获取当前活动会话:Dcm_GetSesCtrlType ()
- 设置会话:DslInternal_SetSesCtrlType()
初始化DCM时,会话状态设置为0x01(“DefaultSession”)。调用Dcm_ResetToDefaultSession()允许应用程序将当前会话重置为默认会话,并调用ModeDeclarationGroupPrototype DcmDiagnosticSessionControl的模式切换SchM_Switch__DcmDiagnosticSessionControl(RTE_MODE_DcmDiagnostic)SessionControl_DEFAULT_SESSION)。示例:超出速度限制时自动终止扩展诊断会话。
[!note]
每种会话下可以进行的诊断服务不同,根据实际需求由OEM自己定义。一般来说诊断(UDS)刷写功能需要在编程会话下进行,涉及到NVM关键存储数据的写功能需要在扩展会话下进行。根据实际需求可以自己定义会话,比如定义0x60(EOL session)专门用于EOL工厂下线处理。
会话保持将在一个单独的DcmRxPduld (UDS功能DcmRxPduld)上接收,该DcmRxPduld与物理请求属于同一个DcmDslConnection。在这种情况下,使用了未显式配置的dcm内部接收缓冲区。由于这个原因,函数testpresent(并且只有没有响应的函数testpresent)以以下方式处理:
[!tip]
当PduR模块调用Dcm_TpRxIndication并返回E_OK时,如果请求是“testpresent”命令,且“抑制正响应位”设置为TRUE ,则DSL子模块将重置会话超时定时器(S3Server),并且不会将此请求转发给DSD。
由于绕过了DSL子模块中的功能“testpresent”,Dcm模块能够毫无延迟地接收和处理下一个物理请求。
诊断协议处理
- 处理不同的诊断协议
- 处理设置诊断协议服务Table, 根据UDS或者OBD链接到不同的诊断协议
- 设置不同服务协议的优先级
- 支持优先级抢占机制
- 并行处理OBD和UDS协议, 可以忽略优先级和抢占机制
管理资源
给服务分配对应的Buffer,
- 在Dcm模块中只允许使用和分配一个诊断缓冲区,这个缓冲区随后用于处理诊断请求和响应
- NRC 0x78 (Response pending)响应的输出是通过一个单独的缓冲区完成的
- 支持分页缓冲处理
通信模式处理
DCM模块和ComM模块的交互由DSL子模块完成。ComM模块把每个通信通道(channel)的当前通信状态(No-com, Full-com, Silent-com)通知给Dcm模块。Dcm模块的诊断功能将会调用ComM模块的接口功能可能会阻止Ecu进入shutdown模式(ActiveDiagnostic ==’DCM_COMM_ACTIVE’时ECU必须保持唤醒状态,也就是不允许 进入shutdown/sleep)。
应用程序可以调用Xxx_SetActiveDiagnostic()接口通知Dcm模块ActiveDiagnostic的当前状态
- 处理通信要求(Full/Silent/No):ComM会通知DCM当前的通道, DCM会进行模式的请求, 避免通信进入Sleep;在Silent和NO下, DCM禁止通信
- No Communication:ComM模块调用 Dcm_ComM_NoComModeEntered接口通知Dcm模块通信关闭。Dcm模块收到通知后就会Disable所有的诊断接收/传输。
- Silent Communication:ComM模块调用 Dcm_ComM_SilentComModeEntered接口通知Dcm模块通信静默。Dcm模块收到通知后就会Disable所有的诊断传输。
- Full Communication:ComM模块调用 Dcm_ComM_FullComModeEntered接口通知Dcm模块通信静默。Dcm模块收到通知后就会Enable所有的诊断接收/传输。
- 指示活动/非活动诊断
- 启用/禁用所有类型的诊断传输
在DSL里面可以配置多路诊断通道,假设诊断ID有2个以上,通过DcmDslProtocolRows容器实现。
DSD:诊断调度服务
DSD(Diagnostic Service Dispatche)子模块负责检查传入诊断请求的有效性(诊断会话/安全访问级别/应用程序权限的验证),并跟踪服务请求执行的进度。
DSD和DSL的交互为:
| 描述 | 解释 |
|---|---|
| 双向 | 诊断消息的交换 (接收/发送) |
| DSD到DSL | 获取最新的诊断会话和安全级别 |
| DSL 到DSD | 诊断报文传输确认 |
DSD和DSP的交互为:
| 描述 | 解释 |
|---|---|
| DSD 到DSP | 委托诊断处理 ·确认传输消息 |
| DSP 到DSD | 处理结束的信号 |
检查
DSD模块会检查诊断服务标识和适配诊断消息:
- DSD接收来自DSL的数据, 根据具体的配置参数决定接收到的信号是否在DCM中进行处理
- 基于ID进行识别
- 可以选择诊断的ID Table
- 对于不支持的ID进行Negative 响应
-
当DSL接收到新的诊断请求,DSL通过内部接口通知DSD。DSD调用Dcm_GetSesCtrlType()、Dcm_GetSecurityLevel()获取当前的Session和安全等级,DSD通过检查以上的参数会响应不同的数据:
-
DSD模块会在当前Session的“Service Identifier Table”检查诊断请求SID是否在其中,如果不在table中,DSD会发送NRC 0x7F。
如果配置DcmRespondAllRequest=FALSE,那么当DCM模块收到包含0x40到0x7F或0xC0到0xFF范围内的服务ID的诊断请求,DCM将不响应这样的请求。因为此范围的SID在 ISO 14229-1(UDS)标准中定义是响应 SID 范围。
-
如果诊断服务支持,但当前Session不支持该子服务,DSD会发送NRC 0x7E。
-
然后检查当前安全等级是否满足条件,如果当前安全等级不支持该诊断请求,DSD会发送NRC 0x33。
-
最后检查数据的长度。
-
-
当DSP模块完成诊断请求处理后,DSD负责将整理响应数据发送至DSL。
- DSD模块将服务标识符(SID)(如果是负反馈,则为0x7F)和响应的数据流添加至“Dcm_MsgContextType”。
- 然后DSD将其传送至缓冲区,并在缓冲区的第一个字节添加SID。
举个例子:写VIN号
- DSL子模块接收到一条新的诊断消息。诊断信息WriteDataByldentifier = 0x2E,0xF1,0x90,0x57,0x30,0x4C,0x30,0x30,0x30,0x30,0x34,0x33,0x4D,0x42,0x35,0x34,0x31,0x33,0x32,0x36
- DSL子模块向DSD子模块指示具有“数据指示”功能的新诊断消息。在诊断消息缓冲区中存储诊断消息(buffer = 0x2E,0xF1,0x90,…)。
- DSD子模块使用传入诊断消息上确定的服务标识符(缓冲区0x2E的第一个字节)对受支持的服务执行检查。
- 传入的诊断消息存储在DCM变量中Dcm MsgContextType。
DcmDsdSidTabServiceld中配置的服务标识符的Id在一个DcmDsdServiceTable中必须是唯一的。
验证
DSD子模块只有在通过以下六项验证后才会接受服务:
- 厂商权限验证(厂商接口inctnptn的调用)
- SID的验证
- 诊断会话的验证
- 服务安全访问级别的验证
- 供应商权限验证(调用供应商接口指示操作)
- 验证服务id的Mode规则
[!note]
当前会话下服务不支持响应0x7F(注意区分0x11),例如10 03下不支持2E一样,当前请求子服务不支持响应0x7E(注意区分0x12),例如10 03下支持0x2E,但是不支持0x2E F1 89这样的F1 89子服务。一定要注意区分。校验安全等级,一般就是在某些服务下校验0x27是否能正常通过。
并且DSD还会检查格式与子服务:
- 服务权限(0x29服务可以改变权限)
- 诊断的Session(0x10服务实现不同的Session)
- Security Access Level(0x27)
- 服务的关联和依赖
响应
响应主要有以下类型:
- Positive的响应
- Negative的响应
- 抑制响应
详细为:
-
接收请求消息并发送积极响应消息:服务端接收诊断请求消息。DSD子模块确保请求消息的有效性,将该请求转发到DSP子模块中相应的服务处理程序中。当服务处理函数完成所有数据处理动作后,触发DSD子模块发送响应消息。
- 如果DSP作为请求指示函数的一部分,立即处理服务,则DSP可以触发该指示函数内部的传输(“同步”)。
- 如果处理需要较长的时间(例如等待EEPROM驱动程序),则数据处理器推迟一些处理(“异步”–使用pending)。响应挂起机制由DSL子模块涵盖。数据处理器显式地触发传输,但是是从数据处理器的上下文中触发的。一旦收到请求消息,相应的DcmPduld就会被DSL子模块阻塞。在处理此请求期间,不能接收其他相同协议类型的请求(例如,可以通过OBD会话结束增强会话),直到发送相应的响应消息并再次释放DcmPduld。
-
接收请求消息并抑制积极响应:这是前一个用例的子用例。在UDS协议中,可以通过在请求消息中设置一个特殊的位来抑制正响应。这种特殊的抑制处理完全在DSD子模块中执行。
-
接收请求消息并抑制负面响应:在功能性寻址的情况下,DSD子模块应抑制NRC 0x11, 0x12, 0x31, 0x7E和0x7F的负响应.
-
接收请求消息并发送否定响应消息:拒绝请求消息和发送否定响应有许多不同的原因。如果诊断请求无效,或者在当前会话中可能不会执行请求,则DSD子模块将拒绝处理并返回否定响应。但是拒绝执行格式良好的请求消息甚至有很多原因,例如,如果ECU或系统状态不允许执行。在这种情况下,DSP子模块将触发一个否定响应,包括NRC提供该请求被拒绝的额外信息。
如果请求由多个参数组成(例如,一个有多个标识符要读取的UDS Service ReadDataByldentifier (0x22)请求),则每个参数被单独处理。每个参数都会返回一个错误。
如果至少有一个参数被成功处理,这种请求将返回一个积极的响应。
-
发送一个积极的响应消息,没有相应的请求:UDS协议中有两种服务,对一个请求发送多个响应。通常,一个服务用于启用(和禁用)由事件或时间触发的另一个服务的传输,该服务再次由ECU发送,而不需要相应的请求.UDS Service readdatabyperiodicentifier (0x2A)。该服务允许客户端请求定期传输由一个或多个periodicDataldentifiers标识的服务器的数据记录值。类型1 = DcmTxPduld上的USDT消息已用于正常诊断响应(仅限单帧);类型2=单独的DcmTxPduld上的udt消息。对于类型1,传出消息必须与具有更高优先级的“正常传出消息”同步。ResponseOnEvent (Ox86)。此服务请求服务器启动或停止对指定事件的响应传输。方式1 = DcmTxPduld上的USDT消息已用于正常诊断响应;方式2 =在单独的DcmTxPduld上发送USDT消息。对于方式1,传出消息必须与具有更高优先级的“正常传出消息”同步。
这种处理特别由DSL子模块控制。然而,DSD子模块还提供了在没有相应请求的情况下生成响应的可能性。
-
分段反应:在诊断协议中,一些服务允许交换大量的数据,例如UDS Service ReadDTCInformation (0x19)和UDS Service传输数据 (0x36)。在传统方法中,ECU内部缓冲区必须足够大,以保存要交换的最长数据消息(最坏情况),并且在传输开始之前填满整个缓冲区。ECU中的RAM存储器通常是一个关键资源,特别是在较小的微处理器中。在一种更节省内存的方法中,缓冲区只被部分填充,部分传输,然后部分重新填充,以此类推。这种分页机制只需要显著减少的内存量,但需要定义良好的缓冲区重新填充反应时间。用户可以决定是使用“线性缓冲区”还是分页缓冲区进行诊断。
[!note]
可能出现的NRC为:
- 0x11 (Service not supported)
- 0x12(SubFunction not supported)
- 0x31(Request out of range)
- 0x7E (Subfunction not supported in active session)
- 0x7F (Service not supported in active session)
响应过程为:
- DSD子模块将诊断(响应)消息(正面或负面响应)转发给DSL子模块。
- DSL子模块应通过执行DSL传输功能将诊断(响应)消息(正面或负面响应)进一步转发到PduR模块。
- DSL子模块在转发数据时将收到PduR模块的确认。
- DSL子模块将从PduR模块接收到的确认信息转发给DSD子模块。
- DSD子模块应通过内部函数DspInternal_DcmConfirmation()将确认转发给DSP子模块。
- 如果不发送诊断(响应)消息(响应抑制),则DSL子模块不发送任何响应。
- 在这种情况下,没有数据确认从DSL子模块发送到DSD子模块,但DSD子模块仍将调用内部函数DspInternal_DcmConfirmation ()。
DSP:诊断服务处理
Diagnostic Service Processing:处理实际的诊断请求。当接收到来自DSD子模块的函数调用要求DSP子模块处理诊断服务请求时, DSP始终执行以下基本处理步骤:
-
分析收到的请求消息
- 分析收到的 Service‑ID、子功能码以及报文长度、结构等信息。
- 检查格式是否符合 UDS/OBD 规范,若不符合则产生负响应 NRC 0x13(“Message length or format incorrect”)
-
检查格式以及是否支持寻址的子功能
- 判断当前诊断会话、权限、安全等级是否允许该服务;若不允许则返回 NRC 0x10(“General reject”)或其他对应的 NRC
-
在 DEM、 SW-C 或其他 BSW 模块上获取数据或执行所需的函数调用
- 与 DEM(Diagnostic Event Manager)、其他 BSW 模块或应用层 SW‑C 交互,读取故障码、执行读/写 DID、进行编程、访问安全访问等功能。
- 若使用分页缓冲区机制,DSP 必须先计算整体响应长度,再把数据分段交给 DSD/DSL 处理。
-
服务响应
- 将响应 Service‑ID(原 Service‑ID + 0x40)以及相应的数据字段组织成完整的响应帧。
- 对于负响应,按照 UDS 规范生成 0x7F 前缀 + 原 Service‑ID + NRC 码
[!note]
在DSP和bootloader交互的时,如果满足所有先决条件并假设’suppressPosRspMsgIndicationBit标志设置为’false’,则已经确定了跳转到引导加载程序的4个不同用例:
- 应用程序立即发送一个最终的积极响应,然后跳转到引导加载程序
- 应用程序首先发送一个NRC 0x78响应,然后是最终的积极响应,然后跳转到引导加载程序
- 应用程序立即跳转到引导加载程序,引导加载程序发送最终的积极响应
- 应用程序首先发送一个NRC 0x78响应,然后跳转到引导加载程序,引导加载程序发送最终的积极响应
注意:如果’suppressPosRspMsgIndicationBit’标志被设置为’true’,用例’1’并且用例“3”不会发出积极响应。
在接收服务诊断sessioncontrol时,如果提供的会话用于跳转到OEM引导加载程序(参数DcmDspSessionForBoot设置为DCM_OEM_BOOT或DCM_OEM_BOOT_RESPAPP),Dcm应通过触发ModeDeclarationGroupPrototype DcmEcuReset的模式切换来准备跳转到OEM引导加载程序。
注意:通过这种模式切换,DCM通知BswM准备跳转到引导加载程序。
在DCM初始化时,DCM应该调用Dcm_GetProgConditions()来知道初始化是否是从引导加载程序/ ECUReset跳转的结果。注意:当调用Dcm_Init时,确保Dcm_ProgConditionsType中包含的数据有效是软件集成商的责任。例如,如果此数据存储在非易失性存储器中,则在ECU复位后可能需要一些时间才能使其可用。在设计ECU的启动过程时,必须考虑到这一点。
关联模块
- RTE: 接收诊断相关的数据处理诊断相关的通信服务,Dcm模块在完成诊断功能的时候需要通过RTE接口来读写/函数调用其他SWC的数据/服务。
- 如果Dcm模块无法直接处理诊断数据请求时,Dcm会把通过以下方式来转发请求并获得结果数据:
- 通过SW-C的port-interface。
- 通过直接调用BSW模块函数。
- BswM:接收DCM的状态变化进行模式模式管理,如果Dcm的初始化是从引导加载程序跳转的结果,则Dcm通知BswM应用程序已被更新(UDS的0x11服务)。Dcm还向BswM表示通信模式的改变(UDS的0x28服务)。
- SchM: 提供调度
- PduR: 提供收发诊断数据的路由
- ComM:处理诊断相关的通信请求,ComM模块提供了一些功能,如Dcm模块可以指示“活动”和“非活动”状态,以便进行诊断通信。Dcm模块提供了处理“Full-/ Silent-/ No-Communication”通信需求的功能。此外,如果ComM模块要求,Dcm模块提供启用和禁用诊断通信的功能。(UDS的0x28服务)
- NvM: 存储诊断数据
- DEM: 处理诊断事件,DEM模块提供检索与故障内存相关的所有信息的功能,以便Dcm模块能够通过从故障内存中读取数据来响应测试者的请求。通俗的讲就是Dcm能够读取Dem记录的DTC信息
- EcuM: 诊断相关的唤醒以及模式切换
- PDUR:PduR模块提供诊断数据的发送和接收功能。PduR模块接收和发送诊断数据。PduR为Dcm模块提供一个与具体通信协议无关的接口。
Dem
Dem(Diagnostic Event Manager,诊断事件管理), 用来记录和存储诊断事件的,将这些诊断事件及相关信息(冻结帧及扩展数据)记录到EEPROM。简单说其功能是:
- 故障事件确认前的故障消抖
- 故障事件确认时的故障数据存储
- 故障发生后的故障老化
- 故障替代(AUTOSAR的故障存储策略)
DEM模块相关的标准主要包括两部分:ISO 14229(UDS,车身域诊断遵循的主要标准)和ISO 15031(OBD,该标准制定较早,主要针对排放相关的诊断)。
主要诊断数据为:
- DTC
- 扩展数据
- 冻结帧
Dem只要牵涉两个服务:
- 读取DTC(0x19)
- 清除DTC(0x14)
术语介绍
| 术语名称 | 英文名称 | 定义/说明 |
|---|---|---|
| 操作周期 | Operation Cycle | 定义要运行的检测的开始和结束条件。开始时启动故障检测,结束时停止检测。车身与底盘由OEM或供应商确定(如下电、休眠唤醒等),动力域存在其他标准规定。 |
| 监控周期 | Monitoring Cycle | 检测时存在一系列条件,并非操作周期开始即检测错误,可分为周期型(Period)或事件型(Event)。需满足特定条件(如灯负载HSD开路故障需在输出打开时检测电流判断)。 |
| 确认阈值 | Confirmation Threshold | 确认故障持续存在的Operation Cycle数,达到后将其认定为历史DTC,在老化(aging)或手动清除前,confirmed DTC状态位一直存储在EEPROM中。 |
| 老化计数 | Aging Counter | 连续报告无故障的Operation Cycle数。AgingCounter也就是处于老化中DTC的计数。当一个OpreationCycle没有检测到testFailed,AgingCounter就会自加1,同时DTC Status的BIT就会清0。当AgingCounter计数达到一定的阈值后,此故障已经完成了老化,可以自愈。同时DTC Status的BIT3清0。 |
| 老化阈值 | Aging Threshold | 当Aging Counter达到此次数后,DTC的Confirmed状态位将被清除。 |
| 错误计数 | Fault Detection Counter (FDC) | 错误检测的计数,可设置步长(向上/向下计数,范围-128~127),用于过滤故障次数;支持jump down(检测通过时跳转至0或其他值并开始递减)。 |
| 扩展数据 | Extended | DTC状态Pending置位后保存在EEPROM中的数据,包含一系列DID(由BSW规定),常用数据包括:1. 错误计数(FDC,同上定义);2. 老化计数(连续无故障的Operation Cycle数,达到老化阈值后清除DTC的Confirmed状态)。 |
| 冻结帧 | Freeze Frame | 记录故障发生时的工况(Snapshot,由一系列DID组成),当DTC状态位Confirmed由0置为1时记录Snapshot,用于后续故障分析(如环境温度、ECU供电电压等)。 |
| 消抖 | Debounce | 防止故障误报的功能(14229-1规定),通过TripCounter判断故障是否确认:- TripCounter默认0,范围-128~127;- 持续testPassed时计数至-128,BIT4、BIT6由1置0;- 检测到testFailed时从>0开始计数(故障计数比正常快),计数至127时,BIT2与BIT3置位(确认故障)。 |
| 快照 | Snapshot | 一群DID数据的集合,每个DTC在Confirm时生成,存储关键数据至NVM,诊断仪可通过19服务读取具体数据。 |
DTC状态
DTC状态跟在DTC后面,DTC状态为1个字节,其8个bit位含义各不相同,如下表所示:
| bit位 | 名称 | 中文释义 | 含义 |
|---|---|---|---|
| 0 | testFailed | 测试失败 | 通常来说,ECU内部以循环的方式不断地针对预先定义好的错误路径进行测试,如果在最近的一次测试中,==在某个错误路径中发现了故障,则相应DTC的这一个状态位就 要被置1,表征出错。== 虽然此时DTC的testFailed位被置1,但是它不一定被ECU存储到非易失性存储中, 只有当pendingDTC或confirmedDTC被置1时DTC才会被存储。而pendingDTC或 confirmedDTC被置1的条件应该是检测到错误出现的次数或时间满足某个预定义的门限。当错误消失或者诊断仪执行了清除DTC指令时,testFailed会再次被置为0。 |
| 1 | testFailedThisOperationCycle | 本次操作周期测试失败 | ==该bit用于标识某个DTC在当前的operation cycle中是否出现过testFailed置1的情 况,即是否出现过错误。== operation cycle的起始点是ECU通过网络管理唤醒到ECU通过网络管理进入睡眠, 对于没有网络管理的ECU,这个起始点就是KL15通断。通过bit 0我们无法判断某个DTC 是否出现过,比如,当前testFailed=0,说明当前这个DTC没有出错,如果 testFailedThisOperationCycle=1的话,就说明这个DTC在当前这个operationcycle中 出过错,但是当前错误又消失了。 |
| 2 | pendingDTC | 待处理DTC | 根据规范的解释,==pendingDTC=1表示某个DTC在当前或者上一个operationcycle 中是否出现过。== pendingDTC位其实是位于testFailed和confirmedDTC之间的一个状态,有的DTC被确认的判定条件比较严苛,需要在多个operationcycle中出现才可以被判定为 confirmed的状态,此时就需要借助于pendingDTC位。 pendingDTC=1的时候,DTC就要被存储下来了,如果接下来的两个operation cycle中这个DTC都还存在,那么confirmedDTC就要置1了。如果当前operationcycle 中,故障发生,pendingDTC=1,但是在下一个operationcycle中,故障没有了, pendingDTC仍然为1,再下一个operationcycle中,故障仍然不存在,那么pending DTC就可以置0了。 |
| 3 | confirmedDTC | 已确认DTC | ==当confirmedDTC=1时,则说明某个DTC已经被存储到ECU的非易失性存储中==,说明这个DTC曾经满足了被confirmed的条件。 但是请注意,confirmedDTC=1时,并不意味着当前这个DTC仍然出错,如果confirmedDTC=1,但testFailed=0,则说明这个DTC表示的故障目前已经消失了。 将confirmedDTC重新置0的方法只有删除DTC,对应UDS的0x14服务服务。 |
| 4 | testNotCompletedSinceLastCear | 自上次清除后测试未完成 | 该bit用于标识自从上次调用了清理DTC的服务(UDS0x14服务)之后,==是否成功地执行了对某个DTC的测试==(不管测试结果是什么,只关心是否测了)。因为很多DTC的测试也是需要满足某些边界条件的,并不是ECU上电就一定会对DTC进行检测。 testNotCompletedSinceLastClear=1:自清理DTC后还没有完成过针对该DTC的测试。 testNotCompletedSinceLastClear=0:自清理DTC之后已经完成过针对该DTC的测试。 |
| 5 | testFailedSinceLastClear | 自上次清除后测试失败 | 这个位与bit1:testFailedThisOperationCycle有些类似,后者标识某个DTC在当前 的operationcycle中是否出现过testFailed置1的情况,而testFailedSinceLastClear标识的是在==上次执行过清理DTC之后某个DTC是否出过错==。 testFailedSinceLastClear=0,自从清理DTC之后该DTC没有出过错。 testFailedSinceLastClear=1,自从清理DTC之后该DTC出过至少一次错。 |
| 6 | testNotCompletedThisOperationCycle | 本次操作周期测试未完成 | 这个位与bit4:testNotCompletedSinceLastClear类似,后者标识自从上次调用了 清理DTC的服务之后,是否成功地执行了对某个DTC的测试。而该参数则标识==在当前 operationcycle中是否成功地执行了对某个DTC的测试==。 testNotCompletedThisOperationCycle=1:未成功完成过测试。 testNotCompletedThisOperationCycle=0:成功完成过测试。 |
| 7 | warningIndicatorRequested | 警告指示灯请求 | ==某些比较严重的DTC会与用户可见的警告指示相关联==,比如仪表上的报警灯,或者 是文字,或者是声音。这个warningIndicatorRequested就用于此类DTC。 warningIndicatorRequested=1:ECU请求激活警告指示。 warningIndicatorRequested=0:ECU不请求激活警告指示。 注意,如果这个DTC不支持警告指示,则这个位永远置0。 |
故障发生前后动作:
- 故障确认前:用户模块上报故障的Debounce防抖处理,确保对应故障不为误报故障。
- 故障确认时:故障事件确认时的故障数据存储至NVM,保证故障能长期保存。
- 故障确认后:故障的老化,替代,实现故障修复后,故障能被清除的功能。例如,仪表上的发动机故障灯,在发动机修好后一段时间后就会熄灭。
Event
DTC只是展示给诊断仪使用者,Event才是DTC状态实际操控者,同时Event也是诊断NVM数据存储实际控制者。DTC是系统层面对于故障的描述,而Event是软件层面对故障监控的最小单元。
例子:某个电机故障会由电压过高造成,但软件是无法直接识别该故障,软件只能监控是否产生了电压过高的时间Event,从而计算出是否产生DTC.
多个event可以mapping 同一个DTC;而同一个event不能mapping 多个DTC;
DTC可以直接可见,但Event需通过进一步手段才能看到,有时仅对ECU供应商可见;
- DTC代表某类event集中表现,而event则是某个DTC的具体实例;
- event的优先级决定了DTC的优先级;
- event之间的依赖关系决定了DTC的依赖关系;
EVENT上报方式为:周期调用Dem_SetEventStatus上报即为周期循环上报;当Event状态变化时,调用Dem_SetEventStatus上报为触发上报。
Tp
[!tip]
可参见http://main.weike-iot.com:2211/ebooks/can/车载诊断标准ISO_15765-2_cn.pdf
CanTp
CanTp位于CanIf与PDUR之间,主要目的是对大于8字节的CAN I-PDU,大于64字节的CANFD I-PDU进行分段与重组。位置如下图。

CAN接口(Canlf)提供了平等的机制来访问CAN总线通道,而不管它的位置(uC内部/外部)。从CAN控制器的位置(片上/板上)提取ECU硬件布局和CAN驱动程序的数量。由于CanTp只处理传输协议帧(即SF, FF, CF和FC pdu),根据N-PDU ID, CAN接口必须将I-PDU转发给CanTp或PduR。根据AUTOSAR的基本软件架构,CanTp提供以下服务:
- 传输方向的数据分割;
- 接收方向的数据重组;
- 数据流控制;
- 检测分段会话中的错误
- 传输取消
- 接收取消
名词缩写
前缀
| 前缀 | 描述 |
|---|---|
| I- | 关联AUTOSAR COM交互层 |
| L- | 关联Canlf,相当于逻辑链路层,上层是数据链路层下层为介质访问控制,介质 其实就是硬件抽象 |
| N- | 关联CanTp,可以认为是网络层,个人理解N代表多个 |
| ISO Layer | Layer Prefix | AUTOSAR Modules | PDUName | CAN/ TTCAN prefix | LIN prefix | FlexRay prefix |
|---|---|---|---|---|---|---|
| Layer 6 Presentation (Interaction) | I | COM,DCM | I-PDU | N/A | == | == |
| : | I | PDU router,PDU multiplexer | I-PDU | N/A | == | == |
| Layer 3 Network Layer | N | TP Layer | N-PDU | CAN SF CAN FF CAN CF CAN FC |
LIN SF LIN FF LIN CF LIN FC |
FR SF FR FF FR CF FR FC |
| Layer 2: Data LinkLayer | L | Driver,Interface | L-PDU | CAN | LIN | FR |
协议数据缩写
关联CanTp的缩写词, PDU是“协议数据单元”的缩写。PDU包含SDU和PCI。在传输端,PDU从上层传递到下层,下层将这个PDU解释为它的SDU。
| 缩写词 | 描述 |
|---|---|
| CAN L-SDU | 属于CanIf模块,与N-PDU类似 |
| CAN LSduId | CanIf内独一无二的ID,用于引用L-SDU的路由属性,因此为了通过API与CanIf交互,上层可以引用CAN L-SDU的结构体以此进行数据传递 |
| CAN N-PDU | 这是CANTP的PDU。它包含唯一标识符、数据长度和数据(协议控制信息加上整个N-SDU或其中的一部分)。 |
| CAN N-SDU | 这是CANTP的SDU。在AUTOSAR体系结构中,它是来自PDU路由器的一组数据。 |
| CAN N-SDU Info Structure | 这是一个CANTP内部常量结构,包含特定的CAN传输层信息,用于处理相关CAN N-SDU的发送、接收、分段和重组。 |
| I-PDU | 这是AUTOSAR COM模块的PDU |
| PDU | 在分层系统中,它指的是在给定层的协议中指定的数据单元。它包含该层(SDU)的用户数据以及可能的协议控制信息。X层的PDU为其下层X-1层的SDU,即(X)-PDU =(x-1)-SDU)。 |
| PduInfo Type | 该类型是指用于存储处理PDU(或SDU)收发基本信息的结构,即指向其在RAM中的有效载荷的指针及其长度(以字节为单位)。 |
| SDU | 在分层系统中,这是指由给定层的服务用户发送的一组数据,并将其传输给对等服务用户,同时保持语义不变。 |
[!tip]
对于PDU和SDU,PDU 是协议数据单元,表示在 特定通信层 中传输的数据单元,包含该层的协议控制信息和有效载荷。SDU 是服务数据单元,表示 上一层传递给当前层的数据,不包含当前层的协议信息。可以看作是$PDU = PCI + SDU$ (当前层的协议控制信息 + 上一层的数据单元)
帧类别
N-PDU的格式为
| 地址信息 | 协议控制信息 | 数据域 |
|---|---|---|
| N_AI | N_PCI | N_Data |
- 地址信息(N_AI):N_AI用于标识对等网络实体间的通信。N_AI信息在N_SDU-N_SA,N_TA,N_TAtype,N_AE中接收,应当复制包含在P_PDU中。如果接收到的NSDU中 < MessageData>及< Length>信息很长,需要网络层拆分这些数据以发送完整的信息,N_AI应当被复制并包含在每一个要发送的NPDU中。该域包含地址信息标识交互信息类型,数据交互的接收方和发送方。地址信息包含信息地址。
- 协议控制信息(N_PCI):该域标识交互的N_PDUs的类型。它也用来交互在网络层对等实体通信的其它控制参数。
- 数据域(N_Data):NPDU中的N_Data用于发送在< MessageData>参数中从服务使用者使用N_USData.request服务接收的数据。如果必要的话,会在网络发送之前拆分为更小的部分,以适应NPDU数据域。N_Data的大小依赖N_PDU的类型及地址格式的选取。
所有的N_PDU通过N_PCI来标识:
| N_PDU名 | N_PCI字节 | == | == | == |
|---|---|---|---|---|
| : | 字节1 | == | 字节2 | 字节3 |
| : | 7-4位 | 3-0位 | : | : |
| 单帧(SF) | N_PCItype=0 | SF_DL | N/A | N/A |
| 首帧(FF) | N_PCItype = 1 | FF_DL | == | N/A |
| 连续帧(CF) | N_PCItype = 2 | SN | N/A | N/A |
| 流控(FC) | N_PCItype=3 | FS | BS | STmin |
其中N_PCItype参数的定义为
| 16进制值 | 描述 |
|---|---|
| 0 | 单帧 (SF) 对于未拆分的信息,网络层提供了一个优化的网络协议,即将信息长度值仅放置在PCI字节里。单帧(SF)应当能支持在单个CAN帧中的信息传输。 |
| 1 | 首帧(FF) 首帧只支持一条信息无法在单个CAN帧中发送时使用。例如,拆分的信息。拆分信息的第一帧编码为FF,在接收到FF时,接受网络层实体应重组这些信息。 |
| 2 | 连续帧 (CF) 当发送拆分数据时,所有的连续帧跟着FF编码为连续帧(CF)。在接收到一个 连续帧,接受网络层实体应当重组接收到的数据字节直到整个信息被接收到。 接收实体在接收最后一帧信息并无接收错误之后,应传递这些信息到相邻的上 层。 |
| 3 | 流控帧(FC) 流控制的目的是调整CF N_PDUs发送的速率。流控协议数据单元的3种类型用 于支持这些功能。这些类型由协议控制信息的流状态(FS)域指示。 |
| 4-F | 保留 该范围的值为该协议保留。 |
SF
N_PDU的格式为:
| byte | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|
| Byte1 | == | == | == | == | == | == | == |
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 0 | 0 | 0 | SF_DL | == | == | == |
SF_DL值的定义为
| 16进制值 | 说明 |
|---|---|
| 0 | 保留 该范围的值为该协议保留。 |
| 1-6 | 单帧数据长度值(SF_DL) SF_DL应编码在N_PCI字节低位,并分配服务参数的值。 |
| 7 | 单帧数据长度(SF_DL)中标准地址 SF_DL=7时,只允许标准地址 |
| 8-F | 无效的 该范围值无效 |
如果网络层接收到一个SFDL=0的单帧(SF),网络层应当忽略接收SF N_PDU。如果网络层接收到使用标准地址且一个S℉DL大于7的单帧,或大于6且使用扩展或混合地址时,网络层应当忽略该SF N PDU。
FF
N_PDU的格式为:
| byte | == | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|
| Byte1 | == | == | == | == | == | == | == | Byte2 |
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | |
| 0 | 0 | 0 | 1 | FF_DL | == | == | == | == |
FF_DL值的定义为:
| 16进制数 | 说明 |
|---|---|
| 0-6 | 无效的 该范围值无效 |
| 7 | 首帧数据字节(FF_DL)支持扩展地址及混合地址 FF_DL=7只允许扩展地址及混合地址 |
| 8 -FFF | 首帧数据字节(FF_DL) 拆分信息在12个位的长度(FF_DL)上编码,并NPCI字节2中最低位置位“0”, NPCI字节1中最高位置为“3”。拆分信息最大数据长度支持4095个用户数据。 该数据当被分配到服务参数< Length>中。 |
如果网络层接收到FF_DL大于接收方缓冲区的首帧时,应当被认为是错误情况。网络层应当放弃该信息的接收,并且发送包含参数FlowStatus=Overflow的FC N_PDU。如果网络层接收到FF_DL小于8并且使用标准地址,或小于7并且使用扩展地址或混合地址时,网络层应当忽略该首帧并且不必发送一个FC N_PDU。
CF
N_PDU的格式为:
| byte | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|
| Byte1 | == | == | == | == | == | == | == |
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 0 | 1 | 0 | SN | == | == | == |
SN参数的定义:
| 16进制值 | 描述 |
|---|---|
| 0-F | 连续号(SN) 连续号应当在N_PCI字节1的低字位编码。SN设置值范围在0到15. |
CF N_PDU中参数SN用以说明连续帧的顺序。
- 对于所有拆分信息,SN开始于0。首帧应当分配值0,它不是明确地包含在NPCI域中,但应当按拆分信息顺序号为0。
- 紧随FF的第一个CF的SN应该被设置为1
- 在同一个拆分信息上,每一个新增的连续帧编号(SN)增1:
- 连续帧编号(SN)的值不受流控帧的影响。
- 当连续帧编号(SN)到达值15时,它在下一个连续帧中重置为0:
顺序编号为
| N_PDU | FF | CF | CF | CF | CF | CF | CF |
|---|---|---|---|---|---|---|---|
| SN (hex) | 0 | 1 | ·… | E | F | 0 | 1 |
如果接收到一个连续号错误的CF N_PDU信息,网络层则进行出错处理。信息的接收被终止,并且网络层发送一个<N_Result>参数=N_WRONG_SN的N_USData.indication指示服务至相邻上层。
FC
N_PDU的格式为:
| byte | == | == | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|---|
| Byte1 | == | == | == | == | == | == | == | Byte2 | Byte3 |
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | ||
| 0 | 0 | 1 | 1 | FS | == | == | == | BS | STmin |
FS参数定义:流状态参数(FS)指示发送网络实体是否继续信息的发送,发送网络层实体应当支持所有FS参数规定(不是保留的)的值。
| 16进制值 | 说明 |
|---|---|
| 0 | 继续发送(CTS) 流控帧继续发送参数,通过编码N_PCI第1字节为“0”,表示继续发送。它会促使发送方重新发送连续帧,该值意味着接收者准备好接收最大BS个连续帧。 |
| 1 | 等待(WT) 流控帧等待参数通过编码N_PCI第1字节为“1”。它会促使发送方继续等待新的流控帧(NPDU)的到来,并重新设置N_BS定时器。 |
| 2 | 溢出(OVFLW) 流控帧溢出参数通过编码NPCI第1字节为“2”。它会促使发送方中止拆分信息的发送并且做传递参数=N_BUFFER_OVFLW的N_USData.confirm指 示服务。该NPCI流控参数值仅能在跟在首帧NPDU的流控帧中使用,并且仅能在首帧中FF_DL信息的长度超过了接收实体缓冲区大小时使用。 |
| 3-F | 保留 该范围的值为该协议保留 |
如果接收到的FC N_PDU信息参数出错,网络层进行出错处理。信息的发送被中止,并且网络层传递一个参数< N_Result>=N_INVALID_FS的N_USData.confirm指示服务至相邻的上层。
BS参数定义:
| 16进制值 | 说明 |
|---|---|
| 00 | 块大小(BS) BS参数为0用于指示发送者在拆分数据的发送期间,流控制帧不再发送流控制帧了。发送网络层实体应当不停的发送剩下的连续帧以便接收网络层实体另外的流控帧,也就是说可以一直发送连续帧。 |
| 01-FF | 块大小(BS) 该范围的BS参数值用于指示发送方在没有接收网络实体的流控帧期间能发送 的最大数目的连续帧。 |
STmin参数定义:间隔时间(STmin)参数应当编码在FC N_PCI字节3。该时间在拆分数据发送过程中,由接收实体指定,并且由发送网络实体遵守。==STmin参数值指定了连续帧协议数据单元发送的最小时间间隔==。
| 16进制值 | 说明 |
|---|---|
| 00-7F | 间隔时间(STmin)范围:0ms-127ms 该STmin单元的范围00-7F为绝对单位毫秒(ms) |
| 80-F0 | 保留 该范围值为该协议保留 |
| F1-F9 | 间隔时间(STmin)范围100us-900us 该STmin单元的范围F1-F9最小分编为100微秒(us),参数值F1代表100us, 参数值F9代表900us。 |
| FA-FF | 保留 该范围值为该协议保留 |
STmin的度量是在一个连续帧发送完开始到请求下一个连续帧时的间隔时长。例如, 如果STmin=10(十进制),则连续帧网络协议数据单元最小时间间隔=10ms。
在拆分数据发送期间,如果FC N_PDU信息接收到ST参数值为保留值,发送网络实体则使用最长的ST值,即(7F-127ms),而不使用从接收网络实体接收到的值。
FC.Wait帧传递的最大值(N_WFTmax):该变量用于避免在通信发送方出现潜在错误挂起的时候,后者可能会持续等待。该参数用于对等通信并不被传递,因此不包含在FC的协议数据单元里。
- N_WFTmax参数应当指示一组能有多少个FC N_PDU WT能被接收者接收。
- N_WFTmax参数的上限由用户根据系统时钟定义。
- N_WFTmax参数仅由接收网络实体在接收信息的时候使用。
- 如果N_WFTmax参数值设置为0,流控应当继续仅使用FC N_PDU CTS。流控等待(FC N_PDU WT)不应再该网络实体中使用。
数据传输
单帧传输
sequenceDiagram
participant Sender
participant Receiver
Note over Sender,Receiver: SingleFrame (SF) 传输流程
Sender->>Receiver: SingleFrame (SF)多帧传输
sequenceDiagram
participant Sender
participant Receiver
Note over Sender,Receiver: 多帧传输流程(ISO-TP/AUTOSAR TP协议)
Sender->>Receiver: FirstFrame (FF)
Receiver-->>Sender: FlowControl frame (FC)
Sender->>Receiver: ConsecutiveFrame (CF)
Sender->>Receiver: ConsecutiveFrame (CF)
Sender->>Receiver: ConsecutiveFrame (CF)
Receiver-->>Sender: FlowControl frame (FC)
Sender->>Receiver: ConsecutiveFrame (CF)
Sender->>Receiver: ConsecutiveFrame (CF)[!tip]
多帧传输过程为:
首帧–>流控(其中需要传入bs参数)–>连续帧发送bs大小–>流控(传入接下来的bs大小)–>连续帧…以此类推
当bs为0的时候表示中间不需要流控,可以一直发送。
时间参数
不同的层级有不同的时间参数管理:
-
传输层
参数 含义 BS BlockSizeECU发送流控帧后,Tester被允许发送 连续帧最大帧数据,为0可以一直发。 STmin ECU发送流控帧后,连续帧之间的最大时间间隔 -
网络层
定时 参数 描述 数据链路服务 == 超时(ms) 运行需求 (ms) : : Start End : : N_As 发送方从请求发送到发送完成的时间间隔,超过这个时间发送中断
举例上位机发03 22 F1 84接收方CAN 帧发送时间(任何 N_PDU)
ECU响应10 01 62 F1 84 这段时间直至下一 个流控帧接收的时间L_Data.request L_Data.confirm 70 N/A N_Ar 传输流控帧到发送方的时间 L_Data.request L_Data.confirm 70 N/A N_Bs 首帧发送成功的时间节点到流控帧接收成功的时间节点,也就是说从数据确认发送到收到流控帧的最大时间间隔 L_Data.confirm(FF)
L_Data. confirm (FC)
L_Data.indicate(FC)L_Data.indicate(FC) 150 N/A N_Br 接收到首帧到发送流控帧的时间 L_Data.indicate(FF) L_Data.confirm(FC) L_Data.request (FC) 50 (N_Br+ N_Ar)<(0.9*N_Bs) N_Cs 接收到流控帧到发送连续帧的最大时间间隔,此处注意不是STmin的含义 L_Data.confirm(FC) L_Data.indication(CF) L_Data.request (CF) 50 (N_Cs+ N_As)<(0.9*N_Cr) N_Cr 接受方成功发送流控帧到接收到连续帧的时间 L_Data.confirm(FC) L_Data.indication(CF) L_Data.indication (CF) 150 – S:发送者
R:接收者== == == == == -
会话层
参数 含义 S3_Tester 发送方维持非默认会话的最大时间 S3_Sever 接收方未接受到任何诊断报文维持在非默认会话下 的时间 -
应用层
参数 含义 P2_Client 发送方发送完请求消息后等待服务器响应超时的时 间 P2*_Client 发送方收到否定响应码为0x78的否定响应后等待接 受方发送响应的增强型超时时间设置。 P2_Sever 接收方收到请求后发出响应的实际时间 P2*_Sever 接收方发送0x78否定响应到发出否定响应的实际时 间。 (此处很少用) P3_ClientPyh 发送方在收到物理寻址(phy)的肯定响应下允许发 送下一条物理寻址请求的最小时间间隔 P3_ClientFun 发送方在收到物理寻址(phy)的肯定响应下允许发 送下一条功能寻址(fun)的最小时间间隔
单帧传输

-
发送方N_USData.req:会话层向传输网络层发出未分段的消息
发送方L_Data.req:传输网络层将单帧传输到数据链路层并启动N_As计时器。
-
接收器L_Data.ind:数据链路层向传输网络层发出CAN帧的接收。
接收方N_USData.ind:传输网络层向会话层下发未分段的完成信息。
发送方 L_Data.con:数据链路层向传输网络层确认 CAN 帧已被发送已确认。发送方停止 N_As 计时器。
发送方N_USData.con:传输网络层向会话层发出未分段的完成信息
多帧传输

-
发送方N_USData.req:会话层向传输网络层发出分段消息。
发送方L_Data.req:传输网络层将首帧传输到数据链路层并启动N_As定时器。
-
接收方L_Data.ind:数据链路层向传输网络层发出CAN帧的接收。接收器启动 N_Br 定时器。
接收方N_USDataFF.ind:传输网络层向会话层发出接收第一个帧的消息分段消息。
发送方L_Data.con:数据链路层向传输网络层确认 CAN 帧已被发送,发送方停止N_As 定时器并启动N_Bs 定时器。
-
接收方L_Data.req:传输网络层传输流控(ContinueToSend和BlockSize,值为2d)到数据链路层并启动N_Ar定时器。
-
发送方 L_Data.ind:数据链路层向传输/网络层发出CAN 帧的接收。发送方停止 N_Bs 计时器并启动 N_Cs 计时器。
接收方 L_Data.con:数据链路层向传输/网络层确认CAN帧已确认。接收器停止 N_Ar 定时器并启动 N_Cr 定时器。 -
发送方 L_Data.req:传输/网络层将第一个 ConsecutiveFrame 传输到数据链路层并启动 N_As 定时器。
-
接收方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。接收器重新启动 N_Cr 定时器。
发送方 L_Data.con:数据链路层向传输/网络层确认 CAN 帧已被确认。发送方停止 N_As 定时器,并根据前一个 FlowControl 的分离时间值 (STmin) 启动 N_Cs 定时器。 -
发送方 L_Data.req:当 N_Cs 定时器经过时(STmin),传输/网络层将下一个 ConsecutiveFrame 传输到数据链路层,并启动 N_As 定时器。
-
接收方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。接收器停止 N_Cr 定时器并启动 N_Br 定时器。
发送方 L_Data.con:数据链路层向传输/网络层确认 CAN 帧已被确认。发送方停止 N_As 计时器并启动 N_Bs 计时器。发送方正在等待下一个 FlowControl。 -
接收方 L_Data.req:传输/网络层将 FlowControl(等待)传输到数据链路层并启动 N_Ar 定时器。
-
发送方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。发送方重新启动 N_Bs 计时器。
接收方 L_Data.con:数据链路层向传输/网络层确认 CAN 帧已确认。接收器停止 N_Ar 定时器并启动 N_Br 定时器。 -
接收方 L_Data.req:传输/网络层将 FlowControl (ContinueToSend) 传输到数据链路层并启动 N_Ar 计时器。
-
发送方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。发送方停止 N_Bs 计时器并启动 N_Cs 计时器。
接收方 L_Data.con:数据链路层向传输/网络层确认 CAN 帧已确认。接收器停止 N_Ar 定时器并启动 N_Cr 定时器。 -
发送方 L_Data.req:传输/网络层将 ConsecutiveFrame 传输到数据链路层,启动 N_As 定时器。
-
接收方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。接收器重新启动 N_Cr 定时器。
发送方 L_Data.con:数据链路层向传输/网络层确认 CAN 帧已被确认。发送方停止 N_As 定时器,并根据前一个 FlowControl 的分离时间值 (STmin) 启动 N_Cs 定时器。 -
发送方 L_Data.req:当 N_Cs 定时器(STmin)过去时,传输/网络层将最后一个 ConsecutiveFrame 传输到数据链路层,并启动 N_As 定时器。
-
接收方 L_Data.ind:数据链路层向传输/网络层发出 CAN 帧的接收。接收器停止 N_Cr 计时器。
接收方 N_USData.ind:传输/网络层向会话层发出分段消息的完成。
更清晰的时间参数图为:

超时处理
| 超时 | 触发 | 动作 |
|---|---|---|
| N_As | 发送方没有及时发送N_PDU | 放弃信息的接收并传递< N_Result>= N_TIMEOUT_A的N_USData.confirm指示 |
| N_Ar | 接收方没有及时发送N_PDU | 放弃信息的接收并传递< N_Result>= N_TIMEOUT_A 的N_USData.confirm指示 |
| N_Bs | 发送方没有接收到流控帧(丢失, 覆盖)或在首帧前收到,或连续 帧没有被接收方接收到。 | 放弃信息的发送并传递< N_Result>= N_TIMEOUT_Bs的N_USData.confirm指示 |
| N_Cr | 接收方没有收到连续帧或之前流 控帧未被发送方收到。 | 放弃信息的接收并传递< N_Result>= N_TIMEOUT_Cr的N_USData.confirm指示 |
地址映射
网络层数据交互有三种地址格式的支持:
- 标准
- 扩展
- 混合
不同的地址格式需要不同数据长度的CAN帧对包含数据的地址信息进行打包。因此,选择单个CAN帧的数据长度依赖于地址格式类型的选取。
[!note]
注意:这里的地址和数据格式中的Can ID不同,标准地址并不是标准帧中的CAN id
标准地址
标准地址的组成格式如下:
| N_PDU类型 | CAN标识 | CAN帧数据域 | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|---|
| 字节1 | 字节2 | 字节3 | 字节4 | 字节5 | 字节6 | 字节7 | 字节8 | ||
| 单帧(SF) | N_AI | N_PCI | N_Data | == | == | == | == | == | == |
| 首帧(FF) | N_AI | N_PCI | == | N_Data | == | == | == | == | == |
| 连续帧(CF) | N_AI | N_PCI | N_Data | == | == | == | == | == | == |
| 流控帧(FC) | N_AI | N_PCI | == | == | == | N/A | == | == | == |
在标准地址中,不同的N_SA、N_TA、N_TAtype的每个组合,都会分配一个唯一的Can标识符,即一个CAN id就已经定义了这些参数,所以可以将N_AI等价为Can ID。
[!tip]
注意:以上表格是功能和物理寻址,但是实际上,功能寻址只有单帧数据格式,没有其他的数据格式。
标准混合地址是标准地址的子格式,也就是映射到CAN标识的地址信息更多一层定义。对于标准混合通信只允许有29bit的CAN标识。
标准混合地址物理寻址的数据格式为:
| N_PDU类型 | 29bitCAN标识,位地址 | == | == | == | == | == | CAN数据域位地址 | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 28…26 | 25 | 24 | 23…·16 | 15…8 | 7…0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 单帧(SF) | 110 (bin) | 0 | 0 | 218(dec) | N_TA | N_SA | N_PCI | N_Data | == | == | == | == | == | == |
| 首帧(FF) | 110 (bin) | 0 | 0 | 218(dec) | N_TA | N_SA | N_PCI | == | N_Data | == | == | == | == | == |
| 连续帧(CF) | 110 (bin) | 0 | 0 | 218(dec) | N_TA | N_SA | N_PCI | N_Data | == | == | == | == | == | == |
| 流控帧(FC) | 110 (bin) | 0 | 0 | 218(dec) | N_TA | N_SA | N_PCI | == | == | N/A | == | == | == | == |
[!tip]
注意:功能寻址仅有单帧数据格式,且23…16位域位219(dec)
拓展地址
对于N_SA,N_TA,N_TAtype,一个特定的CAN标识符被分配。N_TA安置在CAN帧数据域第一个字节,N_PCI和N_Data安置在CAN帧数据域剩下的字节。
| N_PDU类型 | CAN标识 | CAN帧数据域 | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|---|
| 字节1 | 字节2 | 字节3 | 字节4 | 字节5 | 字节6 | 字节7 | 字节8 | ||
| 单帧(SF) | N_AI,无N_TA | N_TA | N_PCI | N_Data | == | == | == | == | == |
| 首帧(FF) | N_AI,无N_TA | N_TA | N_PCI | == | N_Data | == | == | == | == |
| 连续帧(CF) | N_AI,无N_TA | N_TA | N_PCI | N_Data | == | == | == | == | == |
| 流控帧(FC) | N_AI,无N_TA | N_TA | N_PCI | == | == | N/A | == | == | == |
混合地址
混合地址是将Mtype设置为远程诊断的地址格式。混合地址物理寻址的数据格式为:
| N_PDU类型 | 29bitCAN标识,位地址 | == | == | == | == | == | CAN数据域位地址 | == | == | == | == | == | == | == |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 28…26 | 25 | 24 | 23…16 | 15…8 | 7…01 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 单帧(SF) | 110 (bin) | 0 | 0 | 206(dec) | N_TA | N_SA | N_AE | N_PCI | N_Data | == | == | == | == | == |
| 首帧(FF) | 110 (bin) | 0 | 0 | 206(dec) | N_TA | N_SA | N_AE | N_PCI | == | N_Data | == | == | == | == |
| 连续帧(CF) | 110 (bin) | 0 | 0 | 206(dec) | N_TA | N_SA | N_AE | N_PCI | N_Data | == | == | == | == | == |
| 流控帧(FC) | 110(bin) | 0 | 0 | 206(dec) | N_TA | N_SA | N_AE | N_PCI | == | == | N/A | == | == | == |
[!tip]
注意:功能寻址仅有单帧数据格式,且23…16位域位205(dec)
CanTsyn
时间同步的引入
时间同步有啥用呢?就拿现在爆火的ADAS来说,域控制器需要融合雷达,摄像头等传感器的数据,然后进行算法融合所有传感器的数据后最终才能进行判断和执行,这个时候就存在一个问题,因为传感器数据并不都是来源于同一个ECU,所以就需要一个手段来保证域控融合的所有传感器数据都是产自同一时刻,所以传感器在向域控制器发送传感数据时都需要加上一个时间戳,所以让车上所有的ECU里面的时间戳都保证一模一样就成了必要的事情。
而CanTsyn模块就是基于CAN总线的时间同步方案,所以它的功能也是非常的简单,就是接收一些时间同步报文,然后根据报文中包含的时间信息获取当前时间。
这里多说一句,还有在Ethernet总线上的负责时间同步的模块叫做EthTSyn模块,这个模块其实就是基于PTP (Precision Time Protocol)协议搞出来的,有的朋友可能还知道gPTP,gPTP其实是PTP协议的一个子集,而EthTSyn模块则是针对汽车应用基于PTP还额外做出一点点改变,感兴趣的朋友可自行搜索一下。
时间同步的角色
时间同步框架如下图所示:

- Time Domain:表示哪些组件(例如节点,通信系统)链接到某个时基。一个时域可以没有、包含一个或多个子时域。如果时域的时序层次结构中不包含时间网关,即所有节点都连接到同一总线系统,则不存在子时域。
- Time Subdomain:表示哪些组件(例如节点)链接到某个时基,范围仅限于一条通信总线。
- Global Time Master: 在整个Time Domain中提供全局时钟基准的主时钟。
- Time Master:在同一个Time Subdomain中提供全局时间基准的主时钟。
- Time Gateway:在整个Time Domain中既作为上级时钟源的从时钟,又同时作为下级时钟源的主时钟源。
- Time Slave:在一个Time Subdomain中作为需要同步的从时钟。
时间同步过程
基于CAN总线的时间同步过程从下至上可分为CANDrv、CanIf、CanTsyn、StbM四个模块,如下:

其中CanTsync模块负责时间同步实现,而StbM则负责抽象基于不同传输介质的AUTOSAR时间同步协议,为整个软件系统来提供时间同步之后的全局时间戳。其他总线原理和过程一样,下面就以CanTsync模块为例说明一下时间同步过程。
四种报文
在时间同步过程中主要有SYNC、FUP、OFS、OFNS 这四种报文,每一种报文又分为需要校验 CRC 和不需要校验 CRC 两种方式,有无CRC校验由参数CanTSynGlobalTimeTxCrcSecured决定。
在时间同步过程中,SYNC和FUP报文为一组,需要成对发送和接收,其格式如下:
| 报文类型 | (Type)Byte0 | Byte1 | Byte2 | Byte3 | Byte4~Byte7 |
|---|---|---|---|---|---|
| SYNC no CRC | 0x10 | User Data, 默认为 0 | bit7 ~ bit4:Time Domain bit3 ~ bit0:Sequence Count |
User Data, 默认为 0 | SyncTimeSec:48 位秒的低 32 位的部分时间 |
| SYNC CRC | 0x20 | CRC | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) |
User Data, 默认为 0 | SyncTimeSec:48 位秒的低 32 位的部分时间 |
| FUP no CRC | 0x18 | User Data,默认为 0 | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) |
bit7 ~ bit3:保留位,默认为0; bit2:SGW, 时间网关同步状态, 当 SGW 值为 0 时,本地时间与 GTM 同步;当 SGW 值为 1 时,本地时间与 GTM 下的 TG 同步。 bit1 ~ bit0:OVS,SyncTimeNSec 溢出的部分 |
SyncTimeNSec:以纳秒为单位的 32 位的时间戳 |
| FUP CRC | 0x28 | CRC | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) |
bit7 ~ bit3:保留位,默认为0; bit2:SGW, 时间网关同步状态, 当 SGW 值为 0 时,本地时间与 GTM 同步;当 SGW 值为 1 时,本地时间与 GTM 下的 TG 同步。 bit1 ~ bit0:OVS,SyncTimeNSec 溢出的部分 |
SyncTimeNSec:以纳秒为单位的 32 位的时间戳 |
在时间同步过程中,OFS和OFNS 报文为一组,需要成对发送和接收,其格式如下:
| 报文类型 | (Type)Byte0 | Byte1 | Byte2 | Byte3 | Byte4~Byte7 |
|---|---|---|---|---|---|
| OFS no CRC | 0x30 | User Data, 默认为 0 | bit7 ~ bit4:Time Domain bit3 ~ bit0:Sequence Count | OfsTimeSecLsbHi:从 secondsHi 开始的 8 位偏移时间戳(LSB) | OfsTimeSecLsbLo:来自 secondsLo 的 32 位偏移时间戳(LSB) |
| OFS CRC | 0x40 | CRC | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) | OfsTimeSecLsbHi:从 secondsHi 开始的 8 位偏移时间戳(LSB) | OfsTimeSecLsbLo:来自 secondsLo 的 32 位偏移时间戳(LSB) |
| OFNS no CRC | 0x38 | User Data,默认为 0 | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) | OfsTimeSecMsb :从 secondsHi 开始的 8 位偏移时间戳(MSB) | OfsTimeNSec :以纳秒为单位的 32 位的时间戳 |
| OFNS CRC | 0x48 | CRC | Time Domain(bit7 ~ bit4) Sequence Count(bit3 ~ bit0) | OfsTimeSecMsb :从 secondsHi 开始的 8 位偏移时间戳(MSB) | OfsTimeNSec :以纳秒为单位的 32 位的时间戳 |
注:当参数CanTSynUseExtendedMsgFormat为TRUE时,OFS和OFNS的报文格式就会发生改变,这里就不多做介绍了,感兴趣的朋友可参考AUTOSAR官方文档。
时间同步过程
CanTsyn模块的时间同步过程如下图所示:

- TM节点在t0r时刻调用接口发送SYNC信号,SYNC信号中包含当前时间戳为s(t0r),在t1r时刻SYNC信号发送完成,此时的时间为t1r,所以从TM开始发送报文,到发送成功需要时间t4r = t1r - t0r; 此时TM节点再次发送FUP信号,信号中包含的时间信息为t4r = t1r - t0r。
- TS节点在t2r时刻接收到了SYNC报文;在t3r时间接收到了FUP报文。
- 根据以上信息,TS节点在接收完SYNC和FUP报文的时候,即可根据下面的式子算出当前时间:real time = t3r-t2r+s(t0r)+t4r。
对于CanTsyn模块的基本原理就说到这里了,其实还有很多小细节没有涉及到,比如Sequence Count的检查, OVS处理, CRC校验等,感兴趣的朋友可以参考文章:《AUTOSAR基础篇之CanTsyn》。
StbM
在上一节已经说到StbM(Synchronized Time Base Manager)模块负责抽象基于不同传输介质的AUTOSAR时间同步协议,为整个软件系统来提供时间同步之后的全局时间戳。StbM 模块主要功能如下:
- 提供同步时间;
- 管理同步时间的状态;
- 时间路由。
StbM 模块在AUTOSAR架构中与其他模块的交互情况如下图所示:

可以看到StbM模块透过 RTE 与用户直接交互。在基础软件中与< Bus >TSyn 和 OS 模块交互。对于StbM模块而言,AUTOSAR给其整了三种用户,分别是Active Customer, Notification Customer,Triggered Customer,这三种用户的含义如下:
- Active Customer:可以主动调用StbM模块函数进行相关操作的用户,该用户只能是SWC。
- Notification Customer:只能被StbM模块被动发送通知的用户,该用户只能是SWC。
- Triggered Customer:只能被StbM模块主动调用函数进行相关操作的用户,该用户只能是OS。
图中的序号代表的具体操作为:
- StbM主动调用TriggerCustomer提供的函数接口来完成时间同步,基本上都是同步OS Schedule Table;
- Active Customer(SWC)主动调用StbM提供的标准接口来获取当前时间戳或者时间同步状态;
- Active Customer(SWC)主动调用StbM提供的标准接口来更新StbM维护的时间基准;
- StbM模块通过通知函数通知Notification Customer(SWC)有事件发生,事件有:Time Base的状态发生改变;Time Base到达一个Notification Customer(SW-C)提前设置好的未来时间值。
- Notification Customer(SWC)主动调用StbM提供的标准接口来设置过程④中的未来时间值。
- StbM模块通过 <bus>Tsyn模块提供的标准接口来更新StbM的时间基准;
- StbM模块主动通过Tsyn模块提供的标准接口来将当前的时间信息发送到相应的bus总线上。
时间同步
一个时间同步网络包含一个时间主节点和至少一个时间从节点。时间主节点通过时间同步报文将全局同步时间发送给每个时域上连接的时间从节点。时间从节点正确接收和处理时间同步报文后,更新本地时间并继续运行,直到下次收到时间同步报文。时间同步框架如下图所示:
- Time Master:当 ECU 作为一个时基的时间主节点时,该 ECU 的 StbM 模块可以为<Bus>TSyn 模块提供精确的时间并发起时间同步操作(即往对应总线上发时间同步报文),<Bus>TSyn 将从 StbM 获取到的精确时间通过时间同步报文发送给网络中的时间从节点。同时应用也可以通过 Rte 获取该时基的精确时间,但不能修改该时基的时间值,但是如果该 ECU 是Time Domain的全局时间主节点,则应用可通过 Rte 设置该时基的时间值。
- Time Slave:当 ECU 作为一个时基的时间从节点时,<Bus>TSyn 基于接收时间同步报文中的时间和自己本地的时间,计算得到精确时间,然后调用 StbM 模块函数调整该时基的时间值, SWC通过 Rte 仅可以读取该时基的时间值。
- Time Gateway:时间网关是一个时基同时由时间主节点和时间从节点引用,该时基的时间值更新过程和使用方法是单独时间主节点和时间从节点的综合。
Time Base Status
每个时基都有一个状态字节,高 4 位预留,低 4 位分别表示 TimeOut(Bit0),TimeLeap(Bit1),SyncToGateway(Bit2)和 GlobalTimeBase(Bit3)。初始化完成后,所有时基状态字节的值为 0x00。
- GlobalTimeBase(Bit3)
当 应 用 成 功 调 用 StbM_SetGlobalTime() 或 者 <Bus>TSyn 成 功 调 用StbM_BusSetGlobalTime()后,GlobalTimeBase(Bit3)被置位为 1,直到下次初始化才会被清除为 0。 - SyncToGateway(Bit2)
每次<Bus>TSyn 成功调用 StbM_BusSetGlobalTime(),SyncToGateway(Bit2)的值都将根 据 该 函 数 的 入 参 syncToTimeBase 更 新 。 若 syncToTimeBase 为 1 , 则 设 置SyncToGateway(Bit2)等于 1,若 syncToTimeBase 为 0,则设置 SyncToGateway(Bit2)等于0 。 若 连 续 两 次 调 用 StbM_BusSetGlobalTime() 的 时 间 间 隔 大 于 配 置 参 数StbMSyncLossTimeout 的值,则设置 SyncToGateway(Bit2)等于 1,该操作是在主函数中进行的。每次应用成功调用 StbM_SetGlobalTime(),SyncToGateway(Bit2)都将被设置为 0。 - TimeLeap(Bit1)
每次<Bus>TSyn 成功调用 StbM_BusSetGlobalTime(),StbM 都会把将要更新的时间值与本地时间值比较,若两个时间之间的差值大于配置参数 StbMSyncLossThreshold 的值,则设置 TimeLeap(Bit1)为 1,否者设置为 0。 - TimeOut(Bit0)
每次<Bus>TSyn 成功调用 StbM_BusSetGlobalTime(),都将设置 TimeOut(Bit0)等于 0。若 连 续 两 次 调 用 StbM_BusSetGlobalTime() 的 时 间 间 隔 大 于 配 置 参 数StbMSyncLossTimeout 的值,则设置 TimeOut(Bit0)等于 1,该操作是在主函数中进行的。
Functional safety
E2E
E2E在AUTOSAR架构中,它被定义成是一个函数库。E2E 可以保护安全相关的数据交换,避免数据交换过程中通信链路造成的错误。E2E通信保护库实现了这些保护机制算法。E2E 的主要功能:
- 为将要发送的安全相关的数据提供保护;
- 对接收到的安全相关的数据进行校验;
- 对接收到的安全相关的数据错误做出指示。
E2E模块保护数据的算法其实就是CRC,它主要就是定义了怎样使用一些特定的CRC算法来确保数据的准确性和连续性,E2E用在发送数据上叫做Protect,用在接收数据上叫做Check。
[!tip]
官方标准手册请参见autosar.org/fileadmin/standards/R22-11/CP/AUTOSAR_SWS_E2ELibrary.pdf
E2E 模块可以被三个地方调用,分别是COM 模块中的COM callout ,E2E Transformer模块 和 E2E Protection Wrapper。当 E2E 库被 Transformer 和 Wrapper 调用时,需要在 Transformer 和 Wrapper 中对数据元素进行序列化。在 E2E 模块内部会调用 Crc 模块提供函数。
五种保护机制
E2E提供了一下五种保护机制来保护数据安全,如下:
- CRC:发送端根据数据计算CRC值,接收端会重新计算并检查。
- Sequence Counter: 发送端每次传输,该值都会加一,接收端会检查该值。
- Alive Counter:发送端每次传输,该值都会加一,接收端会检查该值,通常跟Sequence Counter是一个东西(具体我也不知道有什么区别)。
- Data ID:给每个数据或者I-PDU Group编号。
- Timeout detection: 接收者接收超时,发送者响应超时。
为了同时满足保护机制的标准化和灵活性要求,E2E 模块提供了很多个 profile,包括P01、P02、P04、P05 和 P06,P07, P11, P22,它们之间的最大区别就在于每一个所采用的保护机制是以上五个保护机制的子集。
| Profile | 保护机制 | 发送描述 | 最大保护数据长度 |
|---|---|---|---|
| Profile01 | Counter(4bit)、Data ID(16bit)、 CRC8、Timeout monitoring | Data ID由Data ID Mode决定是否发送 ,Counter和CRC需要发送 | 30bytes |
| Profile02 | Counter(4bit)、Data ID List(8bit)、 CRC8 | Data ID 不会发送,仅用作 CRC计算,Counter和CRC需要发送 | 256bytes |
| Profile04 | Counter(16bit)、Data ID(32bit)、CRC32、Length(16bit) | Counter、Data ID、CRC、Length均会发送 | 4096bytes |
| Profile05 | Counter(8bit)、Data ID(16bit) 、CRC16 | Data ID 不会发送,仅用作 CRC计算,Counter和CRC需要发送 | 4096bytes |
| Profile06 | Counter(8bit)、Data ID(16bit)、CRC16、Length(16bit) | Data ID 不会发送,仅用作 CRC 计算,Counter,CRC和Length需要发送 | 4096bytes |
| Profile07 | Counter(32bit)、Data ID(32bit)、CRC64、Length(32bit) | Counter、Data ID、CRC、Length均会发送 | 未知 |
| Profile11 | Counter(4bit)、Data ID(16bit or 12bit)、CRC8 | Counter、Data ID、CRC均会发送 | 30bytes |
| Profile12 | Counter(4bit)、Data ID List(16*8bit)、CRC8 | Data ID 不会发送,仅用作 CRC计算,Counter和CRC需要发送 | 未知 |
- 保护机制中包含Length的Profile支持保护不定长数据,其他则不支持。
- 保护机制中的Data ID List指的是每一条消息的Data ID由Counter值去确定,所以需要静态定义Data ID和Counter的对应表格,这种机制就叫做Data ID List。
- 当使用 profile4、profile5 和 profile6 保护数据时,如果需要保护的数据较长时,CRC 计算时间会较长,由于 E2E 模块的保护和检测功能都是同步执行的,可能会影响系统的实时性。
- 每一种profile检测到错误时所采取的措施也是不一样的,至于每一种profile的工作机制大家可以参考官方规范手册autosar.org/fileadmin/standards/R22-11/CP/AUTOSAR_SWS_E2ELibrary.pdf《AUTOS
E2E的状态机
E2E profile 中对数据的检测只表示在单个周期内数据的正确性,E2E 的状态机则将固定次数内(reception window)的 profile 数据检测结果进行统一管理,并将处理后的状态提供给调用者,调用者可根据状态决定是否使用数据。E2E 各状态转换描述如下:

各个状态具体描述如下:
| 状态 | 描述 |
|---|---|
| E2E_SM_DEINIT | 未初始化状态,在此状态如果用户调用 E2E_SMCheck,返回 E2E_E_WRONGSTATE。 |
| E2E_SM_NODATA | 无数据状态,调用 E2E_SMCheckInit,进入该状态。在该状态如果用户调用 E2E_SMCheck,检测的 profile 状态不 为 E2E_P_ERROR 和 E2E_P_NONEWDATA , 则 进 入E2E_SM_INIT 状态,否则一直停留在此状态。 |
| E2E_SM_INIT | 初 始 化 状 态 , 在 reception window 内 , 用 户 调 用E2E_SMCheck,更新 ErrorCounter 和OKCounter 的值。如果 ErrorCounter 的值小于等于设置的阈值并且 OKCounter大于等于设置的阈值,则进入 E2E_SM_VALID 状态。如 果 ErrorCounter 的 值 大 于 设 置 的 阈 值 , 则 进 入E2E_SM_INVALID 状态。否则一直停留在该状态。 |
| E2E_SM_VALID | 数 据 有 效 状 态 , 在 reception window 内 , 用 户 调 E2E_SMCheck,更新 ErrorCounter 和 OKCounter 的值。如果 ErrorCounter 的值小于等于设置的阈值并且 OKCounter大于等于设置的阈值,则停留在该状态。否则进入E2E_SM_INVALID 状态。 |
| E2E_SM_INVALID | 数 据 无 效 状 态 , 在 reception window 内 , 用 户 调 用E2E_SMCheck,更新 ErrorCounter 和 OKCounter 的值。如果 ErrorCounter 的值小于等于设置的阈值并且 OKCounter大于等于设置的阈值,则进入 E2E_SM_VALID 状态。否则一直停留在该状态。 |
E2E Protection Wrapper
前面提到了E2E Protection Wrapper 属于 E2E 三种调用者之一,其位置比较特殊,它不属于BSW层,而是位于 RTE 之上,属于 SWC 层的一部分,其保护的数据需要为信号组的形式。其结构如下:

E2E Protection Wrapper主要功能如下。
- 负责将复杂数据元素进行序列化
- 负责将调用 E2E Lib 时使用的数据结构实例化和初始化
- 调用 E2E 接口对数据元素进行保护
- 调用 RTE 接口接收和发送数据
E2E Protection Wrapper 为每组需要保护的数据元素生成一组接口,发送数据接口E2EPW_Write_<p>_<o> 和 E2EPW_WriteInit_<p>_<o> ,接 收数据接口E2EPW_Read_<p>_<o> 和 E2EPW_ReadInit_<p>_<o> 。 当 用 户 发 送 数 据 时 调 用E2EPW_Write_<p>_<o> ()接口,该接口将数据进行序列化,调用 E2E 的接口保护数据,调用 RTE 的数据发送接口发送数据;当用户接收数据时调用 E2EPW_Read_<p>_<o> ()接口,该接口调用 RTE 的数据接收接口接收数据,序列化接收数据,并调用 E2E 接口检查接收数据。
E2E 错误反馈方式
当用户使用 E2E Protection Wrapper 调用 E2E 时,E2E 中检查的错误通过 E2E Protection Wrapper 中的返回值反馈给用户。该返回值为 32 位的无符号数,各字节代表不同的错误类型。**E2EPW_Write< p>< o>**和 **E2EPW_Read< p>< o>**返回值描述如下表。
| 函数类型 | 返回值 Byte3 | 返回值 Byte2 | 返回值 Byte1 | 返回值 Byte0 |
|---|---|---|---|---|
| Write | – | E2E_PxxProtect 函数 的 返 回 值 , 当Byte1 为 E2E_E_OK时,该值才有效 | E2E ProtectionWrapper 实 时 检 查的结果 | Rte_Write 函数的返回值,当 Byte2 为E2E_E_OK 时,该值才有效 |
| Read | E2E_PxxCheck 函数检查的错误状态,当Byte2 为 E2E_E_OK时,该值才有效 | E2E_PxxCheck 函数的返回值,当 Byte1为 E2E_E_OK 时,该值才有效 | E2E Protection Wrapper 实 时 检 查的结果 | Rte_Read 函数的返回值,当 Byte1 为E2E_E_OK 时,该值才有效 |
E2E_PxxCheck 函数检查的错误状态描述如下表:
| 错误状态 | 值 | 描述 |
|---|---|---|
| E2EPW_STATUS_OK | 0x0 | 数据被正确接收,无 crc、counter 等错误 |
| E2EPW_STATUS_NONEWDATA | 0x1 | 检查函数被调用,但是未收到新数据 |
| E2EPW_STATUS_WRONGCRC | 0x2 | 接收到新数据,但是存在 crc 或其他数据检查错误 |
| E2EPW_STATUS_SYNC | 0x3 | 数据被正确接收,但是由于上次产生的检查错误,导致数据连续性检查需要进行数据同步 |
| E2EPW_STATUS_INITIAL | 0x4 | 已接收数据,crc 正确,但是由于进行了初始化导致无法验证 counter 的正确性 |
| E2EPW_STATUS_REPEATED | 0x8 | 已接收数据,crc 正确,但是 counter 重复 |
| E2EPW_STATUS_OKSOMELOST | 0x20 | 已接收数据,crc 正确,但是 counter 不连续,DeltaCounter 在可接受范围内 |
| E2EPW_STATUS_WRONGSEQUENCE | 0x40 | 已接收数据,crc 正确,但是 counter 不连续,DeltaCounter 超出可接受范围 |
WdogM
在AUTOSAR架构中,看门狗的架构也是非常的简单,如下图:

服务层有WdogM(Wdog Manager)模块,主要为软件状态机,通过软件策略来实现一些监测功能,对上可汇报当前错误状态,对下可调用抽象层接口进行一系列不同类型的复位操作。ECU抽象层则有WdogIf模块,主要将各种看门狗模块进行抽象化管理,让上层服务层不用关心看门狗类型,直接闭着眼睛瞎操作就行了。MCAL层则就是各种类型看门狗的WdgDriver了,常用的有MCU内部看门狗,通过SPI通信协议来喂的外部狗,还有用PWM波来喂的外部狗等等。
对于WdogIf模块和MCAL中的各种WdgDriver,在这里就不多说了,接下来重点来看看WdogM模块,它才是AUTOSAR看门狗系统的精髓。
在介绍之前,介绍几个AUTOSAR术语:
| 名称 | 描述 |
|---|---|
| SE (Supervised Entities) | 被WdgM 监测的逻辑单元,一般可以为一个TASK,也可以是多个TASK的结合 |
| CP Checkpoints | WdgM 的监测点,一个SE里面肯定会有一个或很多个CP |
| Condition Value | 喂狗条件,该 value 为 WdgDriver 硬件喂狗的条件, WdgDriver 每次正常喂狗,该值将减 1,当其为 0 时, WdgDriver 将停止喂狗。正常情况下, WdgM 将实时刷新该值,保证其不会为 0。 |
| Flow/Graph | 指的是一个完整程序流, WdgM 会监控其中的 CP 路径 |
WdgM 是 AUTOSAR 基础软件架构中的一个标准的软件模块,属于服务层(service layer)。它主要用于监控应用程序执行的可靠性,包括监控程序运行的周期和程序运行逻辑的正确性。WdgM 主要提供以下功能:
- 监控位于 MCU 内的多个独立的应用程序,它们可以拥有独立的时序要求;
- 对功能安全相关的任务和周期性功能(main function),进行逻辑流监控;
- 每个 SE 可以具备单独的错误反应机制;
- 根据 ECU 的状态和硬件的能力,支持看门狗的 Off\Slow\Fast 模式。
WdogM喂狗机制
WdgDriver 负责操作硬件寄存器,进行实际的喂狗动作。 AUTOSAR 建议在中断中进行喂狗。 WdgDriver 在喂狗之前,需判断Condition Value是否大于 0,大于0时才进行喂狗。成功喂狗后,Condition Value–。
WdgM 负责刷新喂狗条件,在WdgM_MainFunction 会刷新Condition Value。刷新喂狗条件,即将Condition Value置为用户配置的大于 0 的值。 因此,如果 WdgM 运行出现问题,无法刷新Condition Value,则Condition Value会自减至 0,进而引起看门狗复位。
Condition Value的存在,使得 WdgM 可以更灵活的控制看门狗的复位时间,从决定复位到真正复位,可以留给用户更充分的准备时间。
WdogM监测机制
WdogM提供三种监测机制,分别是:
- Alive Supervision
- Deadline Supervision
- Logical Supervision。
Alive Supervision
Alive Supervision 主要用来监控某个 SE 运行的周期是否正确。其基本原理是, 在待监控的 SE 中设置 CP,在固定时间内,监测该 CP 到达的次数。基本实现方式就是一开始需要用户配置一个上限值和下限值,在一个统计周期内,WdogM会计算出这个SE的运行次数,如果运行次数超出这个区间,则Alive 检测失败,否则 Alive 检测成功。
使用 Alive Supervision 的注意事项如下:
- 同一 CP 不能隶属于多个 Alive Supervision;
- Alive Supervision 监控到错误后,其 SE 的本地状态将首先切换至 FAILED ,并且 错 误 计 数 增 加 , 如 果 Alive 错 误 计 数 超 过WdgMFailedAliveSupervisionRefCycleTol,则状态切换为 EXPIRED;
- Alive Supervision 监控正确,其 SE 的本地状态如果为 FAILED ,错误计数减小,当错误计数减小到 0 后,其 SE 的本地状态将切换至 OK。
Deadline Supervision
某些场景下,应用程序需要关注某段程序运行的时间,过长或过短都说明程序执行异常。在 WdgM 中,称之为 Deadline Supervision,抽象为监控两个 CP 之间运行的时间。Deadline Supervision 具体算法如下:用户将在 WdgM 中配置Deadline Supervision 的起始 CP、结束 CP、最小时间门限和最大时间门限。在运行到起始 CP 时启动 Deadline Supervision,在运行到结束 CP 时,计算运行时间是否配置合理范围内。
使用 DeadlineSupervision 的注意事项如下:
- DeadlineSupervision 的两个 CP 必须属于相同的 SE;
- DeadlineSupervision 的两个 CP 不能相同;
- 同一 CP 可以属于不同的 Deadline Supervision;
- Deadline Supervision 监控到错误后,其 SE 的本地状态将直接切换至 EXPIRED,进而引起全局状态的切换;
- Deadline 监控的时间一般是 us 级别的,而 WdgM 的调度周期是 ms 级别的,因此WdgM 需要调用 AUTOSAR OS 提供的标准接口StatusType GetElapsedValue(CounterType CounterID, TickRefType Value,TickRefType ElapsedValue),来读取时间。如果用户未使用 AUTOSAR OS,则也必须提供兼容的接口,才能使用 DeadlineSupervision。
Logical Supervision
Logical Supervision主要用于监控应用程序的运行顺序是否正确,包括各个 SE 本地的运行路径的检查,和 SE 之间的全局路径检查。
WdogM的状态机
WdogM模块里面有两种状态机,一种是针对SE的Local Supervision Status,还有就是针对整个WdogM模块的Global Supervision Status。
Local Supervision Status
每个 SE都有一个专属独立的状态机,其状态转换关系描述如下:

| 路径编号 | 转换路径 | 转换条件 |
|---|---|---|
| 10 | 初始化-OK | 调用 WdgM_Init,并且在初始化模式中,该 SE 是使能的。 |
| 11 | 初始化-DEACTIVATED | 调用 WdgM_Init,并且在初始化模式中,该 SE 是禁能的。 |
| 3 | OK-FAILED | 检测到 Alive 错误,并且错误次数未超过门限值。 |
| 2 | OK-EXPIRED | 检测到 Alive 错误,并且错误次数超过门限值。 检测到 Deadline 或 Flow 错误。 |
| 7 | OK- DEACTIVATED | 调用 WdgM_DeInit。 调用 WdgM_SetMode,并且在新的模式中,该 SE 是禁能的。 |
| 9 | DEACTIVATED-OK | 调用 WdgM_SetMode,并且在新的模式中,该 SE 是使能的。 调用 WdgM_Init |
| 5 | FAILED-OK | 在新的调度周期, Alive 错误消失,并且计数递减到 0,并且未检测到其他任何错误。 |
| 6 | FAILED- EXPIRED | 检测到 Alive 错误,并且错误次数超过门限值。 检测到 Deadline 或 Flow 错误。 |
| 12 | FAILED- DEACTIVATED | 调用 WdgM_DeInit。 调用 WdgM_SetMode,并且在新的模式中,该 SE 是禁能的。 |
Global Supervision Status
Global Supervision Status状态切换如下图所示:

一般来说,Global Supervision Status是根据各个 SE 的本地状态来变化的,变化规则描述如下:
-
所有 SE 的状态均为 OK,或 DEACTIVATED 时,全局状态为 OK;
-
一个或多个 SE 的状态为 FAILED,其他 SE 为 OK 或 DEACTIVATED 时,全局状态为FAILED;
-
一个或多个 SE 的状态为 EXPIRED,全局状态为 EXPIRED;
-
全局状态为 EXPIRED 超过 WdgMExpiredSupervisionCycleTol 个调度周期,全局状态切换为 STOPPED。
下述情况下,也会发生全局状态切换:
-
未初始化,或调用反初始化,全局状态切换为 DEACTIVATED;
-
初始化时,全局状态切换为 OK;
-
调用 WdgIf_SetMode 返回 E_NOT_OK,全局状态切换为 STOPPED;
-
调用 WdgM_PerformReset,全局状态切换为 DEACTIVATED;
-
调用 WdgM_SetMode 时,会引起各 SE 的本地状态变化,进而引起全局状态的变化,规则同上文描述。
下面描述了当WdgM模块的Global Supervision Status状态发生切换时,WdgM会进行相关操作:
- Global Supervision Status为OK时,正常调用 WdgIf_SetTriggerCondition 刷新喂狗条件;
- Global Supervision Status切换至 FAILED 时,正常调用 WdgIf_SetTriggerCondition 刷新喂狗条件。调用 BswM_WdgM_RequestPartitionReset,可以复位部分的 APP,该功能是可选的;
- Global Supervision Status切换至 EXPIRED 时,正常调用WdgIf_SetTriggerCondition 刷新喂狗条件;
- Global Supervision Status切换至 STOP 时,调用 WdgIf_SetTriggerCondition 将喂狗条件设置为 0,调用 Dem 上报错误事件,如果使能了 WdgMImmediateReset,会立即出发 MCU复位;
- 所有的状态切换均会通知给上层。
System Service
EcuM
EcuM(ECU State Manager)模块它所管理的ECU状态特指ECU的上下电状态,因为在汽车电子中对ECU的上下电时序要求非常严格,AUTOSAR则特地为此整了一个EcuM模块来系列化这个过程。EcuM 模块位于 AUTOSAR 的系统服务层,透过 RTE 与用户直接交互,在基础软件中与 BswM、ComM 及驱动模块等交互。EcuM 模块主要功能如下:
- ECU 状态处理
- 管理系统启动流程
- 管理系统关闭流程
- 管理系统休眠、唤醒流程
- 处理唤醒源确认
- 设置 Bootloader 启动目标
[!tip]
EcuM有两种EcuMFixed和EcuMFlex,其中EcuMFlex是在 AUTOSAR4.x 之后新增的规范文件,相应地原来的 EcuM 改称为 EcuMFixed。EcuMFlex主要是为了适应不同应用场景的各种不同需求,实现更加灵活的处理。所以在AUTOSAR官方文档中,Specification of ECU State Manager (autosar.org)则对应的是EcuMFlex,Specification of ECU State Manager with fixed state machine (autosar.org)则对应的是EcuMFixed。
EcuMFixed和EcuMFlex主要区别在于 EcuMFixed 中的模式和状态是固定的,而 EcuMFlex 中删除了许多模式和状态,这些模式和状态的定义根据不同需求由 BswM 模块加以定义。因此EcuMFlex 也必须与 BswM 配合使用才能实现完整的模式和状态处理。
接下来则是介绍最常被使用的EcuM简单版EcuMFlex,至于EcuMFixed ,感兴趣的小伙伴可自行查阅资料研究。
EcuM状态机
说到状态管理,那肯定是缺不了一套帅气且稳定的状态机,EcuMFlex的状态机如下图示:

- Startup阶段: 即上电时序,上电或者Reset后则会进入Startup阶段,Startup又分为StartPreOS与StartPostOS两个阶段,顺利完成Startup后且满足条件后则进入UP阶段。
- UP阶段:此时就是相当于ECU处于正常运行状态,当条件满足时,可以根据CPU是否进入到低功耗状态还是OFF状态或者复位操作,相应进入到Sleep阶段与ShutDown阶段。这里值得一提的是,在UP阶段,ECU状态的控制切换则完全由BswM接手,也就是说EcuM只管上下电以及休眠唤醒的时序。
- Sleep阶段:在sleep阶段存在着两种CPU低功耗模式:Poll与Halt模式,后者比前者更节约电能且无需运行代码,具体采用哪个则可根据当初的系统设计而定。这里值得提一下的是,这里的低功耗模式则是那种最浅显的sleep,这个时候ECU还是有电的,CPU顶多处于打盹模式或者关闭和停止一些特殊功能。当唤醒源发生之后,ECU立马进入UP阶段。
- Shutdown阶段:即下电时序,前后会经历OffPreOS与OffPostOS阶段,前者则是为Shutdown OS之前所做的准备,后者则是关闭OS之后,选择对应的函数执行关闭ECU还是重启ECU的操作。
RUN和POST_RUN
在上面状态机切换中,多次提到了需要满足一些条件,EcuM才会切换模式,那么这里的条件指的是什么呢?那就是RUN和POST_RUN的请求和释放。
RUN和POST_RUN是用户(SW-C)对EcuM模块的两种模式请求。其中RUN 表示用户希望ECU处于正常运行状态,POST_RUN表示用户需要做休眠或关闭前的清理工作。用户需要通过 EcuM 模块接口来单独请求或释放 RUN 或 POST_RUN,而且请求和释放必须成对调用。EcuM 模块整合所有 SW-C 的请求,向 BswM 模块发起模式请求。基本规则为:
- 当至少有一个 SW-C请求 RUN 时,EcuM 向 BswM 请求系统进入运行状态;
- 当所有 SW-C 均释放 RUN,但仍有至少一个 SW-C 请求 POST_RUN 时,EcuM 向 BswM 请求进入POST_RUN 状态;
- 当所有SW-C 的 RUN 和 POST_RUN 均释放时,EcuM 向 BswM 请求系统进入关闭状态。
一般使用情况为:当用户希望正常运行时,向 EcuM 请求 RUN。当应用停止运行且希望进行一些后处理时,应该先请求 POST_RUN,再释放 RUN。EcuM 和 BswM 会根据系统整体状态在适当时机切换到 POST_RUN 状态,且通知应用可执行清理工作。当执行完清理工作后,应用调用 EcuM 接口释放 POST_RUN,则系统会进入Sleep或者Shutdown过程。
Startup阶段
上面提到Startup阶段其实就是上电流程,分为 StartPreOS 和 StartPostOS 两部分,以 OS 的启动为分界线。其实就是EcuM_Init(),那么在这个过程中,需要做些什么呢?
StartPreOS 流程
- 执行 EcuM_AL_SetProgrammableInterrupts(),主要负责关闭芯片的可编程中断,为初始化其他模块和启动操作系统做准备。如果系统启动代码已将中断关闭,则可通过配置参数将该步骤省略,否则需要在该函数中关闭中断。
- 执行 EcuM_AL_DriverInitZero(),初始化Init List 0容器里面的驱动。
- 执行 EcuM_DeterminePbConfiguration(),根据相关系统设计读取 Post-build 配置参数数据指针。
- 检查配置数据一致性,检查在上一步得到得Post-build配置数据的有效性。
- 执行 EcuM_AL_DriverInitOne(),初始化Init List 1容器里面的驱动。
- 获取上次复位原因,通过读取MCU的特殊复位原因寄存器,获取此次ECU复位的复位源,根据复位源来进行不同处理。例如复位原因是唤醒复位时,则需要执行唤醒源确认等步骤;如果复位原因是电源上电,则需要对 EcuM RAM 的一些关键变量进行初始化。
- 设置默认 Shutdown target,系统关闭有三种情况,称为三种 ShutdownTarget,分别为 SLEEP、RESET 和 OFF。SLEEP 是指系统进入低功耗状态,RESET 是指复位重新运行,OFF 是完全断电。
- 执行 EcuM_LoopDetection(),这是一个 Callout 函数。
- 执行 StartOS(),启动操作系统,入参为在 EcuM 模块配置的 OS 的 AppMode。该函数最终不会返回,因此 EcuM_Init()也不会返回。
StartPostOS 流程
在 AUTOSAR OS 中 , 需 要 配 置 一 个 自 启 动 任 务 。 在 该 任 务 中 , 需 要 调 用EcuM_StartupTwo(),StartPostOs 存在于该函数执行过程中。该函数主要执行两个操作,调用 SchM_Init()和调用 BswM_Init()。当 BswM 模块成功初始化后,后续的初始化任务由 BswM 模块完成。EcuM 的启动流程也就此结束。
Init block
在上述上电流程中,提到了Init Block。现在很多MCU对初始化外设的时序都有严格要求,所以EcuM 设计了几个驱动初始化列表以满足不同需求,分别为EcuMDriverInitListZero、EcuMDriverInitListOne 和 EcuMDriverRestartList。
- EcuMDriverInitListZero 由 EcuM_AL_DriverInitZero()实现,在获取 Post-build参数前调用。用于初始化一些公共基础模块,以及获取 PB 参数所需要的硬件模块的驱动。
- EcuMDriverInitListOne 由 EcuM_AL_DriverInitOne()实现,在获取 Post-build参数后调用。用于初始化一些具有多套配置,且不依赖于操作系统的模块。
- EcuMDriverRestartList 由 EcuM_AL_DriverRestart()实现,在唤醒后用于重启一些驱动模块。
我们可以在配置 EcuM 模块时指定每个列表中包含的驱动模块,其中InitListZero和InitListOne中的模块不能重复,而重启列表一般来讲是前两个列表的子集,其中模块的相对顺序必须与前两个列表一致。
Shutdown阶段
上面提到Shutdown阶段其实就是下电流程,其实就是Startup阶段的逆操作,关闭流程通过调用 EcuM_GoDown()触发。只有指定模块才能触发该流程 ,为此用户需要在配置工具上添 加EcuMGoDownAllowedUsers 并添加一个或多个用户。调用该接口时传入用户 ID。关闭过程分为 OffPreOS 和 OffPostOS 两个阶段,以OS 的关闭为分界线。
OffPreOS 流程
OffPreOS 流程主要完成以下几个主要动作:
- 执行 EcuM_OnGoOffOne(),这是一个集成代码,主要负责处理一些关闭前的特殊操作。需要根据芯片特性填充功能。
- 执行 BswM_Deinit(),反初始化 BswM 模块。
- 执行 SchM_DeInit(),反初始化 SchM 模块。
- 检查唤醒事件,如果在关闭过程中发生挂起或确认的唤醒事件,则系统需要响应唤醒。所以若当前 Shutdown Target 为 OFF,EcuM 会将其更改为 RESET,即在执行完后续的关闭动作后将处理器复位,从而再次启动。若没有发生唤醒事件,则正常执行关闭流程。
- 执行 ShutdownOS(),关闭操作系统。该函数会清理操作系统中的一些资源,最终调用ShutdownHook()。
OffPostOS 流程
我们需要在函数ShutdownHook()中调用EcuM_Shutdown(),OffPostOS 流程则是在 EcuM_Shutdown()中实现。OffPostOS 流程分为两个步骤:
- 调用EcuM_OnGoOffTwo()。用户可以在其中调用不依赖于操作系统的模块的反初始化或清理工作。
- 根据前面设置的 Shutdown Target , 分别调用EcuM_AL_Reset() 或EcuM_AL_SwitchOff()。用户需要在这两个函数中分别调用驱动来实现系统复位或关闭电源等工作,自此ECU完成Shutdown流程。
Sleep和WakeUp
为了实现低功耗模式,在UP阶段,当应用软件不再执行操作,且在总线上满足休眠条件时(如CAN 网络的远程休眠条件满足),系统将进入休眠模式。这个休眠发起人BswM模块,而执行者则是EcuM模块,纯纯苦逼打工人。
在休眠前,需要调用 EcuM_SelectShutdownTarget()将休眠模式设置为 SLEEP,且需要设置具体的休眠模式。根据硬件芯片的不同,有些芯片可以处于不执行代码的状态,有些芯片会处于仍然执行代码的低频模式。需要根据这些硬件差异选择调用EcuM_GoHalt()或 EcuM_GoSleep()函数使 MCU 处于低功耗状态。进入休眠状态有三个步骤:
- 预处理步骤
- 休眠步骤
- 唤醒重启步骤。
预休眠步骤
在预休眠步骤中,EcuM 首先会调用 BswM 模块接口报告唤醒源状态。然后 EcuM 模块要使能唤醒源以备将来的休眠。这是通过调用 EcuM_EnableWakeupSources()函数实现的。在该集成代码中,用户需要判断入参中每个比特,调用相应驱动的相应函数来将每个唤醒源使能。之后 EcuM 会调用 OS 的接口函数 GetResource()锁定调度功能,以备在将来唤醒中断处理完后仍然能返回当前进入休眠的任务中执行唤醒操作。
休眠步骤
上面提到Sleep分为两种模式,分别是Halt模式和Poll模式。
-
Poll 模式休眠步骤
Poll 模式下 CPU 仍然执行代码,但以较低主频运行。这时 EcuM 将不停执行两个动作:调用 EcuM_SleepActivity()和调用 EcuM_CheckWakeup()。其中EcuM_SleepActivity()为集成代码,用户可以在其中执行低功耗状态下运行的工作。EcuM_CheckWakeup()也是集成代码,用户在其中根据入参遍历唤醒源,调用唤醒源驱动接口检查是否发生唤醒事件。如果发生唤醒事件,唤醒源应当调用EcuM_SetWakeupEvent()通知 EcuM。EcuM 会在检查完成后发现唤醒事件,触发唤醒步骤。
-
Halt 模式休眠步骤
Halt 模式下 CPU 不再执行任何代码。在此模式下,为了防止可能出现的 RAM 内容破坏,EcuM 会调用 EcuM_GenerateRamHash()计算 RAM 的校验值。在EcuM_GenerateRamHash()中用户需要自行对关键内容计算检验并保存。之后 EcuM 会调用 MCU 驱动进入休眠模式,CPU 会停止处于打盹模式,只有唤醒中断会将 CPU 重新置于运行状态。并且触发唤醒重启步骤。
唤醒重启步骤
发生唤醒事件后,EcuM 会执行唤醒重启。首先恢复 MCU 为正常模式,然后获取唤醒源,并将已确认和已挂起的唤醒源禁止,保留其他唤醒源以备稍后唤醒。最后调用 EcuM_AL_DriverRestart()执行重启驱动列表,解锁操作系统的调度器。
在驱动重新初始化过程中,驱动应当检测是否自己是触发本次唤醒的唤醒源,如果是,则最终会调用 EcuM_SetWakeupEvent()通知 EcuM。执行完唤醒重启步骤后,系统进入 UP 状态,有些唤醒源仍需要验证有效性。
有些唤醒源会产生虚假唤醒事件,如电平跳变导致 CAN 收发器或 IO 唤醒。有些唤醒源需要在特定情况下才能真正唤醒,如系统只允许 CAN 网络管理报文唤醒节点,不允许应用报文唤醒。这些期望之外的复位源则需要使用 EcuM 模块的唤醒确认功能对唤醒源进行有效性确认和过滤,这也要求用户必须根据ECU的软硬件设计完成唤醒源确认策略设计。
进入Bootloader
在 ECU 需要重编程时,诊断仪与 Dcm 模块交互,设置 Bootloader 重编程有效标志后复位。
在AUTOSAR中实现该流程 ,需要由应用层调用 EcuM 模块的EcuM_SelectBootTarget()函数来记录下次启动的引导目标是应用、OEM Bootloader 还是System Bootloader。具体流程为:
- 诊断仪发送请求切换编程会话;
- Dcm 模块先通过Rte向应用请求复位 ,应用调用 EcuM 模块EcuM_SelectBootTarget()函数设置复位启动目标;
- Dcm 向诊断仪发送 0x78 响应;
- Dcm 调用集成代码的接口,用户在集成代码中设置 Bootloader 的重编程有效标志;
- Dcm 通知 App 可以执行复位;
- 当 App 完成复位前的清理工作后,请求 EcuM 复位。在 Shutdown阶段中最后调用 EcuM_AL_Reset() 时 , 应当调用EcuM_GetBootTarget()来获取当前引导目标。并根据与 Bootloader 的交互协议设置相应标最后触发复位操作。
Alarm Clock
EcuM 模块可以定义一个系统时间,基于 GPT 从上电复位开始以秒为单位运行。用户可以调用 EcuM_GetCurrentTime()获取系统自上电以来的运行时间。该时钟在休眠状态下仍然能正常运行,因此用户还可以用以作定时唤醒源来唤醒系统。
BswM
上一节介绍了一个非常夸张的EcuM模块,其中多次提到了BswM模块,这两个模块通常狼狈为奸,共同策划且并操作了整个ECU的状态切换。细细研究EcuM模块后就会发现它是比较别动的,都是当一些条件满足或者事件发生时,EcuM才会控制系统进行状态切换,它更像是一个大兵,只会吭哧吭哧干活,而这一节的BswM模块则是真正的指挥。
BswM 模块位于 AUTOSAR 基础软件架构中的服务层,实现对 BSW层和 SW-C的模式管理。BswM的处理流程如下图所示:

BswM 模块主要提供两项功能:
- 模式仲裁:模式仲裁是把各个 BSW 模块和 SW-C 模块的模式请求和模式指示收集起来,按一定的模式规则进行计算,得到仲裁结果。
- 模式控制。模式控制是指根据仲裁结果,调用不同的动作列表,在动作列表中调用各个模块的函数或接口。
模式仲裁的规则和模式控制的动作列表都是用户可配置的,因此 BswM 的功能极大程度上依赖用户配置。
在上面提到BswM主要就是干两个事情,一个是模式仲裁,一个则是模式控制。
模式仲裁
-
ModeRequestPort:每个 BSW 模块或 SW-C 都可以通过 API 或服务向 BswM 报告或者申请状态,这里提到的接口或服务称为端口(Port),而状态则被称为模式(Mode)。申请状态则被称为模式请求(Mode Request),报告状态则被称为模式指示(Mode Indication)。模式请求通常来源于SW-C,也有可能来源于BSW模块,比如Dcm模块;模式指示则总是由BSW模块发出,比如<bus>Sm模块,EcuM模块等。每个端口需要配置一个默认模式,如果未配置则视为未定义。端口和模式两者拼合起来那就是ModeRequestPort。 -
ModeCondition:模式条件(ModeCondition)是模式仲裁时候的最小判断单元,如果模式条件关联了一个ModeRequestPort,则该条件会验证请求的模式或者指示的模式是否EQUAL或者NOT_EQUAL于某个模式,然后每一个ModeCondition判断完成后会返回TRUE或者FALSE。 -
Logical Expressions:使用AND、OR、XOR、NOT和NAND这些逻辑符将ModeCondition组合起来就是一则逻辑表达式,即Logical Expressions。 -
Rules:Rules就是当一则Logical Expressions计算结果为真后,BswM模块应该要采取什么样的措施,将措施和Logical Expressions对应起来,这就叫一条Rule。当模式发生变化时(这种叫做BSWM_IMMEDIATE)或者在BswM主函数运行时(这种叫做BSWM_DEFERRED)就会对Rules进行评估,评估Rules的这个过程即叫做模式仲裁,模式仲裁满足条件之后,则开始进行模式控制。下图就是一条简单Rule的的仲裁:
模式控制
-
Action和Action List:在前面模式仲裁的Rules中,提到了当一条Rule评估满足条件后BswM模块会执行相应的措施,这里的措施在模式控制中称为Action List。Action List是一组有序的Action,BswM 按顺序依次执行动作列表中的每个元素。元素有三种类型:-
一个特定的动作(函数),BswM 会简单地执行该动作;
-
指向其他Action List的链接,BswM 将从被指向的Action List起始处依次执行到最后一条元素,这意味着Action List可以级联;
-
指向一条Rule的链接,BswM 对该Rule进行运算,根据结果执行其对应的Action List。

如果Action List的某一条Action执行失败,则根据其属性 BswMAbortOnFail 决定是否继续执行。若配置为真,则中止整个Action List的执行;若配置为假,则继续依次执行后续的Action项。如果Action List配置了 BswMReportFailToDem,则 BswM 会在动作执行失败时向 Dem 模块报告事件,该事件需要在 BswM 模块中预先配置。
基于Rule评估,动作列表有两种方式被执行:- BSWM_CONDITION:条件执行,即每次评估规则时被执行。
- BSWM_TRIGGER:触发执行,即每次评估结果发生变化时才执行。
如果为触发执行配置了一个True的动作列表,则BswM仅在相应规则的评估从False变为True时才会执行此动作列表。如果为触发执行配置了一个False的动作列表,则BswM仅在相应规则的评估从True变为False时才会执行此动作列表。如果为条件执行配置了一个True的动作列表,则BswM应在每次将相应规则评估为True时执行此动作列表。如果为条件执行配置了False的动作列表,则BswM应在每次将相应规则评估为False时执行此动作列表。
-
-
SwitchPort和RteModeRequestPort:RteModeRequestPort请求端口是请求更改应用程序模式,而SwitchPort是在BswM执行模式更改时用来接收通知。
OS
这一节来介绍一下OS的一些小点点,这一章都是文字,估计比较枯燥乏味。对OS基础不太了解的朋友,这里推荐两篇网上好文:《 AUTOSAR基础篇之OS(上) 》,《 AUTOSAR基础篇之OS(下) 》。
AUTOSAR OS为了适应各种各种样的芯片,所以它需要良好的可扩展性来做支撑,说得简单点就是OS的功能可被灵活裁剪,AUTOSAR则根据功能扩展分成了四种扩展类型,分别是SC1 ~ SC4,其主要区别为:

OS 基础
Startup和Shundown
OS 操作系统的启动是通过调用“StartOS()”函数来实现。在标准的 AUTOSAR 项目中,StartOS 函数由 EcuM_Init 调用。OS系统可以设定不同的应用模式,用户可以在不同的应用模式下运行不同的应用程序,从而在不同的条件下实现不同需求,需要给StartOS指定应用模式参数。 OS系统支持多种应用模式共存,并提供配置选项供用户在系统配置阶段建立和选择所需的应用模式。一旦操作系统启动,应用模式就不能再更换,也就是说在系统运行过程中动态切换应用模式是不允许的。
StartOS()会对OS内部各组件进行初始化,激活自启动任务、报警或调度表。StartOS()的最后,会启动系统定时器,并触发第一次 任务调度 。如果用户使能了相关 Hook,StartOS 会在所有初始化完成之后,启动系统定时器、触发第一次任务调度之前,调用用户的 Hook,调用顺序为:
- 调用 OsStartupHook,
- 调用各个 OS-Application 的 OsAppStartupHook。
OS 操作系统的关闭是通过调用“ShutdownOS()”函数实现。“ShutdownOS()”函数会禁能所有中断,停止系统定时器运行,最终进入死循环。如果用户使能了相关 Hook,ShutdownOS 会在进入结尾处,进入死循环之前,调用用户的 Hook,调用顺序为:
- 调用各个 OS-Application 的 OsAppShutdownHook。
- 调用 OsShutdownHook。
Task
OS 中任务的优先级是静态配置的,并且在系统运行过程中不会改变。任务优先级配置时,号码越大所标识的优先级越高,优先级 0 为系统的最低优先级。用户应按照这一原则制定和分配任务优先级。高优先级的任务先执行,相同优先级的任务遵循 FIFO (先进先出)的规则。
当 OS 符合类为 BCC1 或 ECC1 时,不支持任务的多次激活,不支持为不同的任务分配相同的优先级。因此每个优先级上有且只有一个任务。当 OS 符合类为 BCC2 或 ECC2 时,支持任务的多次激活,支持为不同的任务分配相同的优先级。此时 OS 会为每个优先级创建任务队列,队列深度与该优先级上任务的个数和最大激活次数相关。
OS根据任务是否会抢占有三个不同的配置,分别是:
- 在完全抢占调度策略下,所有 OS 的任务均为可抢占的。高优先级任务会抢占低优先级任务。
- 在完全非抢占调度策略下,所有 OS 的任务均为不可抢占的。任何任务在运行时,都不会被其他任务抢占。
- 在混合调度策略下,用户可配置任务是否可抢占。
OS 中所有的任务都是静态配置的,在系统启动时就已经存在了。
可以使用系统服务函数“ActivateTask()”或“ChainTask()”来激活一个任务。
-
系统服务函数“ActivateTask()”将处于挂起状态的任务转换为就绪状态,如果在某任务运行过程中调用了 ActivateTask(),且当前任务为可抢占任务,则ActivateTask()会基于优先级进行任务调度。如果当前任务为不可抢占任务,则ActivateTask()不会触发调度。
-
系统服务函数“ChainTask()”会终止当前正在运行的任务,同时激活一个新任务,然后会触发一次系统调度。
[!tip]
在真实应用,其实这两个函数用的不多,瞎勾吧用的话会对系统任务的运行状态造成不可控的时序因素。一般就是使用ActivateTask()来激活Extended Task,Extended Task只需要激活一次,Extended Task启动后,然后就是处于 WAIT 状态等待event,event发生执行后再次等待下一次event;而Basic Task则需要用Alarm来周期性激活,因为Basic Task每次运行完都需要调用TerminateTask()进入阻塞态。其实简单来说,Extended Task像是一个死循环,而Basic Task更像是一个Callback。
如果操作系统的符合类被配置成 BCC2 或者 ECC2,那么系统将支持任务的多次激活。系统中只有Basic Task能够进行多次激活,Extended Task只能激活一次。所以在配置Basic Task的时候都会配置一个参数叫做Task Activation,意思就是多次激活的次数限制,比方说一个Basic Task1被设置成5ms激活一次,但是此时OS被一个高优先级的任务block住没有时间来运行这个Task,那么这个任务就会出现被激活多次但是没有执行一次的情况,而这里的Task Activation则是限制这个被激活的次数,一旦超出这个次数,则OS会报错。
Counter
OS 中有两类计数器:SystemCounter 和 UserDefinedCounter。
- SystemCounter 指的是操作系统所使用的系统计数器,
- UserDefinedCounter 指的是用户自行设定的、通常用于应用软件的计数器。
SystemCounter默认必须存在,该计数器只能通过 SystemTick 进行触发,用户不可修改。Tick 是指 SystemCounter 的计数基值。硬件定时器多久产生一个 Tick 是由 TickTime 确定,TickTime 的单位为μs,默认值为 1000μs。用户可以在配置工具中根据需求对 TickTime 的大小进行配置。为实现 SystemCounter,OS 会占用一个硬件定时器来周期性地产生 System Tick。OS会自动创建该硬件定时器的中断,用户可以更改定时器中断的优先级。
除 SystemCounter 外, OS 支持用户自定义的 counter。用户自定义的 counter 没有固定触发源,用户需要调用 IncrementCounter 触发自定义Counter 增加。例如在周期任务或其他的定时中断中调用,也可使用 Alarm 触发自定义 Counter,Alarm 的动作中可选择IncrementCounter。
Alarm
Alarm相当于是一个软件定期器,可以使用Alarm进行定时,定时时间到后,执行相应的动作。Alarm支持的动作有:
- 激活一个任务;
- 设置一个事件;
- 运行一个Alarm Callback函数;
- 累加一个User Defined Counter。Alarm Callback只在 SC1 中提供。
有两种方法可以启动 Alarm,自启动的 Alarm在OS启动后就自动开启了。对于非自启动的 Alarm,用户需要调用 SetAbsAlarm()或SetRelAlarm()启动报警,设置报警的启动时间和周期。 SetAbsAlarm()和SetRelAlarm()的区别在于是相对延时还是绝对延时。
Resource
OS 提供了Resource管理功能,用于解决任务或中断同时访问共享Resource时的协调问题。共享Resource可以是应用程序段、内存空间或者硬件外设等。OS 的Resource管理机制可以防止Resource死锁,任务优先级反转等问题。
GetResource()和ReleaseResource()用来进行锁住和释放Resource。这个时间就会出现优先级反转的情况,这样做是为了避免两个不同优先级任务访问相同Resource而出现互锁的情况,具体做法为:任务或中断调用 GetResource 获取Resource时,OS 会将任务或中断的优先级提升至最高优先级。之后,访问该Resource的其他任务或中断将无法抢占当前任务,直到该Resource被释放,Resource被释放时,OS 将会恢复该任务或中断的原先优先级。
因为任务的优先级为软件优先级,而中断的优先级为硬件优先级,这两种优先级不在一个层次,所以如果当一个Resource是任务和中断共享的,当该Resource被任务获取后,OS 将会锁定调度(所有任务和二类中断都不能抢占当前任务,包括与当前Resource无关的任务和二类中断),这样做是为了防止使用该Resource的中断被锁定的时间过长。
Event
Event用于实现系统内不同的实体之间的同步,包括任务与任务进行同步或是任务与中断服务函数进行同步。只有扩展任务可以调用 WaitEvent 等待Event,调用 WaitEvent 后,任务不再运行,进入WAIT 状态。
任务和二类中断中可以调用 SetEvent 设置事件,另外Alarm,Schedule Table 也可以配置设置事件的动作。设置事件后,等待该Event的任务将恢复至 READY 状态。然后 OS 会基于当前系统的抢占策略,任务优先级的情况,确定何时恢复任务的运行。每个扩展任务支持最多 32 个事件。WaitEvent 和 SetEvent 均可以等待或设置多个事件。
Interrupt
中断对整个MCU的重要程度不言而喻,连OS的基本架构都是基于三个中断来实现的。光拿对于中断的应用来说非常简单,其实就是配置中断处理函数的名称,在中断触发后,OS 经过预处理之后,会调用该处理函数。中断处理函数由用户实现。但是要是将中断合理的使用,使用的稳定还是需要对中断的机制要有一定的了解,不然就会出现一大堆问题。
AUTOSAR OS 将中断分为一类中断和二类中断。其中一类中断就比较简单粗暴,它跟传统意义上的中断执行是一样的,中断发生后直接打断当前运行任务(支持中断嵌套的话,也可以打断低优先级中断),然后运行中断服务函数,运行完之后直接回到打断处的地方继续运行;而二类中断则在结束后会触发任务调度,让任务调度来决定去哪里执行。
所以根据上面的区别,一类中断和二类中端触发时,两者所干的事情有所区别。对于一类中断来说,运行流程为:
- 中断发生,打断当前运行状态
- 保存恢复现场
- 切换 OS Context
- 调用用户的处理函数
- 退出中断,回到原先状态继续执行
一类中断对于整个OS来说,纯纯粹粹就是一个强硬中断。正因为一类中断的简单粗暴,所以在使用它的时候,需要考虑的因素就比较多:
- 在一类中断中,有很多涉及到OS操作的函数以及特征都不能被调用,比如一类中断不支持Resource;
- 一类中断运行时,其内存访问权限和 OS 内核是一致的(最高权限);
- 一类中断没有独立的栈,其使用的是被其打断的任务或中断的栈。
- 如果任务或二类中断使能了时间保护,一类中断不会暂停时间保护的计时。
对于二类中断来说,运行流程为:
- 中断发生,打断当前运行状态
- 保存和恢复程序上下文。
- 切换 OS Context。
- 记录中断嵌套的信息。
- 处理被打断任务或中断,以及当前中断的时间保护。
- 切换内存访问权限。
- 切换堆栈。
- 调用用户服务函数。
- 退出中断,并触发任务调度, 如果当前有中断嵌套,则恢复程序上下文,恢复至被打断的中断。如果无中断嵌套,且没有更高优先级的任务被激活,则恢复程序上下文,恢复至被打断的任务。如果无中断嵌套,但有更高优先级的任务被激活,则切换至新的任务。
二类中断对于整个OS来说,则就相当于一个特殊Task了,它的开关是受OS控制的,但是也只就局限于开和关,二类中断的触发一般通过硬件来自动触发。一当OS调度被挂起,那么二类中断就会被屏蔽,不会被触发。
Schedule Table
调度表可以帮助用户更方便的实现一系列具有时序要求的动作。首先说一下EP(Expiry Point),它相当于一个时间点执行对象,当时间到了,Schedule Table就会去执行这个EP,EP可触发多个Task或者触发多个Event,而一个Schedule Table 可配置多个 EP(Expiry Point)。 Schedule Table 可以配置为单次触发运行,或者周期运行,OS可支持同时运行多个调度表。 Schedule Table的EP执行规则由两个参数决定,分别是整个Schedule Table的Final Delay参数,还有每一个EP的Initial Offet参数,所以当一个调度表被启动后,它的运行流程如下:

首先在Tick 0处Schedule Table被启动,然后根据每一个EP的Initial Offet来决定EP的执行时刻,当最后一个EP执行后,最后等待Final Delay个Tick,整个Schedule Table运行结束如果Schedule Table配置成重复启动,那么此次运行后立即启动下一次Schedule Table的运行。
OS Context
OS Context就是当前OS所处的状态,这里的状态其实就是当前程序运行到哪里了,比如说Task内, 一类中断内,二类中断内,还是各种Hook内。不同的状态下,OS所能做的事情也是不一样的,所能做的事也可以简单的理解成能不能调用某些常用OS函数。具体如下图所示:


普通监测功能
在一般的AUTOSAR OS中,一般需要提供以下几种监测手段:
- 堆栈检测将进行栈初始化,并且当发生栈溢出的错误现象时,可以及时告知用户并最终执行关闭 OS。当退出二类中断、退出任务时,系统会进行堆栈溢出检测,即检查当前中断或任务是否将预先配置的栈全部使用耗尽。
- 系统提供 CPU 负载计算功能,调用相关函数,获取最近一次该周期内的系统负载率。
- 当 OS 内部检测到故障后,OS 会将错误信息记录,比如传参错误,状态错误,总之就是导致函数未正常运行下去的各种错误。还可以定义用户Hook,当检测到错误时,可执行Hook函数。
OS SC2
SC2类主要在SC1的基础上增加了时间保护功能,其主要保护的对象是OS所能管理的,即Task和二类中断,主要提供了三个保护手段,分别是
- 任务和二类中断执行时间的保护;
- 任务和二类中断最小执行时间间隔的保护;
- 任务和二类中断锁定时间的保护。
Execution time protection
执行时间保护简单点来说就是监测Task和二类中断不能运行的太慢,其运行的时间不能超过限值,执行时间保护包括任务预期执行时间的保护和中断预期执行时间的保护。主要有以下两点:
- 如果任务或中断运行时间超出了其预期时间, OS 将会执行 ProtectionHook()函数,参数为E_OS_PROTECTION_TIME。
- 当任务或中断被打断时,系统会停止任务或中断的执行时间计时,直到该任务或中断被恢复,系统继续对其执行时间计时。对于扩展任务,其状态由 RUNNING 转换成WAITING 时,系统会停止其执行时间计时,当其等待的事件被成功设置后,重新开始该任务的执行时间计时。
Inter -arrival time protection
间隔时间保护说简单点就是监测Task和二类中断的不能运行的太快,其运行的频率不能高于限值,间隔时间保护包括任务间隔时间的保护和中断间隔时间的保护。主要有以下三点:
- 如果尝试在小于任务时间间隔内再次激活任务,OS 将会调用 ProtectionHook()函数,其参数为 E_OS_PROTECTION_ARRIVAL。如果用户在 Hook 函数中返回 PRO_IGNORE,那么 OS 将会再次执行激活任务,否则不会执行真正的激活。
- 如果用户尝试设置一个事件,但是相应的扩展任务运行间隔小于任务间隔时间,那么 OS 会调用 ProtectionHook()函数,其参数为 E_OS_PROTECTION_ARRIVAL。如果用户在 Hook 函数中返回 PRO_IGNORE,这个事件将会被设置成功,OS 将执行该扩展任务。
- 如果一个二类中断发生的频次小于中断间隔时间,那么 OS 将不会执行该中断的用户处理函数,同时调用 ProtectionHook()函数,其参数为 E_OS_PROTECTION_ARRIVAL。如果用户在 Hook 函数中返回 PRO_IGNORE,该中断仍可被执行。
Locking time protection
锁定时间保护说简单点就是去监测任务和二类中断在运行过程中,执行一个操作的时间不能超时,这里的操作时间包括:
- 获取Resource的时间,GetResource()。
- 禁用全局中断的时间,SuspendAllInterrupts()/DisableAllInterrupts()。
- 禁用二类中断的时间,SuspendOSInterrupts()。
注: 当Execution time protection和 不同操作类型的Locking time protection在一个任务或者二类中断中同时使能了的话,以两者的最小值为准。
OS SC3
SC3在SC1的基础上增加了OS-Application,
OS-Application
前面提到的Task, ISR, Counter, Alarm, Schedule Table, Resource等玩意在AUTOSAR OS中称为Object, 然后AUTOSAR OS又提出了一个OS-Application的概念,这个玩意就是一个容器,可以在不同的OS-Application容器放置不同的Object。
OS-Application 分为两种:
- 可信的,可信的 OS-Application 可以不受限制地访问内存。
- 不可信的。不可信的 OS-Application则需要配置其可访问的内存范围。
系统中如何划分 OS-Application,取决于功能安全的分析。而对于Object,则需要配置其属于哪个OS-Application以及它可以被哪个OS-Application访问。结合这两点,则就可以实现一种权限访问监测手段。
Service Protection
Service Protection其实就是制定了一些OS使用规则,防止OS-Application错误的使用了相关OS函数而造成了OS不稳定。主要包含这几种情况:
- 参数无效或超出范围,系统 API 的对象无效(比如,该对象未被配置),则返回E_OS_ID,参数超出范围(比如,设置一个 Alarm 但 cycle 参数小于 OsCounterMinCycle)则返回 E_OS_VALUE。
- 在不合理的上下文调用 API,在OS Context中不合理的调用 API,则 API 返回 E_OS_CALLEVEL。具体规则详见前面的OS Context。
- 具有未定义行为的服务,这个保护的场景只要是:有些OS函数虽然被调用了,但是其检测到当前情况不合理,那么就会直接跳出,并不会实际执行,又或者是当发生OS Context时,OS应该需要做什么,但是你没做的话,OS会自动做。
- 不可信应用中的服务限制,OS 会忽略来自不可信应用对 ShutdownOS()的调用。
- 不同 OS-Applications 之间的 Objects 调用,如果 OS API 的参数是一个系统对象,但是该对象未被配置响应任务或中断的访问权限,那么系统 API 将返回 E_OS_ACCESS。
Memory Protection
OS 提供内存保护功能,为每个任务/二类中断/OS-Application 配置指定的内存区域,并在访问越界时触发保护中断,从而确保系统的正常运行。每个任务/二类中断都有一个私有数据和堆栈空间,其他任务/中断无法访问这些数据和堆栈空间。OS-Application 还可以有一个私有数据区域,当前 OS-Application 中的任务/二类中断可以访问该区域,其他 OS-Application 的任务/二类中断无法访问。
IOC
由于内存保护的存在,不同的 OS-Application之间的数据访问是受到OS管制的,所以OS 提供了 IOC 通道,实现 OS-Application 间的数据传递。在一些多核处理器上,不同核的OS-Application之间的通讯则需要将核心间通信能力整合到 IOC 中。
Trusted Function
不可信 OS-Application 不允许访问其他 OS-Application 的数据,但在某些系统中,有一些不可信的 OS-Application 需要使用其他 OS-Application 服务。操作系统为可信应用提供了一种将其某些服务导出到不可信应用的方法。这称为Trusted Function。
OS SC4
OS SC4是SC1, SC2, SC3的机会,即包含完整的AUTOSAR OS功能。
MultiCore
MultiCore Startup
内核的启动方式在很大程度上取决于硬件。通常,硬件只启动一个核心,称为主核心,而其他核心(从核)保持在停止状态,直到它们被软件激活。AUTOSAR 多核操作系统规范要求系统具有主从启动行为,可以由硬件直接支持,也可以由软件模拟。在多核中,在核上执行 StartOS 之前,必须激活 AUTOSAR 使用的每个从核。根据硬件的不同,可能只能从主设备激活可用内核的一个子集。从核可能会在调用 StartOS 之前激活其他核心。在 StartOS 的最后,会进行多核启动的同步。所有核都启动后,才会同步触发每个核
的首次的任务调度。
AUTOSAR 支持两种系统关闭概念,同步关闭和单独关闭概念。同步关闭由 API 函数 ShutdownAllCores()触发,而单个关闭由 API 函数 ShutdownOS()调用。如果具有适当权限的任务调用“ShutdownAllCores”,则会向所有其他 Core 发送一个信号,以引导关闭过程。
在多核概念下,Spinlock 机制用来支持不同核心上的任务互斥。Spinlock 是一种繁忙的等待机制,它轮询其状态直到它变为可用。使用GetSpinlock()函数占用一个 Spinlock,如果 Spinlock 已经被占用,GetSpinlock()将继续尝试占用 Spinlock,直到成功为止;使用TryToGetSpinlock()函数占用一个 Spinlock,如果 Spinlock已经被占用,TryToGetSpinlock()将返回;使用 ReleaseSpinlock()函数释放被占用的自旋锁。如果多个 Spinlock 存在嵌套使用的情况,则需要考虑使用顺序,防止死锁。
IPC(核间通信)是多核OS中一个最重要的一个环节,这一般跟芯片外设强相关。
Memory Stack
NVM
memory stack结构如下:

再细致一点如下图:

Memory Stack也是非常完整的一个AUTOSAR结构,有服务层的NvM模块,有ECU抽象层的Fee模块和Ea模块,还有MCAL层的驱动。其中NVRAM Manager模块是整个Memory Stack的控制器,它更多的关注于数据本身的,对数据进行校验,读写操作的发起,而根据最终存储器类型的不同,则最终负责数据存储和读写操作的则是Fee模块(FLASH)和Ea模块(EEPROM)。而在MCAL层则根据是内部FLASH,外部FLASH,外部EEPROM的各种情况而灵活变化。
[!tip]
大家如果想更深入了解NvM模块,请参考AUTOSAR官方文档Specification of NVRAM Manager (autosar.org)。
补充2:除了以上简单介绍的几大点,MemIf模块还有一大堆的细节,大家如果想更深入了解MemIf模块,请参考AUTOSAR官方文档Specification of Memory Abstraction Interface (autosar.org)。
NvM 模块位于 Memory Stack 的服务层,实现了对ECU中Non-Volatile数据的统一管理。NvM 模块主要功能如下:
- 将不同类型的存储器(Flash、EEPROM 等)进行统一管理,提供AUTOSAR 标准服务接口
- 提供以 Block 为单位的读、写等服务
- 基于优先级的数据块访问机制,提高用户访问的灵活性和实时性
- 提供访问任务的队列
- 工作请求异步处理
- 提供 CRC 机制,保障数据的一致性
- 提供数据故障恢复机制
- 提供任务完成通知机制
Block
这里的Block可不是FLASH里的那个硬件Block,这里的Block是一种软件层面上的玩意,它是NvM操作的数据基本单元,也就是说,NvM模块里面操作的对象就是Block,所以在AUTOSAR里想要存储数据,那么就要提前给数据分配Block。
NvM 支持三种类型的 Block,分别为:
- Native Block:最常用的 Block,用于一般数据的管理;
- Redundant Block:该 Block 支持数据冗余,可用于对一些安全性要求较高的数据进行管理,其实就是可以对其进行备份的Block。
- Dataset Block:该 Block 支持同一类型的多套数据。用户可以根据当前的运行状态,选择使用多套数据中的一套。
每个 Block,又由以下几个部分组成:
- NV Block:位于掉电不丢失的设备,如 Flash,用于正常的存储数据;
- RAM Block:程序运行时,用户的应用程序直接访问的 Block,有点类似于缓存,当条件满足时会将其更新至NV Block。
- 临时 RAM Block:在运行时,用户通过接口将 RAM 的地址传递给 NvM;
- 永久 RAM Block:用户配置给该 Block 的固定的 RAM 地址,运行时不可改变。
- ROM Block:存储该 Block 的默认值,位于掉电不丢失的设备,当 NV Block 的数据异常时,可恢复为默认值;
- Administrative Block:管理 Block,一般位于 RAM 中,用于记录和存储程序运行时 Block的状态,如地址、CRC 结果、Block 状态等。Administrative Block 由 NvM 内部实现,不用关心。
不同类型Block的组成情况如下表所示:
| 类型 | NV | RAM | Administrative | ROM |
|---|---|---|---|---|
| NATIVE | 1 | 1 | 1 | 0 ~ 1 |
| REDUNDANT | 2 | 1 | 1 | 0 ~ 1 |
| DATASET | 1 ~ 256 | 1 | 1 | 0 ~ 256 |
此外NvM 内部还会预留 2 个特殊 Block,Block0 和Block_CfgID。其中Block0 不存储任何实际数据信息,仅用于记录 WriteAll 和 ReadAll 的工作结果,Block_CfgID 则用于存储当前内存的配置信息。用户实际使用的 Block 从第 3 个 Block 开始。
在NvM模块的下层模块Fee和Ea模块中,它们的基本数据存储单元也叫做Block,NvM模块的Block数据来源于Fee和Ea的Block,前面提到了NvM的三种Block由若干个NV Block组成,所以这两种Block是一对多的情况。NvM的Block编号叫做Block Handle,Fee和Ea的Block编号叫做Block ID,也就是说APP通过Block Handle来索引NvM的数据,而NvM则是通过Block ID来索引Fee和Block的Block数据。
Block ID 的计算公式为:
$$
Block ID = (Block Base Num << DataSelectionBits) + DataIndex
$$
其中Block Base Num根据Blocl类型而定(Native,Redundant ,Dataset ),DataSelectionBits和DataIndex根据具体应用情况进行设置。其中当 NvM 调用 MemIf 的接口,访问 Fee 或 Ea 时,传递的 Block 参数为 Block ID。
数据结构
Block三种组成成分Block的存储数据格式如下:

其中 RAM 和 NV Block,都有可选的 Header 和 CRC 区域。Header 可用于存储 Block 的Block ID 信息,固定占用两个字节的信息,CRC 区域用于存储 Block 的 CRC,根据 CRC 的类型,占用 1、2 或 4 个字节。ROM Block 仅存储默认数据,不存储 Header 和 CRC 内容。用户在读取和写入数据的时候,不需要关心 Header 和 CRC,NVM 模块将自动对 Header 和 CRC进行填充、计算、校验等工作。
Redundant Block
前面提到了Redundant Block 有 2 个 NV Block,其主要特点包括:
- 在 Write、WriteAll 中,将向 2 个 NV Block 写入同样的数据,只要有其中一个 NV Block写入成功,则写数据成功;
- Erase、Invalidate 工作中,将对 2 个 NV Block 进行操作,只有对 2 个 NV Block 的操作都成功,请求才成功;
- 在 Read、ReadAll 中,将首先读取第一个 NV Block 的数据,如果读取失败,再读取第二个 NV Block 的数据。只要其中一个 NV Block 读取成功,则读数据成功,用户可以使用 RAM Block 中的数据。如果第一个 NV Block 读取成功,则不会再读取第二个 NVBlock 的数据。
Dataset Block
Dataset Block 可以具备多个 NV Block 和 ROM Block,具体的数量限制与用户配置的NVM_DATASET_SELECTION_BITS 有关系。
假设 NVM_DATASET_SELECTION_BITS 为 n,n 小于等于 8。则 NV Block 的个数范围为0 ~ 2^n,而 ROM Block 的个数范围为 0 ~(256-2^n),NV Block 的个数与 ROM Block 的个数总和不能超过 2^n。
在访问 Dataset 类型的 Block 之前,必须先调用 NvM_SetDataIndex 设置目标的 DataIndex,DataIndex 的范围必须注意下述条件:
- DataIndex 不超过 NV 和 ROM Block 的总和;
- 假设配置了 m 个 NV Blocks,n 个 ROM Blocks,则 0 ~ (m-1)是 NV Block 的 Index 范围,m ~ (m+n-1)是 ROM Block 的 Index 范围。
Read/Write Retry
在 Write 和 WriteAll 请求执行过程中,若对某个 Block 的写入失败,且该 Block 配置的写重试次数不为 0,则 NVM 会再次尝试对该 Block 进行写入,直到尝试次数超过用户配置的Retry次数阈值。
&emsp在 Read 和 ReadAll 请求执行过程中,若对某个 Block 的读取失败,且该 Block 配置的读重试次数不为 0,则 NVM 会再次尝试对该 Block 进行读取,直到尝试次数超过用户配置的Retry次数阈值。
NvM_GetErrorStatus
NvM_GetErrorStatus是一个经常被使用到的函数,通过调用这个函数可以获取当去NvM模块的当前状态,具体如下:
| 请求结果 | 描述 |
|---|---|
| NVM_REQ_OK | 默认状态,上一次工作成功完成。 |
| NVM_REQ_NOT_OK | 1. 任意请求中,调用下层 MemIf 接口返回 E_NOT_OK,或下层请求结果为 MEMIF_JOB_FAILED。 2. 在 WriteAll 和 ReadAll 中,如果有任意一个 Block 的执行结果不是非错误结 果 之 一 , 则 WriteAll 和 ReadAll 的 结 果 为NVM_REQ_NOT_OK。 3. 对于使能了同步镜像机制的 Block,如果调用同步回调函数返回E_NOT_OK , 且 错 误 次 数 超 过 限 制 , 则 也 会 上 报 该NVM_REQ_NOT_OK。 |
| NVM_REQ_PENDING | 工作处于队列中,或正在执行。 |
| NVM_REQ_INTEGRITY_FAILED | Read 或 ReadAll 中,检测到下述情况,且无隐性恢复默认数据: 1. CRC 校验失败; 2. 下层请求结果为 MEMIF_BLOCK_INCONSISTENT |
| NVM_REQ_BLOCK_SKIPPED | 在 ReadAll 或 WriteAll 或 ValidateAll 中,该 Block 被跳过。 |
| NVM_REQ_NV_INVALIDATED | Read 或 ReadAll 中,下层请求结果为 MEMIF_BLOCK_INVALID。如果读取冗余 Block,该结果表明两个 NV Block 读取的结果均为MEMIF_BLOCK_INVALID。 |
| NVM_REQ_CANCELLED | 1. 调用 NvM_CancelJobs 被取消的 Block; 2. 调用 NvM_CancelWriteAll 被取消的 Block; 3. 任意请求执行过程中 , 下层请求结果为NVM_REQ_CANCELLED. |
| NVM_REQ_REDUNDANCY_FAILED | 未使用。 |
| NVM_REQ_RESTORED_FROM_ROM | Block 恢复了默认数据,包括隐性和显性恢复。 |
| NVM_REQ_BUSYING | 未使用。 |
| NVM_REQ_WRONGID | Read 或 ReadAll 中,BlockID 检查失败,且无隐性恢复默认数据。 |
| NVM_REQ_MIRROR_OP_FAILED | 未使用。 |
| NVM_REQ_VERIFY_FAILED | Write 或 WriteAll 中,数据回读校验失败。 |
| NVM_REQ_CFGID_MISMATCH | 未使用。 |
与BswM模块的交互
在前面介绍BswM模块中提到了,BSW层模块可以给BswM模块发送Mode Request和Mode Indication,而NvM模块则可以在下面情况下去给BswM模块发送Mode Indication:
- 当 SingleJob 进入队列时,调用 BswM_NvM_CurrentBlockMode(Pending);
- 当 SingleJob 工作结束时,调用 BswM_NvM_CurrentBlockMode,状态由本次工作的结果决定;
- 当 SingleJob 工作被取消时,调用 BswM_NvM_CurrentBlockMode(Cancel);
- 当 MultiJob 进入队列时,调用 BswM_NvM_CurrentJobMode(Pending);
- 当 MultiJob 工作结束时,调用 BswM_NvM_CurrentJobMode,状态由本次工作的结果决定;
- 当 WriteAll 工作被取消时,调用 BswM_NvM_CurrentJobMode(Cancel)。
MemIf模块
上面提到了一个NvM模块Block会对应一个或者多个Fee和Ea模块Block,而MemIf模块就是将这两种位于不同层的Block对应起来,即实现Block Handle和Block ID的对应关系。在这里就不多做介绍了,非常简单。
代码部分
代码分成三个部分:
- Tp
- Dcm
- Dem
TP

