校验
校验和 (Checksum)
参考链接
CheckSum算法–又名累加和校验算法 - 皮卡成球 - 博客园
原理及步骤
**校验和(Checksum)**是网络协议使用的数据错误检测方法,并且被认为比LRC(纵向冗余校验,Longitudinal Redundancy Check,LRC),VRC和CRC(循环冗余校验(Cyclic Redundancy Codes,CRC))更可靠。此方法在发送方使用校验和生成器,在接收方使用校验和校验器。
累加和校验算法的实现
发送方:对要数据累加,得到一个数据和,对和求反,即得到我们的校验值。然后把要发的数据和这个校验值一起发送给接收方。
接受方:对接收的数据(包括校验和)进行累加,然后加1,如果得到0,那么说明数据没有出现传输错误。注意,此处发送方和接收方用于保存累加结果的类型一定要一致,否则加1就无法实现溢出从而无法得到0,校验就会无效。
步骤:
- 校验数据以16bit为单位进行累加求和,校验数据需为偶字节数(不然无法以16bit为累加单位),奇字节数末尾填充0变为偶字节数;
- 累加和超过16bit,产生进位,将进位当作高16bit,其他数为低16bit,进行相加;
- 循环步骤2,直到没有进位产生为止,得到sum值
- 累加和取反得到校验和,即checksum值,存入数据的checksum字段即可。
[!important]
CheckSum取反主要原理是:
==原码+反码+1 = 0==
栗子
八位保存累加和:
需要发送数据(8bit 2进制): 10101001 00111001 00001010
奇字节补0:10101001 00111001 00001010 0000000010101001 + 00111001 + 00001010 + 00000000 = 11101100(sum值)~11101100 = 00010011(checksum值)- 所以发送的数据就是: 10101001 00111001 00001010 00010011
- 接收方接收到的数据是: 10101001 00111001 00001010 00010011
10101001 + 00111001 + 00001010 + 00010011 = 11111111(sum值)~11111111 = 00000000(结果是0,校验完成,没有错误)
十六位保存累加和:
需要发送的数据(16bit 16进制): 1234 003c 1c46 4000 4006 ‘checksum’ ac00 0a63 ac10 0a0c
根据原始数据计算出checksum(至于checksum段的位置,我想可能是自定义的,在哪都不影响), 才是发送出去的完成数据
先将checksum段置0,1234 003c 1c46 4000 4006 0000 ac00 0a63 ac10 0a0csum = 1234 + 003c + 1c46 + 4000 + 4006 + 0000 + ac00 + 0a63 + ac10 + 0a0c = 21b3b (进位加到低16bit末尾)checksum = ~1b3d = e4c2(即checksum值)- 所以发送方发送的数据为:1234 003c 1c46 4000 4006 e4c2 ac00 0a63 ac10 0a0c(补全 cehcksum字段)
sum = 1234 + 003c + 1c46 + 4000 + 4006 + e4c2 + ac00 + 0a63 + ac10 + 0a0c = 2fffd(再回加)checksum = ~ffff=0000- 接收方checksum=0,校验成功
示例代码:
1 | uint8_t TX_CheckSum(uint8_t *buf, uint8_t len) //buf为数组,len为数组长度 |
循环冗余校验 (CRC)
参考链接
什么是CRC(Cyclic Redundancy Check)?如何解决CRC错误? - 华为 (huawei.com)
循环冗余校验 - 维基百科,自由的百科全书 (wikipedia.org)
简介
循环冗余校验CRC(Cyclic Redundancy Check)是数据通信领域常用的一种数据传输检错技术。通过在发送端对数据按照某种算法计算出校验码,并将得到的校验码附在数据帧的后面,一起发送到接收端。接收端对收到的数据和校验码按照相同算法进行验证,以此判断接收到的数据是否正确、完整。
原理
CRC的思想就是先在要发送的K比特长度的数据后面附加一个R比特长度的校验码,然后生成一个新帧发送给接收端。接收端接收到新帧后,根据收到的数据和校验码来验证接收到的数据是否正确。
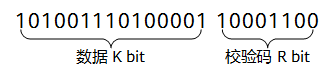
当然,==这个附加的校验码不是随意添加的==,要使所生成的新帧能与发送端和接收端共同选定的某个特定数整除(“模2除法”)。接收端把接收到的新帧除以这个选定的除数。因为在发送数据帧之前就已通过附加一个数,做了“去余”处理(也就已经能整除了),所以结果应该是没有余数。如果有余数,则表明该帧在传输过程中出现了差错。
[!important]
原始数据 + 余数 = 2的倍数
所以说如果接收到的数据对2取余不为0,说明传输有问题
在K比特数据后面再拼接R比特的校验码,整个编码长度为N比特,这种编码也叫==(N,K)码==。对于一个给定的(N,K)码,可以证明存在一个最高次幂为N-K=R的多项式g(x),根据g(x)可以生成R比特的校验码。其算法是以GF(2)多项式算术为数学基础的。
[!TIP]
CRC 是一种基于多项式的错误检测方法。数据被视为一个多项式,通过特定的生成多项式进行除法运算,余数即为 CRC 值。
==也就是说除数是一个多项式的系数组成的数值,将原始数据(被除数)+ 余数 = 多项式系数的倍数==
CRC是基于有限域GF(2)(即除以2的同余)的多项式环。简单的来说,就是所有系数都为0或1(又叫做二进制)的多项式系数的集合,并且集合对于所有的代数操作都是封闭的。例如:
$$
{\displaystyle (x^{3}+x)+(x+1)=x^{3}+2x+1\equiv x^{3}+1}
$$
2会变成0,因为对系数的加法运算都会再取2的模数。乘法也是类似的:
$$
{\displaystyle (x^{2}+x)(x+1)=x^{3}+2x^{2}+x\equiv x^{3}+x}
$$
同样可以对多项式作除法并且得到商和余数。例如,如果用$x^3 + x^2 + x$除以$x + 1$。会得到:
$$
{\displaystyle {\frac {(x^{3}+x^{2}+x)}{(x+1)}}=(x^{2}+1)-{\frac {1}{(x+1)}}}
$$
也就是说:
$$
{\displaystyle (x^{3}+x^{2}+x)=(x^{2}+1)(x+1)-1}
$$
等价于:
$$
{\displaystyle (x^{2}+x+1)x=(x^{2}+1)(x+1)-1}
$$
这里除法得到了商$x^2 + 1$和余数-1,因为是奇数所以最后一位是1。字符串中的每一位其实就对应了这样类型的多项式的系数。为了得到CRC,首先将其乘以$x^n$,这里$n$是一个固定多项式的**阶数**,然后再将其除以这个固定的多项式,余数的系数就是CRC。
在上面的等式中,$x^2+x+1$表示了本来的信息位是
111, $x+1$是所谓的钥匙,而余数1(也就是$x^0$)就是CRC,key的最高次为1,所以将原来的信息乘上$x^1$来得到$x^3+x^2+x$,也可视为原来的信息位补1个零成为1110。一般来说,其形式为:
$$
{\displaystyle M(x)\cdot x^{n}=Q(x)\cdot K(x)-R(x)}
$$
这里M(x)是原始的信息多项式。K(x)是$n$阶的“钥匙”多项式。$𝑀(𝑥)⋅𝑥^𝑛$表示了将原始信息后面加上$n$个0。$R(x)$是余数多项式,即是==CRC“校验和”==。在通信中,发送者在原始的信息数据$M$后附加上$𝑛$位的$R$(替换本来附加的0)再发送。接收者收到M和R后,检查$𝑀(𝑥)⋅𝑥^𝑛+𝑅(𝑥)$是否能被$𝐾(𝑥)$整除。如果是,那么接收者认为该信息是正确的。值得注意的是$𝑀(𝑥)⋅𝑥^𝑛+𝑅(𝑥)$就是发送者所想要发送的数据。这个串又叫做codeword.
| 名称 | 多项式 | 表示法:正常或者翻转 |
|---|---|---|
| CRC-1 | ${\displaystyle x+1}$(用途:硬件,也称为奇偶校验位) | 0x1 or 0x1 (0x1) |
| CRC-5-CCITT | ${\displaystyle x^{5}+x^{3}+x+1}$(ITU G.704标准) | 0xB(0x??) |
| CRC-5-USB | ${\displaystyle x^{5}+x^{2}+1}$(用途:USB信令包) | 0x5 or 0x14 (0x9) |
| CRC-7 | ${\displaystyle x^{7}+x^{3}+1}$(用途:通信系统) | 0x9 or 0x48 (0x11) |
| CRC-8-ATM | ${\displaystyle x^{8}+x^{2}+x+1}$(用途:ATM HEC, PMBUS (参见SMBUS org[1] (页面存档备份,存于互联网档案馆))) | 0x7或0xE0 (0xC1) |
| CRC-8-CCITT | ${\displaystyle x^{8}+x^{7}+x^{3}+x^{2}+1}$(用途:1-Wire 总线) | 0x8D |
| CRC-8-Dallas/Maxim | ${\displaystyle x^{8}+x^{5}+x^{4}+1}$(用途:1-Wire bus) | 0x31或0x8C |
| CRC-8 | ${\displaystyle x^{8}+x^{7}+x^{6}+x^{4}+x^{2}+1}$ | 0xD5(0x??) |
| CRC-10 | ${\displaystyle x^{10}+x^{9}+x^{5}+x^{4}+x+1}$ | 0x233(0x???) |
| CRC-12 | ${\displaystyle x^{12}+x^{11}+x^{3}+x^{2}+x+1}$(用途:通信系统) | 0x80F或0xF01 (0xE03) |
| CRC-16-Fletcher | 参见Fletcher’s checksum | 用于Adler-32 A & B CRC |
| CRC-16-CCITT | ${\displaystyle x^{16}+x^{12}+x^{5}+1}$(X25, V.41, Bluetooth, PPP, IrDA) | 0x1021或0x8408 (0x0811) |
| CRC-16-IBM | ${\displaystyle x^{16}+x^{15}+x^{2}+1}$(用途:Modbus) | 0x8005或0xA001 (0x4003) |
| CRC-16-BBS | ${\displaystyle x^{16}+x^{15}+x^{10}+x^{3}}+1$(用途:XMODEM协议) | 0x8408(0x???) |
| CRC-32-Adler | 参见Adler-32 | 参见Adler-32 |
| CRC-32-MPEG2 | 参见IEEE 802.3 | 参见IEEE 802.3 |
| CRC-32-IEEE 802.3 | ${\displaystyle x^{32}+x^{26}+x^{23}+x^{22}+x^{16}+x^{12}+x^{11}+x^{10}+x^{8}+x^{7}+x^{5}+x^{4}+x^{2}+x+1}$ | 0x04C11DB7或0xEDB88320 (0xDB710641) |
| CRC-32C(Castagnoli) | ${\displaystyle x^{32}+x^{28}+x^{27}+x^{26}+x^{25}+x^{23}+x^{22}+x^{20}+x^{19}+x^{18}+x^{14}+x^{13}+x^{11}+x^{10}+x^{9}+x^{8}+x^{6}+1}$ | 0x1EDC6F41或0x82F63B78 (0x05EC76F1) |
| CRC-64-ISO | ${\displaystyle x^{64}+x^{4}+x^{3}+x+1}$ (用途: ISO 3309) | 0x000000000000001B或0xD800000000000000 (0xB000000000000001) |
| CRC-64-ECMA-182 | ${\displaystyle x^{64}+x^{62}+x^{57}+x^{55}+x^{54}+x^{53}+x^{52}+x^{47}+x^{46}+x^{45}+x^{40}+x^{39}+x^{38}+x^{37}+x^{35}+x^{33}+x^{32}}+$ ${\displaystyle +x^{31}+x^{29}+x^{27}+x^{24}+x^{23}+x^{22}+x^{21}+x^{19}+x^{17}+x^{13}+x^{12}+x^{10}+x^{9}+x^{7}+x^{4}+x+1}$(参见ECMA-182 (页面存档备份,存于互联网档案馆) p.63) | 0x42F0E1EBA9EA3693或0xC96C5795D7870F42 (0x92D8AF2BAF0E1E85) |
| CRC-128 | IEEE-ITU标准。被MD5 & SHA-1取代 | |
| CRC-160 | IEEE-ITU标准。被MD5 & SHA-1取代 |
这些多项式的值便是==模2除法的除数==。而根据这个除数获得校验码并进行校验的原理可以分为以下几个步骤:
- 发送端、接收端在通信前,约定好除数P,也就是前面说的多项式的值。P应该是R+1位长度;
- 发送端首先在原来的K位数据后面加R个0,相当于原来的数据左移了R位;
- 然后进行模2除法运算(其实就是异或XOR运算),将加0之后的K+R位的数除以P,循环计算,直到余数的阶数小于R,这个余数就是附加的校验码,如果长度不足R位需要在前面加0补齐;
- 发送端将R位校验码附加在原数据后面发送给接收方;
- 接收方接收到数据后,将数据以模2除法方式除以除数P。如果没有余数,说明在传输过程中没有出现错误,否则说明有错误。
栗子
以g(x)为$CRC-4=x^{4}+x+1$为例,此时除数P=10011。假设源数据M为10110011。
在发送端将M左移4位,然后除以P。
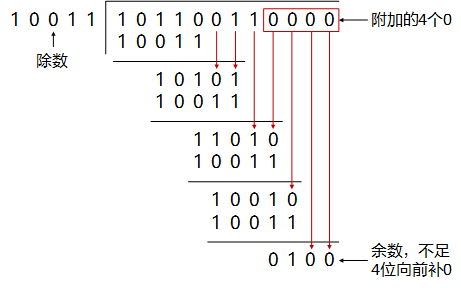
==计算得到的余数就是0100,也就是CRC校验码==。将0100附加到原始数据帧10110011后,组成新帧101100110100发送给接收端。接收端接收到该帧后,会用该帧去除以上面选定的除数P,验证余数是否为0,如果为0,则表示数据在传输过程中没有出现差错。
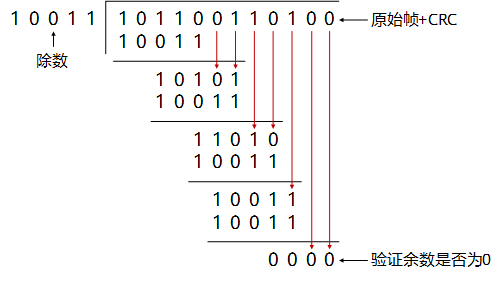
示例代码:
1 |
|
[!IMPORTANT]
异或操作:
当对一个数据进行两次异或时就可以得到数据本身
哈希校验 (Hash Check)
参考链接
【数据加解密】MD5检验算法的原理及实现_md5校验原理-CSDN博客
SHA-2 - 维基百科,自由的百科全书 (wikipedia.org)
MD5摘要算法
我们首先假设有一个 b 个bit的数据作为输入,然后我们希望根据某种规则计算出它的信息摘要。这里b是任意大小的数据,也不需要是8bit的倍数。 我们假设数据的字节如下:
1 | m_0 m_1 … m_{b-1} |
现在要生成MD5码要经过以下步骤:
-
填充位
输入数据首先被"填充"(拓展),以保证它的长度%512 = 448。 在信息的后面填充一个1和无数个0,直到满足上面的条件时才停止用0对信息的填充。
-
追加消息长度信息
追加一个64位的数据,该数据表示b的长度(步骤1填充之后的),如果b的长度大于$2^{64}$,那么只使用该长度值二进制表示的低64位(比如如果长度是0x82a89c7434,则只使用0xa89c7434)。
追加长度信息后,此时数据的长度是 512的倍数,并且也是16的倍数。经过这两步的处理,信息的位长=N * 512+448+64=(N+1)*512,即长度恰好是512的整数倍。这样做的原因是为满足后面处理中对信息长度的要求。
-
初始化MD buffer
创建一个128位的 buffer (A、B、C、D)用于计算消息摘要。这里的A、B、C、D都是32位寄存器。这些寄存器初始化为以下十六进制低阶字节的值
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
在程序中表示为1
2
3
4var int h0 := 0x67452301
var int h1 := 0xEFCDAB89
var int h2 := 0x98BADCFE
var int h3 := 0x10325476 -
处理分组数据
将步骤2处理完的数据的一包(512bit)数据划分为16组,每组数据为32位($32 \times 16 = 512$),处理过程如下:
- 主循环有四轮(MD4只有三轮),每轮循环执行16次非线性函数(循环16次遍历完成一包数据)。
- 每次操作对a、b、c和d中的其中三个作一次非线性函数运算,然后将所得结果加上第四个变量,再加上划分好的一组数据和一个常数。最后将所得结果向左循环左移一个不定的数,并加上a、b、c或d中之一。最后用该结果取代a、b、c或d中之一。
以下是每次操作中用到的四个非线性函数(每轮一个)
**F(X,Y,Z) **= ( X & Y ) | ( ( ~X ) & Z )
G(X,Y,Z) = ( X & Z ) | ( Y & ( ~Z ) )
**H(X,Y,Z) **= X^ Y ^ Z
**I(X,Y,Z) **= Y^( X | ( ~Z ) )[!tip]
其中,&是与(And),|是或(Or),~是非(Not),^是异或(Xor
如果X、Y和Z的对应位是独立和均匀的,那么结果的每一位也应是独立和均匀的。
F是一个逐位运算的函数。即,如果X,那么Y,否则Z。函数H是逐位奇偶操作符。
假设M[j]表示加密数据的第j组(从0到15),常数$ti$是$4294967296*abs( sin(i))$的整数部分,i 取值从1到64,单位是弧度。($4294967296=2^{32}$)
现定义
$$
FF(a ,b ,c ,d ,Mj ,s ,ti) :操作为 a = b + ( (a + F(b,c,d) + Mj + ti) << s)\
GG(a ,b ,c ,d ,Mj ,s ,ti) :操作为 a = b + ( (a + G(b,c,d) + Mj + ti) << s)\
HH(a ,b ,c ,d ,Mj ,s ,ti) :操作为 a = b + ( (a + H(b,c,d) + Mj + ti) << s)\
II(a ,b ,c ,d ,Mj ,s ,ti) :操作为 a = b + ( (a + I(b,c,d) + Mj + ti) << s)\
$$[!tip]
需要注意的是:这里的<<是循环左移
那么四轮六十四步开始(一轮十六步):
-
第一轮:
$$
FF(a ,b ,c ,d ,M[0],7 ,0xd76aa478 )\
FF(d ,a ,b ,c ,M[1] ,12 ,0xe8c7b756 )\
FF(c ,d ,a ,b ,M[2] ,17 ,0x242070db )\
FF(b ,c ,d ,a ,M[3] ,22 ,0xc1bdceee )\
FF(a ,b ,c ,d ,M[4] ,7 ,0xf57c0faf )\
FF(d ,a ,b ,c ,M[5] ,12 ,0x4787c62a )\
FF(c ,d ,a ,b ,M[6] ,17 ,0xa8304613 )\
FF(b ,c ,d ,a ,M[7] ,22 ,0xfd469501)\
FF(a ,b ,c ,d ,M[8] ,7 ,0x698098d8 )\
FF(d ,a ,b ,c ,M[9] ,12 ,0x8b44f7af )\
FF(c ,d ,a ,b ,M[10] ,17 ,0xffff5bb1 )\
FF(b ,c ,d ,a ,M[11] ,22 ,0x895cd7be )\
FF(a ,b ,c ,d ,M[12] ,7 ,0x6b901122 )\
FF(d ,a ,b ,c ,M[13] ,12 ,0xfd987193 )\
FF(c ,d ,a ,b ,M[14] ,17 ,0xa679438e )\
FF(b ,c ,d ,a ,M[15] ,22 ,0x49b40821 )\
$$ -
第二轮
$$
GG(a ,b ,c ,d ,M[1] ,5 ,0xf61e2562 )\
GG(c ,d ,a ,b ,M[11] ,14 ,0x265e5a51 )\
GG(b ,c ,d ,a ,M[0] ,20 ,0xe9b6c7aa )\
GG(a ,b ,c ,d ,M[5] ,5 ,0xd62f105d )\
GG(d ,a ,b ,c ,M[10] ,9 ,0x02441453 )\
GG(c ,d ,a ,b ,M[15] ,14 ,0xd8a1e681 )\
GG(b ,c ,d ,a ,M[4] ,20 ,0xe7d3fbc8 )\
GG(a ,b ,c ,d ,M[9] ,5 ,0x21e1cde6 )\
GG(d ,a ,b ,c ,M[14] ,9 ,0xc33707d6 )\
GG(c ,d ,a ,b ,M[3] ,14 ,0xf4d50d87 )\
GG(b ,c ,d ,a ,M[8] ,20 ,0x455a14ed )\
GG(a ,b ,c ,d ,M[13] ,5 ,0xa9e3e905 )\
GG(d ,a ,b ,c ,M[2] ,9 ,0xfcefa3f8 )\
GG(c ,d ,a ,b ,M[7] ,14 ,0x676f02d9 )\
GG(b ,c ,d ,a ,M[12] ,20 ,0x8d2a4c8a )
$$ -
第三轮
$$
HH(a ,b ,c ,d ,M[5] ,4 ,0xfffa3942 )\
HH(d ,a ,b ,c ,M[8] ,11 ,0x8771f681 )\
HH(c ,d ,a ,b ,M[11] ,16 ,0x6d9d6122 )\
HH(b ,c ,d ,a ,M[14] ,23 ,0xfde5380c )\
HH(a ,b ,c ,d ,M[1] ,4 ,0xa4beea44 )\
HH(d ,a ,b ,c ,M[4] ,11 ,0x4bdecfa9 )\
HH(c ,d ,a ,b ,M[7] ,16 ,0xf6bb4b60 )\
HH(b ,c ,d ,a ,M[10] ,23 ,0xbebfbc70 )\
HH(a ,b ,c ,d ,M[13] ,4 ,0x289b7ec6 )\
HH(d ,a ,b ,c ,M[0] ,11 ,0xeaa127fa )\
HH(c ,d ,a ,b ,M[3] ,16 ,0xd4ef3085 )\
HH(b ,c ,d ,a ,M[6] ,23 ,0x04881d05 )\
HH(a ,b ,c ,d ,M[9] ,4 ,0xd9d4d039 )\
HH(d ,a ,b ,c ,M[12] ,11 ,0xe6db99e5 )\
HH(c ,d ,a ,b ,M[15] ,16 ,0x1fa27cf8 )\
HH(b ,c ,d ,a ,M[2] ,23 ,0xc4ac5665 )\
$$ -
第四轮
$$
II(a ,b ,c ,d ,M[0] ,6 ,0xf4292244 )\
II(d ,a ,b ,c ,M[7] ,10 ,0x432aff97 )\
II(c ,d ,a ,b ,M[14] ,15 ,0xab9423a7 )\
II(b ,c ,d ,a ,M[5] ,21 ,0xfc93a039 )\
II(a ,b ,c ,d ,M[12] ,6 ,0x655b59c3 )\
II(d ,a ,b ,c ,M[3] ,10 ,0x8f0ccc92 )\
II(c ,d ,a ,b ,M[10] ,15 ,0xffeff47d )\
II(b ,c ,d ,a ,M[1] ,21 ,0x85845dd1 )\
II(a ,b ,c ,d ,M[8] ,6 ,0x6fa87e4f )\
II(d ,a ,b ,c ,M[15] ,10 ,0xfe2ce6e0 )\
II(c ,d ,a ,b ,M[6] ,15 ,0xa3014314 )\
II(b ,c ,d ,a ,M[13] ,21 ,0x4e0811a1 )\
II(a ,b ,c ,d ,M[4] ,6 ,0xf7537e82 )\
II(d ,a ,b ,c ,M[11] ,10 ,0xbd3af235 )\
II(c ,d ,a ,b ,M[2] ,15 ,0x2ad7d2bb )\
II(b ,c ,d ,a ,M[9] ,21 ,0xeb86d391 )
$$ -
循环过程为:
-
当四轮结束之后,将缓存变量的拷贝和计算结果相加:
$$
A=A+a\
B=B+b\
C=C+c\
D=D+d\
$$
-
最终得到的校验值由ABCD拼成,其中A为最低位,D为最高位
SHA256校验
SHA256是SHA-2下细分出的一种算法,SHA-2,名称来自于安全散列算法2(Secure Hash Algorithm 2)的缩写,一种密码散列函数算法标准,由美国国家安全局研发,属于SHA算法之一,是SHA-1的后继者。
SHA-2下又可再分为六个不同的算法标准:
- SHA-224
- SHA-256
- SHA-384
- SHA-512
- SHA-512/224
- SHA-512/256。
这些变体除了生成摘要的长度 、循环运行的次数等一些微小差异外,算法的基本结构是一致的。
对于任意长度的消息,SHA256都会产生一个256bit长的哈希值,称作消息摘要。这个摘要相当于是个长度为32个字节的数组,通常用一个长度为64的十六进制字符串来表示。
算法主要包括了:
- 常量的初始化
- 信息的预处理
- 逻辑运算
常量初始化
SHA256算法中用到了8个哈希初值以及64个哈希常量
其中,SHA256算法的8个哈希初值如下:
1 | h0 := 0x6a09e667 |
这些初值是对自然数中前8个质数(2,3,5,7,11,13,17,19)的平方根的小数部分取前32bit而来
举个例子来说,$ \sqrt{2} $小数部分约为0.414213562373095048,而$0.414213562373095048 ≈ 6 ∗ 16^{-1} + a ∗ 16 ^ {-2} + 0 ∗ 16^{-3} + …$
于是,质数2的平方根的小数部分取前32bit就对应出了0x6a09e667
在SHA256算法中,用到的64个常量如下:
1 | 428a2f98 71374491 b5c0fbcf e9b5dba5 |
和8个哈希初值类似,这些常量是对自然数中前64个质数(2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97…)的立方根的小数部分取前32bit而来。
信息预处理
SHA256算法中的预处理就是在想要Hash的消息后面补充需要的信息,使整个消息满足指定的结构。
信息的预处理分为两个步骤:附加填充比特和附加长度
-
附加填充比特
==在报文末尾进行填充,使报文长度在对512取模以后的余数是448。==
填充是这样进行的:先补第一个比特为1,然后都补0,直到长度满足对512取模后余数是448。
需要注意的是,信息必须进行填充,也就是说,即使长度已经满足对512取模后余数是448,补位也必须要进行,这时要填充512个比特。
因此,填充是至少补一位,最多补512位。
例:以信息“abc”为例显示补位的过程。
a,b,c对应的ASCII码分别是97,98,99
于是原始信息的二进制编码为:01100001 01100010 01100011
补位第一步,首先补一个“1” : 0110000101100010 01100011 1
补位第二步,补423个“0”:01100001 01100010 01100011 10000000 00000000 … 00000000
补位完成后的数据如下(为了简洁用16进制表示):
1
2
3
461626380 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000为什么是448?
因为在第一步的预处理后,第二步会再附加上一个64bit的数据,用来表示原始报文的长度信息。而448+64=512,正好拼成了一个完整的结构。
-
附加长度值
附加长度值就是将原始数据(第一步填充前的消息)的长度信息补到已经进行了填充操作的消息后面。
SHA256用一个64位的数据来表示原始消息的长度。因此,通过SHA256计算的消息长度必须要小于$ 2^{64} $,当然绝大多数情况这足够大了。
回到刚刚的例子,消息“abc”,3个字符,占用24个bit
因此,在进行了补长度的操作以后,整个消息就变成下面这样了(16进制格式)
1
2
3
461626380 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000018
逻辑运算
SHA256散列函数中涉及的操作全部是逻辑的位运算:
$$
Ch(x,y,z)=(x∧y)⊕(¬x∧z)\
Ma(x,y,z)=(x∧y)⊕(x∧z)⊕(y∧z)\
Σ_0(x)=S^2 (x)⊕S^{13}(x)⊕S^{22}(x)\
Σ_1 (x)=S^6(x)⊕S^{11}(x)⊕S^{25}(x)\
σ_0(x)=S^{7}(x)⊕S^{18}(x)⊕R^{3}(x)\
σ_1(x)=S^{17}(x)⊕S^{19}(x)⊕R^{10}(x)
$$
其中:
| 逻辑运算 | 含义 |
|---|---|
| ^ | 按位"与" |
| ¬ | 按位“补” |
| ⊕ | 按位“异或” |
| $S^{n}$ | 循环右移n个bit |
| $R^{n}$ | 右移n个bit |
开始计算
-
首先将消息分解为512-bit大小的块

假设消息M可以被分解为n个块,于是整个算法需要做的就是完成n次迭代,n次迭代的结果就是最终的哈希值,即256bit的数字摘要。
一个256-bit的摘要的初始值H0,经过第一个数据块进行运算,得到H1,即完成了第一次迭代,H1经过第二个数据块得到H2,……,依次处理,最后得到Hn,Hn即为最终的256-bit消息摘要。
将每次迭代进行的映射用$ Map(H_{i-1}) = H_{i} $表示,于是迭代可以更形象的展示为:

图中256-bit的
Hi被描述8个小块,这是因为SHA256算法中的最小运算单元称为“字”(Word),一个字是32位。此外,第一次迭代中,映射的初值设置为前面介绍的8个哈希初值,如下图所示:

-
构造64个字(word)
对于每一块,将块分解为16个32-bit的字,记为w[0], …, w[15]
也就是说,前16个字直接由消息的第i个块分解得到
其余的字由如下迭代公式得到:
$$
W_t =σ_1(W_{t−2})+W_{t−7}+σ_0(W_{t−15})+W_{t−16}
$$ -
进行64次循环
映射 $ Map(H_{i-1}) = H_{i} $ 包含了64次加密循环,即进行64次加密循环即可完成一次迭代,
每次加密循环可以由下图描述:

图中,ABCDEFGH这8个字(word)在按照一定的规则进行更新,其中深蓝色方块是事先定义好的非线性逻辑函数,上文已经做过铺垫
红色田字方块代表 mod $ 2^{32} $ addition,即将两个数字加在一起,如果结果大于$ 2^{32}$,你必须除以 $2^{32} $并找到余数。
ABCDEFGH一开始的初始值分别为$ H_{i-1}(0),H_{i-1}(1),…,H_{i-1}(7) $
Kt是第t个密钥,对应我们上文提到的64个常量
Wt是本区块产生第t个word。原消息被切成固定长度512-bit的区块,对每一个区块,产生64个word,通过重复运行循环n次对ABCDEFGH这八个字循环加密。
最后一次循环所产生的八个字合起来即是第i个块对应到的散列字符串$ H_{i} $
奇偶校验 (Parity Check)
参考链接
基本原理
奇偶校验通过在数据末尾添加一个位,确保数据传输的正确性。奇偶校验分为奇校验和偶校验两种。奇偶校验通过设置规则来检查一组给定的位中1的数量。如果采用奇校验,每个数据单元中1的总数必须是奇数;如果采用偶校验,总数必须是偶数。
- 奇校验:如果数据单元中1的数量已经是奇数,则校验位设置为0;否则,校验位设置为1。
- 偶校验:如果数据单元中1的数量已经是偶数,则校验位设置为0;否则,校验位设置为1。
[!important]
计算机通过对所有信息位进行异或操作来实现求偶校验位和进行偶校验。这种方法简单有效,但只能检测到单个比特错误,无法检测多位错误。
原理:奇偶校验通过计算数据中1的数量来判断数据是否被篡改。根据约定,可以是奇数校验或偶数校验。
奇偶校验在同步与异步传输中的应用
同步传输常用奇校验,而异步传输常用偶校验。这是因为同步传输中,全0数据采用奇校验时至少会有1个1,便于判断是否有传送发生;异步传输中,由于有停止位,采用偶校验时接收方也至少能收到1个1。
奇偶校验电路实现:
- 偶校验位的产生:通过对待发送的数据依次做异或运算即可得到。
- 奇校验位的产生:在偶校验电路的输出取非,产生奇校验位的代价高,速度相对慢。
栗子
偶校验
在偶校验中,校验位被设置为使得整个数据块(包括校验位)的1的个数为偶数。
- 原数据:
1010001 - 1的个数:
3(奇数) - 校验位:
1(使得1的总个数变为偶数) - 校验后的数据:
10100011
奇校验
在奇校验中,校验位被设置为使得整个数据块(包括校验位)的1的个数为奇数。
- 原数据:
1010001 - 1的个数:
3(奇数) - 校验位:
0(保持1的总个数为奇数) - 校验后的数据:
10100010
校验过程
- 发送方:在数据末尾添加校验位,形成校验单元后发送。
- 接收方:重新计算校验位,并与接收到的校验位比对。如果相同,则数据传输正确;如果不同,则数据传输过程中出现错误。
类型:
- 单比特奇偶校验:针对单个数据单元(如字节)进行校验,能检测单个比特的错误。
- 两维奇偶校验:在数据块的每行和每列都进行奇偶校验,能提供更强的错误检测能力。
1 |
|
纵向冗余校验(Longitudinal Redundancy Check,LRC)
参考链接
常用算法 之五 数据校验(CRC 原理、LRC、奇偶校验、校验和)详解_lrc校验-CSDN博客
基本原理
纵向冗余校验(LRC)是一种用于检测数据传输错误的常用方法,特别是在工业通信协议如Modbus ASCII模式中应用广泛。LRC的基本原理是通过对数据帧中的每个字节进行异或运算来生成一个校验字节,从而确保数据的完整性。
LRC的计算步骤如下:
- 数据处理:将需要校验的数据按字节排列,忽略起始和结束字符(如冒号和回车换行符)。
- 异或运算:对所有字节进行异或运算。
- 结果应用:将计算出的LRC值附加到数据帧的末尾,发送方和接收方都会计算LRC值并进行比较,如果两个值不相等,则表示数据传输过程中存在错误。
LRC的主要优点在于其简单性和快速性,适用于小数据块的错误检测。然而,它也有明显的缺点,例如无法检测到偶数个位同时出错的情况。此外,LRC对突发错误的检测能力较弱,这意味着在某些情况下可能无法准确识别错误。
LRC校验广泛应用于工业通信协议中,如Modbus协议的ASCII模式,以及一些射频识别系统中。在这些场景中,由于标签容量有限,LRC因其简单高效而成为一种理想的选择。

栗子
1 |
|